鸿源韬生物
RIP-Seq生信分析报告
1.项目简介
1.1 样本信息
合同编号
RS20250611
实验技术
RIP-Seq
物种名称
小鼠
拉丁名
Mus musculus
参考基因组
mm39
报告生成日期
2025年06月26日
客户送样名称
测序文库名称
分组
WT_IP_rep1
WT_IP_rep1
WT
WT_IP_rep2
WT_IP_rep2
WT
WT_INPUT_rep1
WT_INPUT_rep1
WT
WT_INPUT_rep2
WT_INPUT_rep2
WT
Setd2_KO_IP_rep1
Setd2_KO_IP_rep1
Setd2_KO
Setd2_KO_IP_rep2
Setd2_KO_IP_rep2
Setd2_KO
Setd2_KO_INPUT_rep1
Setd2_KO_INPUT_rep1
Setd2_KO
Setd2_KO_INPUT_rep2
Setd2_KO_INPUT_rep2
Setd2_KO
1.2 实验原理及流程
转录水平对于真核生物基因表达至关重要,但mRNA水平并不总是与蛋白质的水平直接相关,这种差异的部分原因是mRNA的转录后调控。转录后调控的关键是RNA结合蛋白(RNA-binding protein, RBP)及其相关mRNA靶标的相互作用,RBP通过与mRNA靶标形成核糖核蛋白(Ribonucleoprotein, RNP)复合体来影响mRNA的定位、修饰、稳定性和翻译水平(Tenenbaum SA et al., 2000)。研究发现,随着原核生物向真核生物的进化和核膜的发育,RBP的数量显著增加,转录后的基因表达研究往往集中于RBP。从RNP的复合物中识别这些未知的mRNA靶标对于理解RBP的机制和功能及其对蛋白质表达水平的影响至关重要。
RNA免疫共沉淀高通量测序(RNA Immunoprecipititation and high-throughput sequencing,RIP-Seq)是一种用于分析蛋白质与RNA交互作用的研究方法。RIP利用目标蛋白的抗体将相应的RNA-蛋白复合物(RBP)沉淀下来,分离纯化捕获的RNA,结合高通量测序技术对目标RNA进行测序分析。RNA的功能远不止转录和后续的翻译。例如,RNA-蛋白质相互作用能够调控mRNA和非编码RNA的功能。对RNA潜能的这一新认识带动了新方法的发展,使研究人员能够定位 RNA-蛋白质相互作用。RIP是一种研究单个蛋白质和RNA分子间物理结合的实验方案(Zhao J et al., 2010)。
1.3 实验流程
RIP-Seq 实验原理(Zhao J et al., 2010)
1.4 分析流程
获得测序原始数据(raw data)后,首先对原始数据进行过滤,获得高质量的测序数据(clean data),将测序数据(clean data)比对到项目物种的参考基因组上,对比对结果进行鉴定峰位点(peak calling)。理想情况下,通过RIP对目的蛋白结合的RNA进行富集后,目的蛋白结合的RNA或者目的蛋白在RNA上的结合区域,在对应的参考基因组位置上,测序reads的覆盖度会显著升高,相对其他非结合区域形成明显的“peak”。对peak关联基因进行注释以及富集分析, 在有生物学重复时进行差异Peak、共识Peak分析。
2. 数据质控
我们交付的原始数据为fastq(简称fq)格式文件的压缩包,文件名后缀通常为 “.fq.gz”。交付数据前我们会计算每个压缩文件的md5值。在您拿到数据之后,请您先校>验每个压缩文件的md5值,Linux下可以在数据目录使用“md5sum -c <*md5.txt>”命令进行校验,Windows下可使用hashmyfiles等校验工具,如发现压缩文件md5值与附在数据文件目录下的md5文档中的不一致则说明文件可能在传输的过程中被损坏。数据文件大小为文件占用磁盘空间的大小,文件的大小通常与磁盘格式、压缩比例等因素有关,与测序数据量(碱基数)的多少无对应关系,因此对应PE测序的 read1和read2两个文件大小也可能不相同。
将高通量测序得到的原始图像数据经过Base Calling 转化为序列数据,即FASTQ格式,得到最原始的测序数据文件。FASTQ 格式文件可记录所测读段(read)的碱基及其质量分数。FASTQ 格式以测序读段为单位进行存储,每条读段占 4 行,第一行是序列标识(read ID)以及相关的描述信息,以“@” 开头;第二行即为碱基序列,长度由测序策略决定;第三行以“+”开头,后面是序列标示符、描述信息,或者什么也不加;
第四行是测序质量值(phred),与第二行一一对应,phred值以ASCII码标记,对应的 ASCII 值减去33,即为第二行对应碱基的测序质量值,示例如下:
@HWI-ST1276:71:C1162ACXX:1:1101:1208:2458 1:N:0:CGATGT
测序错误率用e表示, 平台测得数据的碱基质量值用Qphred表示,则有:Qphred=-10log10(e)。软件中碱基识别正确率与Phred分值之间的简明对应关系见下表:
Phred分值 不正确的碱基识别 碱基正确识别率 Q-score 10 1/10 90% Q10 20 1/100 99% Q20 30 1/1000 99.9% Q30
测序Reads的错误率往往会随着测序接近尾声而升高,这是由测序过程中化学试剂的消耗造成共有的特征。
2.1 原始数据质控
RIP-Seq实验基于第二代测序(NGS)平台完成,采用双端测序文库构建策略(插入片段~300 bp)。我们需要对原始测序数据进行质量评估与过滤,以确保后续分析的可靠性。首先,我们使用FastQC(version 0.12.1)(Andrews, 2010)对原始测序数据(raw data)进行全局质量分析,包括碱基质量分布(Phred score)、碱基组成平衡性(base content uniformity)、重复序列比例(duplication level)及GC含量偏差等指标,以全面评估测序质量。result/1.qc文件夹 ,raw为原始数据质控结果,clean为过滤后质控结果。
Setd2-KO_rep1_INPUT.R1 Setd2-KO_rep1_INPUT.R2 Setd2-KO_rep1_IP.R1 Setd2-KO_rep1_IP.R2 Setd2-KO_rep2_INPUT.R1 Setd2-KO_rep2_INPUT.R2 Setd2-KO_rep2_IP.R1 Setd2-KO_rep2_IP.R2 WT_rep1_INPUT.R1 WT_rep1_INPUT.R2 WT_rep1_IP.R1 WT_rep1_IP.R2 WT_rep2_INPUT.R1 WT_rep2_INPUT.R2 WT_rep2_IP.R1 WT_rep2_IP.R2
图2.1 各个样本平均测序碱基质量分数,横坐标代表150 bp长度序列中各个位置,纵坐标为该位置平均的碱基质量值Q;盒形图中间的红线表示中位数(median value);黄色部分代表四分位距(25-75%);上下分割线代表 90%和 10%的上下临界值;蓝色的线代表碱基质量的平均值。
Setd2-KO_rep1_INPUT.R1 Setd2-KO_rep1_INPUT.R2 Setd2-KO_rep1_IP.R1 Setd2-KO_rep1_IP.R2 Setd2-KO_rep2_INPUT.R1 Setd2-KO_rep2_INPUT.R2 Setd2-KO_rep2_IP.R1 Setd2-KO_rep2_IP.R2 WT_rep1_INPUT.R1 WT_rep1_INPUT.R2 WT_rep1_IP.R1 WT_rep1_IP.R2 WT_rep2_INPUT.R1 WT_rep2_INPUT.R2 WT_rep2_IP.R1 WT_rep2_IP.R2
图2.2 各个样本碱基平衡性,图中四条线代表A T C G在每个位置平均含量。理论上,A和T应该相等,G和C应该相等,且4种碱基平行且接近分布。正常情况下四种碱基的出现频率应该是接近的,而且没有位置差异。因此好的样本中四条线应该平行且接近。当部分位置碱基的比例出现 bias 时,即四条线波动较大时可能存在测序数据或者文库污染。如果所有位置的碱基比例一致的表现出bias 时,即四条线平行但分开,往往代表文库有 bias (建库过程或本身特点),或者是测序中的系统误差。测序刚开始由于测序仪状态不稳定,在15bp之前很可能出现波动。
Setd2-KO_rep1_INPUT.R1 Setd2-KO_rep1_INPUT.R2 Setd2-KO_rep1_IP.R1 Setd2-KO_rep1_IP.R2 Setd2-KO_rep2_INPUT.R1 Setd2-KO_rep2_INPUT.R2 Setd2-KO_rep2_IP.R1 Setd2-KO_rep2_IP.R2 WT_rep1_INPUT.R1 WT_rep1_INPUT.R2 WT_rep1_IP.R1 WT_rep1_IP.R2 WT_rep2_INPUT.R1 WT_rep2_INPUT.R2 WT_rep2_IP.R1 WT_rep2_IP.R2
图2.3 各个样本重复序列水平,测序深度越高,越容易产生一定程度的重复(duplication),这属于正常的现象。但如果duplication 的程度很高,就提示我们可能有 bias 的存在(如建库过程中由于 PCR 扩增引起的duplication)。横坐标为 reads 重复的次数,纵坐标为重复次数对应的 reads 占 unique reads 的比例,以unique reads 的总数作为 100%。这里,我们仅对文件前 2000000 个reads 进行统计:对长度小于75bp 的reads 将其截短为 50bp,用于统计重复。
2.2 过滤后数据质控
这里展示Fastp过滤后的数据质控结果,图片内容与上面raw data类似。
Setd2-KO_rep1_INPUT.R1 Setd2-KO_rep1_INPUT.R2 Setd2-KO_rep1_IP.R1 Setd2-KO_rep1_IP.R2 Setd2-KO_rep2_INPUT.R1 Setd2-KO_rep2_INPUT.R2 Setd2-KO_rep2_IP.R1 Setd2-KO_rep2_IP.R2 WT_rep1_INPUT.R1 WT_rep1_INPUT.R2 WT_rep1_IP.R1 WT_rep1_IP.R2 WT_rep2_INPUT.R1 WT_rep2_INPUT.R2 WT_rep2_IP.R1 WT_rep2_IP.R2
图2.4 各个样本平均测序碱基质量分数,横坐标代表150 bp长度序列中各个位置,纵坐标为该位置平均的碱基质量值Q;盒形图中间的红线表示中位数(median value);黄色部分代表四分位距(25-75%);上下分割线代表 90%和 10%的上下临界值;蓝色的线代表碱基质量的平均值。
Setd2-KO_rep1_INPUT.R1 Setd2-KO_rep1_INPUT.R2 Setd2-KO_rep1_IP.R1 Setd2-KO_rep1_IP.R2 Setd2-KO_rep2_INPUT.R1 Setd2-KO_rep2_INPUT.R2 Setd2-KO_rep2_IP.R1 Setd2-KO_rep2_IP.R2 WT_rep1_INPUT.R1 WT_rep1_INPUT.R2 WT_rep1_IP.R1 WT_rep1_IP.R2 WT_rep2_INPUT.R1 WT_rep2_INPUT.R2 WT_rep2_IP.R1 WT_rep2_IP.R2
图2.5 各个样本碱基平衡性,图中四条线代表A T C G在每个位置平均含量。理论上,A和T应该相等,G和C应该相等,且4种碱基平行且接近分布。正常情况下四种碱基的出现频率应该是接近的,而且没有位置差异。因此好的样本中四条线应该平行且接近。当部分位置碱基的比例出现 bias 时,即四条线在某些位置波动较大时,可能测序数据或者文库存在污染。当所有位置的碱基比例一致的表现出bias 时,即四条线平行但分开,往往代表文库有 bias (建库过程或本身特点),或者是测序中的系统误差。一般测序的时候,刚开始测序仪状态不稳定,在15bp之前很可能出现波动。
Setd2-KO_rep1_INPUT.R1 Setd2-KO_rep1_INPUT.R2 Setd2-KO_rep1_IP.R1 Setd2-KO_rep1_IP.R2 Setd2-KO_rep2_INPUT.R1 Setd2-KO_rep2_INPUT.R2 Setd2-KO_rep2_IP.R1 Setd2-KO_rep2_IP.R2 WT_rep1_INPUT.R1 WT_rep1_INPUT.R2 WT_rep1_IP.R1 WT_rep1_IP.R2 WT_rep2_INPUT.R1 WT_rep2_INPUT.R2 WT_rep2_IP.R1 WT_rep2_IP.R2
图2.6 各个样本重复序列水平,测序深度越高,越容易产生一定程度的重复(duplication),这属于正常的现象。但如果duplication 的程度很高,就提示我们可能有 bias 的存在(如建库过程中由于 PCR 扩增引起的duplication)。横坐标为 reads 重复的次数,纵坐标为重复次数对应的 reads 占 unique reads 的比例,以unique reads 的总数作为 100%。这里,我们仅对文件前 2000000 个reads 进行统计:对长度小于75bp 的reads 将其截短为 50bp,用于统计重复。
2.3 数据过滤结果统计
我们对数据过滤结果进行统计,如下表所示:
Sample
Raw_Total_Reads
Raw_Total_Bases
Raw_Q20_Rate
Raw_Q30_Rate
Raw_GC_Content
Clean_Total_Reads
Clean_Total_Bases
Clean_Q20_Rate
Clean_Q30_Rate
Clean_GC_Content
Setd2-KO_rep1_INPUT
5.50M
825.42M
0.983
0.948
0.574
5.47M
803.63M
0.984
0.950
0.575
Setd2-KO_rep1_IP
7.70M
1154.38M
0.984
0.954
0.548
7.67M
1055.71M
0.987
0.959
0.550
Setd2-KO_rep2_INPUT
5.82M
873.64M
0.975
0.928
0.572
5.79M
851.55M
0.976
0.930
0.573
Setd2-KO_rep2_IP
8.29M
1243.87M
0.976
0.934
0.547
8.27M
1142.89M
0.980
0.940
0.549
WT_rep1_INPUT
6.45M
967.38M
0.983
0.949
0.573
6.43M
940.26M
0.985
0.952
0.574
WT_rep1_IP
6.81M
1022.20M
0.984
0.954
0.555
6.80M
954.67M
0.987
0.958
0.557
WT_rep2_INPUT
7.41M
1112.20M
0.975
0.929
0.572
7.38M
1079.87M
0.977
0.932
0.574
WT_rep2_IP
7.91M
1186.82M
0.977
0.934
0.554
7.89M
1111.72M
0.980
0.940
0.556
表 2.1数据过滤结果统计:
3. 比对参考基因组
我们将各样品过滤后的clean data的reads与参考基因组进行比对,获取Reads在参考基因组上的定位信息,这里使用的软件是Hisat2(version 2.2.1)(Kim D et al., 2015)。来自一个DNA片段的多个拷贝,可能会锚定在多个read上,经过测序得到的这些reads就是PCR重复。PCR本身就是为了产生重复序列的。理论上来讲,不同的序列在进行PCR扩增时,扩增的倍数应该是相同的。但是由于聚合酶的偏好性,PCR扩增次数过多的情况下,会导致一些序列持续扩增,而另一些序列扩增到一定程度后便不再进行,也就是我们常说的PCR偏好性。因此,比对完成后我们使用软件Sambamba(version 1.0.1)(Tarasov A. et al., 2015)去除PCR重复,获取unique reads。
3.1 比对参考基因组情况
sample
clean_reads
PCR_dup
PCR_dup %
prop_map_reads
prop_map %
MAPQ30
Setd2-KO_INPUT_rep1
6,586,881
3,309,598
50.250
3,406,604
62.320
561,290
Setd2-KO_INPUT_rep2
7,346,744
3,440,442
46.830
3,453,742
59.650
566,065
Setd2-KO_IP_rep1
13,398,930
3,905,763
29.150
6,106,196
79.580
2,128,793
Setd2-KO_IP_rep2
13,410,666
4,227,447
31.520
6,524,068
78.910
2,254,402
WT_INPUT_rep1
7,273,464
4,000,191
55.000
4,085,858
63.510
595,248
WT_INPUT_rep2
8,811,177
4,593,900
52.140
4,632,378
62.790
643,559
WT_IP_rep1
11,044,429
3,590,200
32.510
5,288,770
77.820
1,704,613
WT_IP_rep2
12,293,593
4,222,067
34.340
6,116,598
77.510
1,929,020
表 3.1比对结果统计:
3.2 Reads富集情况
我们使用Deeptools(version 3.5.4)(Ramírez F. et al., 2016)软件对reads富集情况进行可视化,绘制reads覆盖度信号在基因组上基因不同区域(Transcription Start Site,转录起始位点,TSS; Transcription End Site,转录终止位点,TES)的分布。
Setd2-KO_rep1_INPUT_TSSTES Setd2-KO_rep1_IP_TSSTES Setd2-KO_rep2_INPUT_TSSTES Setd2-KO_rep2_IP_TSSTES WT_rep1_INPUT_TSSTES WT_rep1_IP_TSSTES WT_rep2_INPUT_TSSTES WT_rep2_IP_TSSTES
图3.1 各样本reads富集情况。横坐标为相对基因位置,纵坐标为按照基因组大小RPGC标准化后reads富集分数。
Setd2-KO_rep1_INPUT_heatmap Setd2-KO_rep1_IP_heatmap Setd2-KO_rep2_INPUT_heatmap Setd2-KO_rep2_IP_heatmap WT_rep1_INPUT_heatmap WT_rep1_IP_heatmap WT_rep2_INPUT_heatmap WT_rep2_IP_heatmap
图3.2 各样本reads富集热图。下方热图代表基因上下游Reads富集情况,每一行代表一个基因上下游区域reads富集程度。
3.3 比对可视化
软件比对所得结果为bam格式文件(位于report/result/2.map 文件夹中),bam文件是压缩的⼆进制⽂件,无法直接作为文本打开查看。由于bam文件数据较大,我们将其转为较小的bw格式文件。客户可以结合物种参考基因组和注释文件使用IGV (Integrative Genomics Viewer) 浏览器对bam、bw、bed等文件进行可视化浏览。IGV浏览器使用方法可参考我们提供的使用说明文档IGV快速上手
4. 峰鉴定
CLAM(CLIP-seq Analysis of Multi-mapped reads)(version 1.2.1)(Zhang Z. & Xing Y. 2017)是一种用于CLIP-seq和RIP-seq数据分析的计算方法,旨在利用多映射读取来提高峰调用的准确性。CLAM通过一个期望最大化(EM)算法来解决多映射读取的分配问题,从而能够识别和利用那些在传统分析中被丢弃的多映射读取。具体来说,CLAM首先将读取映射到基因组区域,然后通过EM算法推断出每个多映射读取的真实来源区域。接着,CLAM结合唯一映射读取和重新分配的多映射读取来进行峰调用,并使用置换检验来控制基因特异性错误发现率(FDR)。这种方法能够显著提高对重复序列区域的覆盖,并发现传统方法无法检测到的新RNA调控位点。本节结果请详见位于report/result/3.peak 文件夹中
4.1 Peak信息统计
sample
Peak num
FRIP
Peak reads
Total reads
Setd2-KO_rep1_IP
213
0.040
381,121
9,493,167
Setd2-KO_rep2_IP
200
0.037
337,977
9,183,219
WT_rep1_IP
168
0.034
256,451
7,454,229
WT_rep2_IP
158
0.031
247,481
8,071,526
表 4.1 Peak信息统计:
4.2 Call Peak结果
各个样本peak信息结果表部分内容如下,完整信息请查看report/result/3.peak/{样本名称}.bed 文件中。“.bed”格式文件用于描述峰区域信息,可在IGV浏览器中打开。
Setd2-KO_rep1 Setd2-KO_rep2 WT_rep1 WT_rep2
❮
chr1
45892483
45892533
Setd2-KO_rep1_peak_1
1000
+
1.910
1.696e-02
3.392e-02
.
chr1
54288281
54288331
Setd2-KO_rep1_peak_2
1000
-
1.360
0.020
0.061
.
chr1
63218213
63218263
Setd2-KO_rep1_peak_3
1000
+
2.130
0.000
0.000
.
chr1
65033660
65033710
Setd2-KO_rep1_peak_4
1000
-
3.300
0.014
0.056
.
chr1
86015073
86015123
Setd2-KO_rep1_peak_5
1000
+
3.160
0.000
0.000
.
chr1
86283983
86284033
Setd2-KO_rep1_peak_6
1000
-
2.460
0.000
0.000
.
chr1
118386921
118386971
Setd2-KO_rep1_peak_7
1000
-
1.820
0.000
0.000
.
chr1
153385361
153385411
Setd2-KO_rep1_peak_8
1000
-
0.910
0.004
0.045
.
chr1
160863420
160863470
Setd2-KO_rep1_peak_9
1000
+
2.050
0.000
0.000
.
chr1
160863627
160863677
Setd2-KO_rep1_peak_10
1000
+
1.500
0.000
0.000
.
chr1
171330666
171330716
Setd2-KO_rep1_peak_11
1000
-
3.610
0.000
0.000
.
chr1
171538706
171538756
Setd2-KO_rep1_peak_12
1000
+
2.200
0.001
0.001
.
chr2
19308163
19308213
Setd2-KO_rep1_peak_13
1000
+
1.980
0.015
0.029
.
chr2
23046618
23046668
Setd2-KO_rep1_peak_14
1000
-
2.730
0.000
0.000
.
chr2
26527909
26527959
Setd2-KO_rep1_peak_15
1000
-
1.260
0.000
0.000
.
chr2
26527910
26527960
Setd2-KO_rep1_peak_16
1000
-
1.310
0.000
0.000
.
chr2
27429867
27429917
Setd2-KO_rep1_peak_17
1000
-
4.660
0.000
0.000
.
chr2
130118207
130118257
Setd2-KO_rep1_peak_18
1000
+
1.370
0.000
0.000
.
chr2
158201768
158201818
Setd2-KO_rep1_peak_19
1000
-
2.140
0.000
0.000
.
chr3
83737625
83737675
Setd2-KO_rep1_peak_20
1000
+
2.640
0.000
0.000
.
chr3
88707229
88707279
Setd2-KO_rep1_peak_21
1000
+
0.920
0.000
0.003
.
chr3
96177368
96177418
Setd2-KO_rep1_peak_22
1000
+
1.800
0.010
0.077
.
chr3
96235791
96235841
Setd2-KO_rep1_peak_23
1000
+
4.670
0.000
0.000
.
chr3
96281387
96281437
Setd2-KO_rep1_peak_24
1000
+
3.160
0.000
0.000
.
chr3
96357804
96357854
Setd2-KO_rep1_peak_25
1000
-
1.240
0.000
0.000
.
chr3
96367424
96367474
Setd2-KO_rep1_peak_26
1000
+
2.330
0.000
0.000
.
chr3
96367440
96367490
Setd2-KO_rep1_peak_27
1000
-
2.080
0.000
0.000
.
chr3
123301636
123301686
Setd2-KO_rep1_peak_28
1000
-
0.800
0.001
0.004
.
chr3
153616200
153616250
Setd2-KO_rep1_peak_29
1000
-
2.990
0.000
0.000
.
chr3
153617247
153617297
Setd2-KO_rep1_peak_30
1000
-
1.100
0.007
0.014
.
chr3
153617762
153617812
Setd2-KO_rep1_peak_31
1000
-
1.150
0.012
0.023
.
chr4
3835079
3835129
Setd2-KO_rep1_peak_32
1000
-
1.470
0.012
0.024
.
chr4
43492833
43492883
Setd2-KO_rep1_peak_33
1000
-
3.220
0.000
0.000
.
chr4
43492838
43492888
Setd2-KO_rep1_peak_34
1000
-
2.810
0.000
0.000
.
chr4
86504740
86504790
Setd2-KO_rep1_peak_35
1000
-
2.400
0.000
0.000
.
chr4
117059776
117059826
Setd2-KO_rep1_peak_36
1000
+
0.970
0.000
0.000
.
chr4
117059775
117059825
Setd2-KO_rep1_peak_37
1000
+
1.320
0.000
0.000
.
chr4
119227113
119227163
Setd2-KO_rep1_peak_38
1000
-
1.830
0.000
0.001
.
chr4
131997445
131997495
Setd2-KO_rep1_peak_39
1000
-
1.950
0.000
0.000
.
chr4
132037601
132037651
Setd2-KO_rep1_peak_40
1000
+
0.710
0.009
0.026
.
chr4
132038002
132038052
Setd2-KO_rep1_peak_41
1000
+
2.790
0.000
0.000
.
chr5
74254241
74254291
Setd2-KO_rep1_peak_42
1000
+
1.370
0.000
0.000
.
chr5
115627518
115627568
Setd2-KO_rep1_peak_43
1000
+
2.350
0.003
0.008
.
chr5
115627518
115627568
Setd2-KO_rep1_peak_44
1000
+
2.480
0.000
0.001
.
chr5
115628313
115628363
Setd2-KO_rep1_peak_45
1000
+
1.440
0.007
0.020
.
chr5
121343144
121343194
Setd2-KO_rep1_peak_46
1000
+
2.190
0.001
0.041
.
chr5
129871659
129871709
Setd2-KO_rep1_peak_47
1000
+
2.610
0.000
0.000
.
chr5
146772004
146772054
Setd2-KO_rep1_peak_48
1000
+
4.370
0.000
0.000
.
chr6
3201494
3201544
Setd2-KO_rep1_peak_49
1000
+
0.720
0.001
0.012
.
chr6
3201544
3201594
Setd2-KO_rep1_peak_50
1000
+
1.120
0.004
0.037
.
chr6
47755215
47755265
Setd2-KO_rep1_peak_51
1000
+
1.350
0.001
0.007
.
chr6
47758619
47758669
Setd2-KO_rep1_peak_52
1000
+
1.300
0.013
0.051
.
chr6
71101744
71101794
Setd2-KO_rep1_peak_53
1000
+
1.930
0.028
0.084
.
chr6
71101844
71101894
Setd2-KO_rep1_peak_54
1000
+
2.060
0.004
0.021
.
chr6
71859591
71859641
Setd2-KO_rep1_peak_55
1000
-
1.470
0.000
0.000
.
chr6
125098737
125098787
Setd2-KO_rep1_peak_56
1000
+
3.030
0.000
0.000
.
chr6
128775848
128775898
Setd2-KO_rep1_peak_57
1000
-
2.100
0.002
0.005
.
chr6
136781051
136781101
Setd2-KO_rep1_peak_58
1000
-
1.510
0.025
0.075
.
chr6
136781151
136781201
Setd2-KO_rep1_peak_59
1000
-
1.760
0.014
0.075
.
chr7
44776288
44776338
Setd2-KO_rep1_peak_60
1000
-
2.560
0.014
0.028
.
chr7
44776342
44776392
Setd2-KO_rep1_peak_61
1000
-
1.500
0.026
0.026
.
chr7
81179653
81179703
Setd2-KO_rep1_peak_62
1000
+
2.300
0.002
0.005
.
chr7
81179664
81179714
Setd2-KO_rep1_peak_63
1000
+
2.300
0.000
0.000
.
chr7
99128820
99128870
Setd2-KO_rep1_peak_64
1000
-
2.510
0.000
0.000
.
chr7
99132042
99132092
Setd2-KO_rep1_peak_65
1000
-
2.260
0.000
0.000
.
chr7
109119377
109119427
Setd2-KO_rep1_peak_66
1000
+
2.280
0.000
0.000
.
chr7
109120537
109120587
Setd2-KO_rep1_peak_67
1000
+
1.270
0.001
0.002
.
chr7
127127096
127127146
Setd2-KO_rep1_peak_68
1000
+
3.370
0.000
0.000
.
chr7
141028766
141028816
Setd2-KO_rep1_peak_69
1000
+
2.970
0.000
0.000
.
chr8
3853269
3853319
Setd2-KO_rep1_peak_70
1000
-
1.540
0.016
0.047
.
chr8
13926141
13926191
Setd2-KO_rep1_peak_71
1000
+
3.270
0.000
0.000
.
chr8
13926147
13926197
Setd2-KO_rep1_peak_72
1000
+
3.260
0.000
0.000
.
chr8
31639892
31639942
Setd2-KO_rep1_peak_73
1000
-
0.980
0.000
0.000
.
chr8
34181879
34181929
Setd2-KO_rep1_peak_74
1000
+
3.250
0.000
0.000
.
chr8
124294376
124294426
Setd2-KO_rep1_peak_75
1000
-
1.210
0.022
0.043
.
chr8
124312981
124313031
Setd2-KO_rep1_peak_76
1000
-
0.920
0.025
0.051
.
chr8
124321493
124321543
Setd2-KO_rep1_peak_77
1000
-
0.920
0.021
0.041
.
chr8
124323196
124323246
Setd2-KO_rep1_peak_78
1000
-
1.110
0.006
0.012
.
chr8
124324897
124324947
Setd2-KO_rep1_peak_79
1000
-
0.870
0.033
0.066
.
chr8
124329986
124330036
Setd2-KO_rep1_peak_80
1000
-
1.150
0.002
0.003
.
chr8
124333352
124333402
Setd2-KO_rep1_peak_81
1000
-
0.830
0.016
0.032
.
chr8
124335059
124335109
Setd2-KO_rep1_peak_82
1000
-
0.830
0.017
0.034
.
chr8
124336756
124336806
Setd2-KO_rep1_peak_83
1000
-
0.870
0.011
0.022
.
chr8
124338454
124338504
Setd2-KO_rep1_peak_84
1000
-
0.720
0.030
0.060
.
chr8
124340153
124340203
Setd2-KO_rep1_peak_85
1000
-
0.820
0.015
0.031
.
chr8
124341838
124341888
Setd2-KO_rep1_peak_86
1000
-
0.820
0.012
0.024
.
chr8
124343549
124343599
Setd2-KO_rep1_peak_87
1000
-
0.730
0.037
0.075
.
chr8
124346980
124347030
Setd2-KO_rep1_peak_88
1000
-
0.850
0.025
0.049
.
chr8
124348667
124348717
Setd2-KO_rep1_peak_89
1000
-
0.810
0.018
0.036
.
chr8
127671647
127671697
Setd2-KO_rep1_peak_90
1000
-
1.160
0.000
0.000
.
chr9
15237760
15237810
Setd2-KO_rep1_peak_91
1000
-
4.260
0.000
0.000
.
chr9
64203263
64203313
Setd2-KO_rep1_peak_92
1000
+
3.610
0.000
0.000
.
chr9
65103907
65103957
Setd2-KO_rep1_peak_93
1000
-
2.960
0.000
0.000
.
chr9
65103904
65103954
Setd2-KO_rep1_peak_94
1000
-
2.830
0.000
0.000
.
chr9
65109058
65109108
Setd2-KO_rep1_peak_95
1000
-
2.940
0.000
0.000
.
chr9
78082635
78082685
Setd2-KO_rep1_peak_96
1000
-
0.890
0.003
0.010
.
chr9
78082835
78082885
Setd2-KO_rep1_peak_97
1000
-
1.810
0.001
0.007
.
chr9
109961211
109961261
Setd2-KO_rep1_peak_98
1000
-
1.670
0.003
0.008
.
chr9
119958505
119958555
Setd2-KO_rep1_peak_99
1000
+
2.610
0.000
0.020
.
chr9
119958525
119958575
Setd2-KO_rep1_peak_100
1000
-
2.760
0.000
0.004
.
chr9
119957896
119957946
Setd2-KO_rep1_peak_101
1000
+
1.240
0.000
0.001
.
chr1
9644823
9644873
Setd2-KO_rep2_peak_1
1000
+
2.050
1.759e-03
8.796e-03
.
chr1
63218213
63218263
Setd2-KO_rep2_peak_2
1000
+
1.270
0.001
0.004
.
chr1
118386921
118386971
Setd2-KO_rep2_peak_3
1000
-
1.170
0.035
0.070
.
chr1
143654730
143654780
Setd2-KO_rep2_peak_4
1000
+
0.940
0.001
0.006
.
chr1
143654716
143654766
Setd2-KO_rep2_peak_5
1000
+
1.980
0.000
0.000
.
chr1
157272994
157273044
Setd2-KO_rep2_peak_6
1000
+
2.320
0.000
0.000
.
chr1
160864976
160865026
Setd2-KO_rep2_peak_7
1000
+
0.940
0.034
0.069
.
chr1
160865652
160865702
Setd2-KO_rep2_peak_8
1000
+
1.100
0.012
0.025
.
chr1
171538706
171538756
Setd2-KO_rep2_peak_9
1000
+
2.460
0.000
0.000
.
chr1
192427919
192427969
Setd2-KO_rep2_peak_10
1000
-
1.520
0.000
0.000
.
chr1
192427929
192427979
Setd2-KO_rep2_peak_11
1000
+
1.070
0.000
0.000
.
chr2
22634832
22634882
Setd2-KO_rep2_peak_12
1000
-
1.230
0.014
0.042
.
chr2
26527909
26527959
Setd2-KO_rep2_peak_13
1000
-
1.040
0.000
0.001
.
chr2
26527910
26527960
Setd2-KO_rep2_peak_14
1000
-
1.460
0.000
0.000
.
chr2
26529252
26529302
Setd2-KO_rep2_peak_15
1000
-
1.130
0.000
0.000
.
chr2
27429867
27429917
Setd2-KO_rep2_peak_16
1000
-
2.060
0.000
0.000
.
chr2
102914770
102914820
Setd2-KO_rep2_peak_17
1000
+
1.550
0.000
0.000
.
chr2
126520990
126521040
Setd2-KO_rep2_peak_18
1000
+
1.670
0.003
0.011
.
chr2
130118207
130118257
Setd2-KO_rep2_peak_19
1000
+
1.270
0.001
0.002
.
chr2
144103559
144103609
Setd2-KO_rep2_peak_20
1000
-
2.220
0.000
0.000
.
chr2
158201768
158201818
Setd2-KO_rep2_peak_21
1000
-
1.670
0.000
0.000
.
chr3
10366726
10366776
Setd2-KO_rep2_peak_22
1000
+
1.290
0.071
0.071
.
chr3
37768939
37768989
Setd2-KO_rep2_peak_23
1000
+
1.580
0.061
0.061
.
chr3
58609800
58609850
Setd2-KO_rep2_peak_24
1000
+
1.510
0.032
0.032
.
chr3
96147265
96147315
Setd2-KO_rep2_peak_25
1000
-
2.880
0.000
0.001
.
chr3
96153113
96153163
Setd2-KO_rep2_peak_26
1000
+
1.960
0.004
0.028
.
chr3
96153120
96153170
Setd2-KO_rep2_peak_27
1000
+
1.950
0.004
0.075
.
chr3
96153142
96153192
Setd2-KO_rep2_peak_28
1000
-
1.880
0.030
0.091
.
chr3
96177360
96177410
Setd2-KO_rep2_peak_29
1000
+
2.330
0.001
0.012
.
chr3
96177141
96177191
Setd2-KO_rep2_peak_30
1000
-
2.000
0.004
0.068
.
chr3
96177318
96177368
Setd2-KO_rep2_peak_31
1000
+
1.910
0.024
0.098
.
chr3
96177368
96177418
Setd2-KO_rep2_peak_32
1000
+
2.510
0.000
0.002
.
chr3
96235791
96235841
Setd2-KO_rep2_peak_33
1000
+
2.860
0.000
0.000
.
chr3
96281387
96281437
Setd2-KO_rep2_peak_34
1000
+
3.200
0.000
0.000
.
chr3
96357804
96357854
Setd2-KO_rep2_peak_35
1000
-
2.370
0.000
0.000
.
chr3
96357812
96357862
Setd2-KO_rep2_peak_36
1000
+
3.290
0.000
0.000
.
chr3
96367424
96367474
Setd2-KO_rep2_peak_37
1000
+
1.600
0.000
0.000
.
chr3
96367440
96367490
Setd2-KO_rep2_peak_38
1000
-
3.610
0.000
0.000
.
chr3
123301636
123301686
Setd2-KO_rep2_peak_39
1000
-
0.920
0.000
0.001
.
chr3
153616200
153616250
Setd2-KO_rep2_peak_40
1000
-
3.230
0.000
0.000
.
chr4
43492833
43492883
Setd2-KO_rep2_peak_41
1000
-
2.190
0.000
0.000
.
chr4
43492838
43492888
Setd2-KO_rep2_peak_42
1000
-
1.920
0.000
0.000
.
chr4
119227113
119227163
Setd2-KO_rep2_peak_43
1000
-
1.300
0.000
0.005
.
chr4
125398231
125398281
Setd2-KO_rep2_peak_44
1000
+
2.110
0.002
0.020
.
chr4
131997445
131997495
Setd2-KO_rep2_peak_45
1000
-
2.400
0.000
0.000
.
chr4
131997417
131997467
Setd2-KO_rep2_peak_46
1000
+
1.510
0.000
0.000
.
chr4
131997441
131997491
Setd2-KO_rep2_peak_47
1000
-
2.600
0.000
0.000
.
chr4
132037601
132037651
Setd2-KO_rep2_peak_48
1000
+
1.230
0.000
0.001
.
chr4
146648960
146649010
Setd2-KO_rep2_peak_49
1000
-
0.980
0.013
0.081
.
chr5
74254241
74254291
Setd2-KO_rep2_peak_50
1000
+
2.290
0.000
0.000
.
chr5
110839965
110840015
Setd2-KO_rep2_peak_51
1000
-
1.700
0.000
0.001
.
chr5
114845345
114845395
Setd2-KO_rep2_peak_52
1000
-
1.170
0.003
0.015
.
chr5
115241487
115241537
Setd2-KO_rep2_peak_53
1000
-
2.200
0.001
0.001
.
chr5
115627518
115627568
Setd2-KO_rep2_peak_54
1000
+
2.760
0.001
0.002
.
chr5
115627518
115627568
Setd2-KO_rep2_peak_55
1000
+
2.480
0.001
0.006
.
chr5
121343123
121343173
Setd2-KO_rep2_peak_56
1000
+
1.300
0.000
0.001
.
chr5
129871659
129871709
Setd2-KO_rep2_peak_57
1000
+
2.820
0.000
0.000
.
chr5
135386599
135386649
Setd2-KO_rep2_peak_58
1000
+
1.980
0.003
0.007
.
chr5
142890270
142890320
Setd2-KO_rep2_peak_59
1000
-
2.010
0.001
0.062
.
chr6
3201544
3201594
Setd2-KO_rep2_peak_60
1000
+
1.710
0.000
0.001
.
chr6
69493465
69493515
Setd2-KO_rep2_peak_61
1000
+
1.130
0.062
0.062
.
chr6
71101694
71101744
Setd2-KO_rep2_peak_62
1000
+
1.530
0.014
0.076
.
chr6
71101744
71101794
Setd2-KO_rep2_peak_63
1000
+
1.970
0.025
0.076
.
chr6
124692335
124692385
Setd2-KO_rep2_peak_64
1000
-
2.020
0.003
0.049
.
chr6
125098737
125098787
Setd2-KO_rep2_peak_65
1000
+
4.000
0.000
0.000
.
chr7
12531650
12531700
Setd2-KO_rep2_peak_66
1000
-
1.510
0.033
0.065
.
chr7
44776288
44776338
Setd2-KO_rep2_peak_67
1000
-
2.110
0.000
0.000
.
chr7
99132042
99132092
Setd2-KO_rep2_peak_68
1000
-
3.120
0.000
0.000
.
chr7
109120537
109120587
Setd2-KO_rep2_peak_69
1000
+
1.400
0.003
0.006
.
chr7
141028766
141028816
Setd2-KO_rep2_peak_70
1000
+
2.240
0.000
0.000
.
chr8
3853269
3853319
Setd2-KO_rep2_peak_71
1000
-
1.410
0.009
0.028
.
chr8
34181879
34181929
Setd2-KO_rep2_peak_72
1000
+
1.630
0.000
0.000
.
chr8
87774717
87774767
Setd2-KO_rep2_peak_73
1000
+
1.830
0.010
0.078
.
chr8
124301136
124301186
Setd2-KO_rep2_peak_74
1000
-
1.070
0.029
0.058
.
chr8
124302815
124302865
Setd2-KO_rep2_peak_75
1000
-
0.910
0.042
0.084
.
chr8
124312981
124313031
Setd2-KO_rep2_peak_76
1000
-
1.090
0.008
0.016
.
chr8
124321493
124321543
Setd2-KO_rep2_peak_77
1000
-
0.770
0.043
0.086
.
chr8
124323196
124323246
Setd2-KO_rep2_peak_78
1000
-
0.760
0.044
0.089
.
chr8
124324897
124324947
Setd2-KO_rep2_peak_79
1000
-
0.890
0.021
0.042
.
chr8
124329986
124330036
Setd2-KO_rep2_peak_80
1000
-
0.990
0.008
0.015
.
chr8
124333352
124333402
Setd2-KO_rep2_peak_81
1000
-
0.870
0.014
0.028
.
chr8
124335059
124335109
Setd2-KO_rep2_peak_82
1000
-
0.770
0.031
0.061
.
chr8
124340153
124340203
Setd2-KO_rep2_peak_83
1000
-
0.860
0.014
0.027
.
chr8
124341838
124341888
Setd2-KO_rep2_peak_84
1000
-
0.700
0.039
0.077
.
chr8
124343549
124343599
Setd2-KO_rep2_peak_85
1000
-
0.790
0.024
0.048
.
chr8
124345275
124345325
Setd2-KO_rep2_peak_86
1000
-
0.750
0.029
0.059
.
chr8
124346980
124347030
Setd2-KO_rep2_peak_87
1000
-
1.010
0.007
0.013
.
chr8
124348667
124348717
Setd2-KO_rep2_peak_88
1000
-
0.880
0.015
0.030
.
chr9
15237760
15237810
Setd2-KO_rep2_peak_89
1000
-
3.870
0.000
0.000
.
chr9
58207921
58207971
Setd2-KO_rep2_peak_90
1000
-
1.790
0.006
0.019
.
chr9
65103907
65103957
Setd2-KO_rep2_peak_91
1000
-
1.910
0.000
0.000
.
chr9
65109035
65109085
Setd2-KO_rep2_peak_92
1000
+
1.840
0.001
0.026
.
chr9
65103904
65103954
Setd2-KO_rep2_peak_93
1000
-
2.990
0.000
0.000
.
chr9
78082635
78082685
Setd2-KO_rep2_peak_94
1000
-
1.400
0.000
0.000
.
chr9
78082835
78082885
Setd2-KO_rep2_peak_95
1000
-
2.300
0.001
0.003
.
chr9
123291192
123291242
Setd2-KO_rep2_peak_96
1000
+
2.030
0.000
0.000
.
chr10
23661295
23661345
Setd2-KO_rep2_peak_97
1000
-
1.000
0.000
0.000
.
chr10
23662368
23662418
Setd2-KO_rep2_peak_98
1000
-
1.190
0.005
0.010
.
chr10
75695237
75695287
Setd2-KO_rep2_peak_99
1000
-
2.470
0.004
0.031
.
chr10
111317404
111317454
Setd2-KO_rep2_peak_100
1000
+
2.290
0.000
0.000
.
chr10
130428226
130428276
Setd2-KO_rep2_peak_101
1000
-
1.510
0.032
0.095
.
chr1
63218213
63218263
WT_rep1_peak_1
1000
+
1.680
6.040e-03
1.812e-02
.
chr1
72265499
72265549
WT_rep1_peak_2
1000
+
1.310
0.049
0.097
.
chr1
118386921
118386971
WT_rep1_peak_3
1000
-
1.850
0.034
0.067
.
chr1
143654716
143654766
WT_rep1_peak_4
1000
+
1.410
0.000
0.000
.
chr1
159167903
159167953
WT_rep1_peak_5
1000
+
3.640
0.000
0.000
.
chr1
159167928
159167978
WT_rep1_peak_6
1000
+
2.900
0.000
0.000
.
chr1
160863420
160863470
WT_rep1_peak_7
1000
+
1.470
0.001
0.001
.
chr1
160863627
160863677
WT_rep1_peak_8
1000
+
1.380
0.026
0.053
.
chr1
171330636
171330686
WT_rep1_peak_9
1000
-
0.930
0.016
0.065
.
chr1
171330666
171330716
WT_rep1_peak_10
1000
-
3.500
0.000
0.000
.
chr1
171538706
171538756
WT_rep1_peak_11
1000
+
1.500
0.026
0.026
.
chr2
19308163
19308213
WT_rep1_peak_12
1000
+
1.620
0.013
0.040
.
chr2
26527909
26527959
WT_rep1_peak_13
1000
-
0.920
0.002
0.007
.
chr2
26527910
26527960
WT_rep1_peak_14
1000
-
1.050
0.001
0.002
.
chr2
27429867
27429917
WT_rep1_peak_15
1000
-
2.680
0.000
0.000
.
chr2
32853353
32853403
WT_rep1_peak_16
1000
+
1.920
0.000
0.000
.
chr2
102914770
102914820
WT_rep1_peak_17
1000
+
2.070
0.000
0.001
.
chr2
144103559
144103609
WT_rep1_peak_18
1000
-
1.280
0.006
0.018
.
chr2
144107999
144108049
WT_rep1_peak_19
1000
-
1.410
0.000
0.000
.
chr2
166907196
166907246
WT_rep1_peak_20
1000
+
2.700
0.000
0.000
.
chr3
81736781
81736831
WT_rep1_peak_21
1000
-
2.710
0.005
0.011
.
chr3
88601287
88601337
WT_rep1_peak_22
1000
+
3.510
0.000
0.000
.
chr3
88601288
88601338
WT_rep1_peak_23
1000
+
3.510
0.000
0.000
.
chr3
88707229
88707279
WT_rep1_peak_24
1000
+
1.350
0.000
0.000
.
chr3
96177141
96177191
WT_rep1_peak_25
1000
-
2.330
0.003
0.038
.
chr3
96177191
96177241
WT_rep1_peak_26
1000
-
1.880
0.008
0.053
.
chr3
96177368
96177418
WT_rep1_peak_27
1000
+
1.890
0.010
0.070
.
chr3
96235791
96235841
WT_rep1_peak_28
1000
+
2.850
0.000
0.000
.
chr3
96281387
96281437
WT_rep1_peak_29
1000
+
3.500
0.000
0.000
.
chr3
96357804
96357854
WT_rep1_peak_30
1000
-
1.380
0.000
0.000
.
chr3
96367424
96367474
WT_rep1_peak_31
1000
+
2.310
0.000
0.000
.
chr3
96367440
96367490
WT_rep1_peak_32
1000
-
1.370
0.001
0.002
.
chr3
153617762
153617812
WT_rep1_peak_33
1000
-
1.100
0.011
0.022
.
chr4
43492833
43492883
WT_rep1_peak_34
1000
-
1.740
0.000
0.000
.
chr4
43492883
43492933
WT_rep1_peak_35
1000
-
0.920
0.000
0.000
.
chr4
43492838
43492888
WT_rep1_peak_36
1000
-
1.690
0.000
0.000
.
chr4
131997441
131997491
WT_rep1_peak_37
1000
-
1.620
0.006
0.011
.
chr4
132036825
132036875
WT_rep1_peak_38
1000
+
1.870
0.000
0.000
.
chr4
132036826
132036876
WT_rep1_peak_39
1000
+
2.050
0.000
0.000
.
chr5
115627518
115627568
WT_rep1_peak_40
1000
+
2.300
0.000
0.000
.
chr5
118567725
118567775
WT_rep1_peak_41
1000
+
2.670
0.000
0.000
.
chr5
121343123
121343173
WT_rep1_peak_42
1000
+
2.020
0.000
0.000
.
chr5
125486088
125486138
WT_rep1_peak_43
1000
-
2.540
0.000
0.001
.
chr5
129871659
129871709
WT_rep1_peak_44
1000
+
2.810
0.000
0.000
.
chr5
146772004
146772054
WT_rep1_peak_45
1000
+
2.300
0.000
0.000
.
chr6
71859591
71859641
WT_rep1_peak_46
1000
-
1.850
0.000
0.000
.
chr6
124692335
124692385
WT_rep1_peak_47
1000
-
2.250
0.005
0.081
.
chr6
125098737
125098787
WT_rep1_peak_48
1000
+
3.650
0.000
0.000
.
chr6
136781151
136781201
WT_rep1_peak_49
1000
-
1.800
0.005
0.033
.
chr7
99128820
99128870
WT_rep1_peak_50
1000
-
2.080
0.000
0.000
.
chr7
99132042
99132092
WT_rep1_peak_51
1000
-
4.030
0.000
0.000
.
chr7
109119377
109119427
WT_rep1_peak_52
1000
+
1.390
0.001
0.002
.
chr7
109120537
109120587
WT_rep1_peak_53
1000
+
1.770
0.000
0.001
.
chr7
141028766
141028816
WT_rep1_peak_54
1000
+
1.230
0.008
0.024
.
chr8
52790050
52790100
WT_rep1_peak_55
1000
-
3.180
0.000
0.000
.
chr8
87774717
87774767
WT_rep1_peak_56
1000
+
1.870
0.011
0.085
.
chr8
96472738
96472788
WT_rep1_peak_57
1000
-
2.640
0.000
0.000
.
chr8
124294376
124294426
WT_rep1_peak_58
1000
-
1.170
0.027
0.054
.
chr8
124301136
124301186
WT_rep1_peak_59
1000
-
1.120
0.038
0.077
.
chr8
124304494
124304544
WT_rep1_peak_60
1000
-
1.070
0.034
0.067
.
chr8
124312981
124313031
WT_rep1_peak_61
1000
-
1.000
0.022
0.044
.
chr8
124319810
124319860
WT_rep1_peak_62
1000
-
0.910
0.023
0.047
.
chr8
124321493
124321543
WT_rep1_peak_63
1000
-
1.010
0.013
0.027
.
chr8
124324897
124324947
WT_rep1_peak_64
1000
-
0.940
0.024
0.048
.
chr8
124329986
124330036
WT_rep1_peak_65
1000
-
1.050
0.005
0.010
.
chr8
124331687
124331737
WT_rep1_peak_66
1000
-
0.860
0.027
0.053
.
chr8
124333352
124333402
WT_rep1_peak_67
1000
-
0.860
0.016
0.031
.
chr8
124335059
124335109
WT_rep1_peak_68
1000
-
0.810
0.030
0.060
.
chr8
124336756
124336806
WT_rep1_peak_69
1000
-
0.960
0.005
0.010
.
chr8
124338454
124338504
WT_rep1_peak_70
1000
-
0.910
0.009
0.018
.
chr8
124340153
124340203
WT_rep1_peak_71
1000
-
0.860
0.016
0.032
.
chr8
124341838
124341888
WT_rep1_peak_72
1000
-
0.930
0.006
0.012
.
chr8
124343549
124343599
WT_rep1_peak_73
1000
-
0.770
0.034
0.067
.
chr8
124345275
124345325
WT_rep1_peak_74
1000
-
0.900
0.014
0.027
.
chr8
124346980
124347030
WT_rep1_peak_75
1000
-
1.010
0.008
0.017
.
chr8
124348667
124348717
WT_rep1_peak_76
1000
-
0.750
0.034
0.069
.
chr9
15226535
15226585
WT_rep1_peak_77
1000
+
1.310
0.000
0.000
.
chr9
15237760
15237810
WT_rep1_peak_78
1000
-
4.100
0.000
0.000
.
chr9
21071132
21071182
WT_rep1_peak_79
1000
-
2.620
0.023
0.070
.
chr9
64083993
64084043
WT_rep1_peak_80
1000
+
2.460
0.000
0.000
.
chr9
65103904
65103954
WT_rep1_peak_81
1000
-
1.150
0.005
0.009
.
chr9
88739746
88739796
WT_rep1_peak_82
1000
-
1.510
0.032
0.032
.
chr9
119958505
119958555
WT_rep1_peak_83
1000
+
2.510
0.001
0.036
.
chr9
119958525
119958575
WT_rep1_peak_84
1000
-
2.850
0.000
0.000
.
chr9
119957896
119957946
WT_rep1_peak_85
1000
+
1.100
0.000
0.002
.
chr9
119959531
119959581
WT_rep1_peak_86
1000
+
1.320
0.000
0.000
.
chr10
40134563
40134613
WT_rep1_peak_87
1000
+
1.000
0.021
0.083
.
chr10
40134563
40134613
WT_rep1_peak_88
1000
+
1.000
0.021
0.083
.
chr10
111317404
111317454
WT_rep1_peak_89
1000
+
1.160
0.000
0.001
.
chr10
121273369
121273419
WT_rep1_peak_90
1000
-
2.080
0.026
0.026
.
chr10
127150917
127150967
WT_rep1_peak_91
1000
-
1.850
0.027
0.054
.
chr11
68964303
68964353
WT_rep1_peak_92
1000
+
2.110
0.000
0.000
.
chr11
69558710
69558760
WT_rep1_peak_93
1000
-
2.390
0.000
0.000
.
chr11
69559728
69559778
WT_rep1_peak_94
1000
-
1.760
0.000
0.000
.
chr11
87362241
87362291
WT_rep1_peak_95
1000
+
2.440
0.000
0.014
.
chr11
87313743
87313793
WT_rep1_peak_96
1000
+
2.740
0.000
0.000
.
chr11
87317592
87317642
WT_rep1_peak_97
1000
+
1.360
0.000
0.000
.
chr11
97884854
97884904
WT_rep1_peak_98
1000
-
1.850
0.007
0.007
.
chr11
102171343
102171393
WT_rep1_peak_99
1000
-
1.980
0.015
0.029
.
chr11
106391819
106391869
WT_rep1_peak_100
1000
+
1.900
0.000
0.000
.
chr11
108902663
108902713
WT_rep1_peak_101
1000
+
1.520
0.004
0.036
.
chr1
24654166
24654216
WT_rep2_peak_1
1000
-
2.460
4.397e-04
5.717e-03
.
chr1
63218213
63218263
WT_rep2_peak_2
1000
+
2.130
0.000
0.000
.
chr1
143654716
143654766
WT_rep2_peak_3
1000
+
0.810
0.033
0.066
.
chr1
153385361
153385411
WT_rep2_peak_4
1000
-
1.440
0.001
0.009
.
chr1
160863627
160863677
WT_rep2_peak_5
1000
+
1.580
0.000
0.000
.
chr1
160865652
160865702
WT_rep2_peak_6
1000
+
2.170
0.000
0.000
.
chr1
170855589
170855639
WT_rep2_peak_7
1000
+
2.200
0.001
0.002
.
chr1
170855577
170855627
WT_rep2_peak_8
1000
-
1.540
0.007
0.030
.
chr1
171330666
171330716
WT_rep2_peak_9
1000
-
3.200
0.000
0.000
.
chr2
27429867
27429917
WT_rep2_peak_10
1000
-
2.240
0.000
0.000
.
chr2
102914770
102914820
WT_rep2_peak_11
1000
+
2.150
0.000
0.002
.
chr2
130118207
130118257
WT_rep2_peak_12
1000
+
1.860
0.000
0.000
.
chr2
144103559
144103609
WT_rep2_peak_13
1000
-
2.360
0.000
0.000
.
chr2
166907196
166907246
WT_rep2_peak_14
1000
+
1.180
0.012
0.023
.
chr3
52630108
52630158
WT_rep2_peak_15
1000
+
2.540
0.000
0.000
.
chr3
96147265
96147315
WT_rep2_peak_16
1000
-
2.090
0.003
0.020
.
chr3
96153142
96153192
WT_rep2_peak_17
1000
-
1.760
0.013
0.038
.
chr3
96235791
96235841
WT_rep2_peak_18
1000
+
3.380
0.000
0.000
.
chr3
96281387
96281437
WT_rep2_peak_19
1000
+
2.260
0.000
0.000
.
chr3
96357804
96357854
WT_rep2_peak_20
1000
-
2.040
0.000
0.000
.
chr3
96357812
96357862
WT_rep2_peak_21
1000
+
2.750
0.000
0.000
.
chr3
96367424
96367474
WT_rep2_peak_22
1000
+
2.230
0.000
0.000
.
chr3
96367440
96367490
WT_rep2_peak_23
1000
-
1.720
0.000
0.000
.
chr3
96393950
96394000
WT_rep2_peak_24
1000
-
1.420
0.000
0.000
.
chr4
43492833
43492883
WT_rep2_peak_25
1000
-
1.400
0.000
0.000
.
chr4
43492883
43492933
WT_rep2_peak_26
1000
-
0.810
0.001
0.001
.
chr4
43492838
43492888
WT_rep2_peak_27
1000
-
1.460
0.000
0.000
.
chr4
43492900
43492950
WT_rep2_peak_28
1000
+
0.790
0.003
0.033
.
chr4
51812533
51812583
WT_rep2_peak_29
1000
-
3.930
0.000
0.000
.
chr4
119227113
119227163
WT_rep2_peak_30
1000
-
1.480
0.001
0.008
.
chr4
131997445
131997495
WT_rep2_peak_31
1000
-
2.240
0.010
0.039
.
chr4
131997441
131997491
WT_rep2_peak_32
1000
-
2.860
0.001
0.004
.
chr4
132037302
132037352
WT_rep2_peak_33
1000
+
2.080
0.000
0.000
.
chr4
132037601
132037651
WT_rep2_peak_34
1000
+
1.120
0.000
0.000
.
chr5
74253903
74253953
WT_rep2_peak_35
1000
-
1.080
0.000
0.000
.
chr5
74254241
74254291
WT_rep2_peak_36
1000
+
2.160
0.000
0.000
.
chr5
92203973
92204023
WT_rep2_peak_37
1000
-
1.290
0.001
0.002
.
chr5
100577238
100577288
WT_rep2_peak_38
1000
+
2.100
0.008
0.016
.
chr5
115627518
115627568
WT_rep2_peak_39
1000
+
2.520
0.001
0.007
.
chr5
118567725
118567775
WT_rep2_peak_40
1000
+
2.010
0.001
0.004
.
chr5
125486088
125486138
WT_rep2_peak_41
1000
-
1.950
0.000
0.000
.
chr5
129866653
129866703
WT_rep2_peak_42
1000
+
3.430
0.000
0.000
.
chr5
129871659
129871709
WT_rep2_peak_43
1000
+
3.160
0.000
0.000
.
chr5
146772004
146772054
WT_rep2_peak_44
1000
+
3.420
0.000
0.000
.
chr6
47755215
47755265
WT_rep2_peak_45
1000
+
2.890
0.000
0.000
.
chr6
47758557
47758607
WT_rep2_peak_46
1000
+
1.770
0.040
0.079
.
chr6
47758558
47758608
WT_rep2_peak_47
1000
+
1.990
0.016
0.032
.
chr6
69493465
69493515
WT_rep2_peak_48
1000
+
1.420
0.030
0.030
.
chr6
71859591
71859641
WT_rep2_peak_49
1000
-
2.220
0.000
0.000
.
chr6
124692335
124692385
WT_rep2_peak_50
1000
-
2.320
0.001
0.012
.
chr6
125098737
125098787
WT_rep2_peak_51
1000
+
3.770
0.000
0.000
.
chr7
28050983
28051033
WT_rep2_peak_52
1000
+
2.200
0.000
0.000
.
chr7
83972536
83972586
WT_rep2_peak_53
1000
-
1.450
0.002
0.018
.
chr7
99128820
99128870
WT_rep2_peak_54
1000
-
2.440
0.000
0.000
.
chr7
99132042
99132092
WT_rep2_peak_55
1000
-
2.950
0.000
0.000
.
chr7
109120537
109120587
WT_rep2_peak_56
1000
+
1.270
0.009
0.027
.
chr7
109645621
109645671
WT_rep2_peak_57
1000
+
1.240
0.000
0.001
.
chr7
127127096
127127146
WT_rep2_peak_58
1000
+
3.140
0.000
0.000
.
chr7
141028766
141028816
WT_rep2_peak_59
1000
+
1.910
0.000
0.000
.
chr8
52790050
52790100
WT_rep2_peak_60
1000
-
2.770
0.000
0.000
.
chr8
105210401
105210451
WT_rep2_peak_61
1000
-
1.560
0.032
0.032
.
chr8
123829777
123829827
WT_rep2_peak_62
1000
+
1.790
0.001
0.002
.
chr8
124312981
124313031
WT_rep2_peak_63
1000
-
0.800
0.045
0.090
.
chr8
124323196
124323246
WT_rep2_peak_64
1000
-
0.950
0.012
0.024
.
chr8
124329986
124330036
WT_rep2_peak_65
1000
-
0.850
0.015
0.030
.
chr8
124331687
124331737
WT_rep2_peak_66
1000
-
0.850
0.021
0.042
.
chr8
124333352
124333402
WT_rep2_peak_67
1000
-
0.820
0.018
0.037
.
chr8
124335059
124335109
WT_rep2_peak_68
1000
-
0.890
0.012
0.024
.
chr8
124336756
124336806
WT_rep2_peak_69
1000
-
0.820
0.016
0.032
.
chr8
124338454
124338504
WT_rep2_peak_70
1000
-
0.840
0.012
0.024
.
chr8
124340153
124340203
WT_rep2_peak_71
1000
-
0.750
0.026
0.051
.
chr8
124341838
124341888
WT_rep2_peak_72
1000
-
0.700
0.039
0.078
.
chr8
124345275
124345325
WT_rep2_peak_73
1000
-
0.870
0.011
0.021
.
chr8
124346980
124347030
WT_rep2_peak_74
1000
-
0.810
0.022
0.045
.
chr8
124348667
124348717
WT_rep2_peak_75
1000
-
0.840
0.020
0.040
.
chr8
127671647
127671697
WT_rep2_peak_76
1000
-
0.980
0.000
0.000
.
chr9
15237760
15237810
WT_rep2_peak_77
1000
-
4.690
0.000
0.000
.
chr9
61820666
61820716
WT_rep2_peak_78
1000
-
1.650
0.024
0.095
.
chr9
61821666
61821716
WT_rep2_peak_79
1000
-
1.290
0.022
0.095
.
chr9
64203263
64203313
WT_rep2_peak_80
1000
+
3.430
0.000
0.000
.
chr9
65103907
65103957
WT_rep2_peak_81
1000
-
2.000
0.000
0.001
.
chr9
65103904
65103954
WT_rep2_peak_82
1000
-
2.890
0.000
0.000
.
chr9
65109058
65109108
WT_rep2_peak_83
1000
-
2.230
0.000
0.000
.
chr9
78082635
78082685
WT_rep2_peak_84
1000
-
1.080
0.000
0.001
.
chr10
111317404
111317454
WT_rep2_peak_85
1000
+
1.490
0.000
0.000
.
chr11
48753995
48754045
WT_rep2_peak_86
1000
-
3.460
0.000
0.000
.
chr11
68964303
68964353
WT_rep2_peak_87
1000
+
1.700
0.000
0.000
.
chr11
69558710
69558760
WT_rep2_peak_88
1000
-
2.680
0.000
0.000
.
chr11
87313741
87313791
WT_rep2_peak_89
1000
+
2.110
0.000
0.029
.
chr11
87313743
87313793
WT_rep2_peak_90
1000
+
3.280
0.000
0.000
.
chr11
87317592
87317642
WT_rep2_peak_91
1000
+
0.780
0.001
0.003
.
chr11
97672515
97672565
WT_rep2_peak_92
1000
-
1.440
0.000
0.000
.
chr11
106391819
106391869
WT_rep2_peak_93
1000
+
1.930
0.000
0.000
.
chr11
116968174
116968224
WT_rep2_peak_94
1000
+
3.040
0.000
0.000
.
chr12
54776430
54776480
WT_rep2_peak_95
1000
+
0.930
0.000
0.000
.
chr12
69206068
69206118
WT_rep2_peak_96
1000
+
1.710
0.006
0.009
.
chr12
69206118
69206168
WT_rep2_peak_97
1000
+
1.190
0.000
0.000
.
chr12
69206218
69206268
WT_rep2_peak_98
1000
+
1.940
0.000
0.000
.
chr12
69206268
69206318
WT_rep2_peak_99
1000
+
3.120
0.000
0.000
.
chr12
69206069
69206119
WT_rep2_peak_100
1000
+
1.740
0.005
0.007
.
chr12
69206119
69206169
WT_rep2_peak_101
1000
+
1.150
0.000
0.000
.
❯
表 4.2 Call Peak结果。{样本}.bed文件,其中包含有关被调用峰的信息。您可以在excel/WPS中打开它。各列信息为:
5. 差异Peak分析
在存在多个分组且组内有生物学重复的情况下,可以对组间进行差异Peak(differential peak)分析,以确定哪些Peak在组间存在显著差异,同时获取组内共识峰(consensus peak)。如果没有差异分析则本节内容为空。
5.1 差异Peak分析结果
存在组内生物学重复时,我们使用软件DiffBind(version 3.10)(Stark,R., & Brown,G.,2012)对样本peaks进行分析。结果详见report/result/4.diff 。后文中提到的“diff”代表组间差异,“cons”代表组内交集。
图5.1 比较组PCA图。主成分分析是将原来较多维度的指标 (peak 的分布特征),降维到较低的维度(二维),来研究样品间的主成分关系。二维PCA分析结果中,会展示主成分1(PC1) 和主成分2(PC2)分别作为 X 轴和 Y 轴的散点图,每个点代表 1 个样本。坐标轴上百分比代表主成分的贡献率,贡献率越大,说明该主成分对样本差异的解释能力越强。如果两个样本距离越远,则说明样本 peaks 分布的差异越大。 反之,则说明相应样本peaks整体分布模式越接近。所以,PCA 分析常用于评估样本重复性的好坏。理想情况下,生物学重复的样本应该聚类在一起,而不同组间应该可以区分开。
图5.2 差异Peak火山图。横坐标为log2(Fold Change),纵坐标为-log10(FDR),蓝色为显著性下调的峰,红色为显著性上调的峰,灰色为非显著性差异的峰。
6. 基因组注释
为了进一步探讨peak结合位点特征,理解染色质开放区域对基因调控的机制, 使用R包ChIPseeker(version 1.36)(Wang et al., 2022)对Peak区域进行注释,我们统计Peak在各基因功能元件分布情况,并将各个peak与基因关联。本节结果请详见位于report/result/5.anno 文件夹。
6.1 Peak 在基因组分布
Setd2-KO_FeatureDis_Pie Setd2-KO_rep1_FeatureDis_Pie Setd2-KO_rep2_FeatureDis_Pie WT_FeatureDis_Pie WT_rep1_FeatureDis_Pie WT_rep2_FeatureDis_Pie
图6.1 Peak在基因功能元件上分布饼图。
cons_FeatureDistribution diff_FeatureDistribution sample_FeatureDistribution
图6.2 各样本Peak在基因功能元件上分布比例堆叠条状图,samples代表单个样本,cons代表组内共识峰,diff代表组间差异峰。
cons_Peaks_relative_TSS sample_Peaks_relative_TSS
图6.3 各样本Peak在TSS(转录起始位点)侧翼分布比例堆叠条状图,samples代表单个样本,cons代表组内共识峰,diff代表组间差异峰,各元件内容含义见图 6.1。
6.2 Peak关联基因注释
各个样本Peak关联基因注释结果表部分内容如下,完整信息请查看report/result/5.anno/{样本名称}_PeakAnno.csv 表格。{组名}_PeakAnno.csv代表组内共识峰注释结果,{比较组}_{up/down}_PeakAnno.csv代表组间差异峰注释结果。
Setd2-KO_PeakAnno Setd2-KO_rep1_PeakAnno Setd2-KO_rep2_PeakAnno Setd2-KOvsWT_up_PeakAnno WT_PeakAnno WT_rep1_PeakAnno WT_rep2_PeakAnno
❮
chr
start
end
peaknum
annotation
geneChr
geneStart
geneEnd
geneLength
geneStrand
geneId
transcriptId
distanceToTSS
chr1
63218034
63218434
Setd2-KO_cons_peak_1
Promoter (<=1kb)
1
63218163
63218294
132
1
ENSMUSG00000064602.3
ENSMUST00000082668.3
0
chr1
118386728
118387128
Setd2-KO_cons_peak_2
Promoter (<=1kb)
1
118386871
118386995
125
2
ENSMUSG00000080542.3
ENSMUST00000116892.3
0
chr1
143654523
143654923
Setd2-KO_cons_peak_3
Promoter (<=1kb)
1
143654666
143654800
135
1
ENSMUSG00000088323.3
ENSMUST00000157698.3
0
chr1
153385166
153385566
Setd2-KO_cons_peak_4
Intron (ENSMUST00000041874.9/ENSMUSG00000042684.9, intron 10 of 11)
1
153331504
153363406
31903
2
ENSMUSG00000042699.12
ENSMUST00000042141.12
-21761
chr1
160863241
160863858
Setd2-KO_cons_peak_5
Promoter (<=1kb)
1
160863331
160866109
2779
1
ENSMUSG00000053332.16
ENSMUST00000310985.1
0
chr1
160865483
160865883
Setd2-KO_cons_peak_6
Promoter (<=1kb)
1
160865652
160865728
77
1
ENSMUSG00000064968.3
ENSMUST00000083034.3
0
chr1
171330472
171330872
Setd2-KO_cons_peak_7
Promoter (<=1kb)
1
171330616
171330731
116
2
ENSMUSG00000119640.1
ENSMUST00000083099.3
0
chr1
171538548
171538948
Setd2-KO_cons_peak_8
Promoter (<=1kb)
1
171538656
171538850
195
1
ENSMUSG00000059058.8
ENSMUST00000118448.2
0
chr10
111317215
111317615
Setd2-KO_cons_peak_9
Promoter (<=1kb)
10
111317354
111317497
144
1
ENSMUSG00000087819.3
ENSMUST00000157194.3
0
chr10
121273193
121273593
Setd2-KO_cons_peak_10
Intron (ENSMUST00000026902.9/ENSMUSG00000025795.9, intron 1 of 4)
10
121250292
121298118
47827
2
ENSMUSG00000025795.9
ENSMUST00000219500.2
24525
chr11
48753819
48754219
Setd2-KO_cons_peak_11
Exon (ENSMUST00000147151.2/ENSMUSG00000046879.8, exon 2 of 2)
11
48745257
48749020
3764
2
ENSMUSG00000132080.1
ENSMUST00000310045.1
-4800
chr11
55373405
55373805
Setd2-KO_cons_peak_12
Promoter (<=1kb)
11
55373520
55373659
140
1
ENSMUSG00000065061.3
ENSMUST00000083127.3
0
chr11
68964146
68964546
Setd2-KO_cons_peak_13
Promoter (<=1kb)
11
68964253
68964387
135
1
ENSMUSG00000064899.3
ENSMUST00000082965.3
0
chr11
69558547
69558947
Setd2-KO_cons_peak_14
Promoter (<=1kb)
11
69558208
69558889
682
2
ENSMUSG00000059796.17
ENSMUST00000140186.2
0
chr11
69559555
69559955
Setd2-KO_cons_peak_15
Promoter (<=1kb)
11
69559678
69559821
144
2
ENSMUSG00000089542.3
ENSMUST00000158917.3
0
chr11
87313590
87313990
Setd2-KO_cons_peak_16
Promoter (<=1kb)
11
87313693
87313856
164
1
ENSMUSG00000119476.1
ENSMUST00000240501.1
0
chr11
87317393
87317793
Setd2-KO_cons_peak_17
Promoter (<=1kb)
11
87317542
87317705
164
1
ENSMUSG00000118815.1
ENSMUST00000093684.3
0
chr11
97672347
97672747
Setd2-KO_cons_peak_18
Promoter (<=1kb)
11
97672465
97672601
137
2
ENSMUSG00000064901.3
ENSMUST00000082967.3
0
chr11
106391659
106392059
Setd2-KO_cons_peak_19
Promoter (<=1kb)
11
106391819
106391888
70
1
ENSMUSG00000065126.3
ENSMUST00000083192.3
0
chr11
116967982
116968382
Setd2-KO_cons_peak_20
Promoter (<=1kb)
11
116968004
116969781
1778
1
ENSMUSG00000086859.7
ENSMUST00000328767.1
0
chr12
17595999
17596399
Setd2-KO_cons_peak_21
Promoter (<=1kb)
12
17596147
17596282
136
1
ENSMUSG00000064427.3
ENSMUST00000082493.3
0
chr12
54765889
54766289
Setd2-KO_cons_peak_22
Promoter (<=1kb)
12
54765941
54766104
164
2
ENSMUSG00000118864.1
ENSMUST00001239507.1
0
chr12
54776246
54776646
Setd2-KO_cons_peak_23
Promoter (<=1kb)
12
54776380
54776543
164
1
ENSMUSG00000118751.1
ENSMUST00000240287.1
0
chr12
69205968
69206419
Setd2-KO_cons_peak_24
Promoter (<=1kb)
12
69206069
69206368
300
1
ENSMUSG00000118866.1
ENSMUST00000175032.4
0
chr12
69407904
69408406
Setd2-KO_cons_peak_25
Promoter (<=1kb)
12
69407956
69408255
300
2
ENSMUSG00000118841.1
ENSMUST00000174924.4
0
chr12
109510270
109510670
Setd2-KO_cons_peak_26
Promoter (<=1kb)
12
109510424
109510503
80
1
ENSMUSG00000084535.3
ENSMUST00000122586.3
0
chr13
22015963
22016363
Setd2-KO_cons_peak_27
Promoter (<=1kb)
13
22015937
22016366
430
2
ENSMUSG00000069305.4
ENSMUST00000102979.2
3
chr13
22220133
22220533
Setd2-KO_cons_peak_28
Promoter (<=1kb)
13
22220040
22220515
476
1
ENSMUSG00000062727.5
ENSMUST00000110455.4
94
chr13
22225177
22225577
Setd2-KO_cons_peak_29
Promoter (<=1kb)
13
22224806
22225532
727
2
ENSMUSG00000060639.6
ENSMUST00000102977.4
0
chr13
23715188
23715588
Setd2-KO_cons_peak_30
Promoter (<=1kb)
13
23715220
23715689
470
1
ENSMUSG00000060981.8
ENSMUST00000102972.6
0
chr13
23930873
23931273
Setd2-KO_cons_peak_31
Promoter (<=1kb)
13
23930717
23931224
508
1
ENSMUSG00000075031.5
ENSMUST00000099703.5
157
chr13
51802121
51802521
Setd2-KO_cons_peak_32
Promoter (<=1kb)
13
51802235
51802370
136
1
ENSMUSG00000064672.3
ENSMUST00000082738.3
0
chr13
97150416
97150816
Setd2-KO_cons_peak_33
Promoter (<=1kb)
13
97151393
97151807
415
2
ENSMUSG00000113934.2
ENSMUST00000222278.2
991
chr13
108807642
108808042
Setd2-KO_cons_peak_34
Promoter (<=1kb)
13
108807137
108807931
795
1
ENSMUSG00000059751.8
ENSMUST00000074680.8
506
chr14
51044755
51045356
Setd2-KO_cons_peak_35
Promoter (<=1kb)
14
51045298
51058758
13461
1
ENSMUSG00000036023.7
ENSMUST00000036126.7
0
chr14
64991235
64991635
Setd2-KO_cons_peak_36
Promoter (<=1kb)
14
64991367
64991501
135
1
ENSMUSG00000064442.3
ENSMUST00000082508.3
0
chr15
34440813
34441213
Setd2-KO_cons_peak_37
Promoter (<=1kb)
15
34440937
34441068
132
2
ENSMUSG00000065899.3
ENSMUST00000083965.3
0
chr15
83033716
83034116
Setd2-KO_cons_peak_38
Promoter (<=1kb)
15
83033845
83033995
151
1
ENSMUSG00000065176.3
ENSMUST00000083242.3
0
chr15
98417451
98417851
Setd2-KO_cons_peak_39
Promoter (<=1kb)
15
98417643
98417759
117
2
ENSMUSG00000106463.3
ENSMUST00000199842.3
0
chr15
98424094
98424494
Setd2-KO_cons_peak_40
Promoter (<=1kb)
15
98424227
98424363
137
2
ENSMUSG00000065939.3
ENSMUST00000084005.3
0
chr16
10961801
10962253
Setd2-KO_cons_peak_41
Promoter (<=1kb)
16
10961986
10968469
6484
1
ENSMUSG00000141422.1
ENSMUST00000365190.1
0
chr16
18351787
18352187
Setd2-KO_cons_peak_42
Intron (ENSMUST00000231621.2/ENSMUSG00000000884.18, intron 2 of 7)
16
18367493
18371334
3842
1
ENSMUSG00000000884.18
ENSMUST00000151253.2
-15306
chr16
22927509
22927909
Setd2-KO_cons_peak_43
Promoter (<=1kb)
16
22927703
22927771
69
1
ENSMUSG00000088524.3
ENSMUST00000157899.3
0
chr16
22929392
22929792
Setd2-KO_cons_peak_44
Promoter (<=1kb)
16
22929422
22930690
1269
1
ENSMUSG00000022884.17
ENSMUST00000150117.2
0
chr16
22929906
22930633
Setd2-KO_cons_peak_45
Promoter (<=1kb)
16
22930051
22930179
129
1
ENSMUSG00000064382.3
ENSMUST00000082448.3
0
chr16
30687753
30688153
Setd2-KO_cons_peak_46
Promoter (<=1kb)
16
30687849
30688952
1104
2
ENSMUSG00000116951.3
ENSMUST00000304664.1
799
chr16
32062399
32062799
Setd2-KO_cons_peak_47
Promoter (<=1kb)
16
32062530
32062673
144
2
ENSMUSG00000080440.3
ENSMUST00000116790.3
0
chr16
55855973
55856373
Setd2-KO_cons_peak_48
Promoter (<=1kb)
16
55856116
55856250
135
2
ENSMUSG00000064994.3
ENSMUST00000083060.3
0
chr17
24938535
24938940
Setd2-KO_cons_peak_49
Promoter (<=1kb)
17
24938650
24938777
128
2
ENSMUSG00000089255.3
ENSMUST00000158630.3
0
chr17
24939617
24940017
Setd2-KO_cons_peak_50
Promoter (<=1kb)
17
24939797
24940841
1045
1
ENSMUSG00000044533.16
ENSMUST00000129580.2
0
chr17
35170798
35171198
Setd2-KO_cons_peak_51
Promoter (<=1kb)
17
35154724
35170952
16229
2
ENSMUSG00000092203.10
ENSMUST00000371044.1
0
chr17
40157093
40157787
Setd2-KO_cons_peak_52
Promoter (<=1kb)
17
40157244
40159092
1849
1
ENSMUSG00000119584.1
ENSMUST00000240377.1
0
chr17
40158190
40159287
Setd2-KO_cons_peak_53
Promoter (<=1kb)
17
40157244
40159092
1849
1
ENSMUSG00000119584.1
ENSMUST00000240377.1
947
chr18
10150877
10151277
Setd2-KO_cons_peak_54
Promoter (<=1kb)
18
10150977
10151140
164
2
ENSMUSG00000095616.2
ENSMUST00000083435.3
0
chr18
14780732
14781132
Setd2-KO_cons_peak_55
Promoter (<=1kb)
18
14780824
14780987
164
2
ENSMUSG00000094306.3
ENSMUST00000084007.4
0
chr18
33928075
33928475
Setd2-KO_cons_peak_56
Promoter (<=1kb)
18
33928173
33929044
872
1
ENSMUSG00000087590.5
ENSMUST00000335104.1
0
chr18
35687407
35687807
Setd2-KO_cons_peak_57
Promoter (<=1kb)
18
35687620
35687689
70
1
ENSMUSG00000105743.3
ENSMUST00000199259.3
0
chr19
8701444
8701844
Setd2-KO_cons_peak_58
Promoter (<=1kb)
19
8701615
8701689
75
1
ENSMUSG00000065392.3
ENSMUST00000083458.3
0
chr19
8702274
8702674
Setd2-KO_cons_peak_59
Promoter (<=1kb)
19
8702456
8702520
65
1
ENSMUSG00000065378.3
ENSMUST00000083444.3
0
chr2
19307987
19308387
Setd2-KO_cons_peak_60
Intron (ENSMUST00000049255.7/ENSMUSG00000037683.15, intron 17 of 18)
2
19344481
19349004
4524
2
ENSMUSG00000124341.1
ENSMUST00000263154.1
40617
chr2
26527744
26528144
Setd2-KO_cons_peak_61
Promoter (<=1kb)
2
26527860
26527986
127
2
ENSMUSG00000064858.4
ENSMUST00000082924.4
0
chr2
27429692
27430092
Setd2-KO_cons_peak_62
Promoter (<=1kb)
2
27429817
27429942
126
2
ENSMUSG00000080538.3
ENSMUST00000116888.3
0
chr2
102914594
102914994
Setd2-KO_cons_peak_63
Promoter (1-2kb)
2
102913302
102922135
8834
1
ENSMUSG00000010911.13
ENSMUST00000155004.2
1293
chr2
130118022
130118422
Setd2-KO_cons_peak_64
Promoter (<=1kb)
2
130118079
130120883
2805
1
ENSMUSG00000027405.17
ENSMUST00000149955.9
0
chr2
144103384
144103784
Setd2-KO_cons_peak_65
Promoter (<=1kb)
2
144103509
144103646
138
2
ENSMUSG00000065725.3
ENSMUST00000083791.3
0
chr2
158201571
158201971
Setd2-KO_cons_peak_66
Promoter (<=1kb)
2
158201718
158201849
132
2
ENSMUSG00000064405.3
ENSMUST00000082471.3
0
chr2
166907017
166907417
Setd2-KO_cons_peak_67
Promoter (<=1kb)
2
166907196
166907285
90
1
ENSMUSG00000077698.3
ENSMUST00000104510.3
0
chr3
88707049
88707449
Setd2-KO_cons_peak_68
Exon (ENSMUST00000253106.1/ENSMUSG00000122440.1, exon 6 of 6)
3
88724693
88728201
3509
1
ENSMUSG00000122565.1
ENSMUST00000253674.1
-17244
chr3
96147104
96147504
Setd2-KO_cons_peak_69
Promoter (<=1kb)
3
96147184
96147321
138
1
ENSMUSG00002076697.1
ENSMUST00020181968.1
0
chr3
96152916
96153316
Setd2-KO_cons_peak_70
Promoter (<=1kb)
3
96153142
96153279
138
2
ENSMUSG00002076967.1
ENSMUST00020182038.1
0
chr3
96176957
96177549
Setd2-KO_cons_peak_71
Promoter (<=1kb)
3
96177037
96186317
9281
1
ENSMUSG00000050936.7
ENSMUST00000051089.4
0
chr3
96235632
96236032
Setd2-KO_cons_peak_72
Promoter (<=1kb)
3
96235741
96235906
166
1
ENSMUSG00000119427.1
ENSMUST00000239827.1
0
chr3
96281198
96281598
Setd2-KO_cons_peak_73
Promoter (<=1kb)
3
96281337
96281501
165
1
ENSMUSG00000119030.1
ENSMUST00000240438.1
0
chr3
96357653
96358053
Setd2-KO_cons_peak_74
Promoter (<=1kb)
3
96357762
96357927
166
1
ENSMUSG00000119774.1
ENSMUST00000083839.3
0
chr3
96367289
96367689
Setd2-KO_cons_peak_75
Promoter (<=1kb)
3
96367340
96367505
166
2
ENSMUSG00000118677.1
ENSMUST00000240510.1
0
chr3
123301473
123301873
Setd2-KO_cons_peak_76
Promoter (<=1kb)
3
123301586
123301715
130
2
ENSMUSG00000092730.3
ENSMUST00000174989.3
0
chr3
153616005
153616405
Setd2-KO_cons_peak_77
Promoter (<=1kb)
3
153616200
153616270
71
2
ENSMUSG00000064731.3
ENSMUST00000082797.3
0
chr3
153617597
153617997
Setd2-KO_cons_peak_78
Promoter (<=1kb)
3
153612924
153617948
5025
2
ENSMUSG00000038975.15
ENSMUST00000197438.5
0
chr4
43492725
43493125
Setd2-KO_cons_peak_79
Promoter (<=1kb)
4
43492900
43494205
1306
1
ENSMUSG00000028461.13
ENSMUST00000143073.8
0
chr4
119226939
119227339
Setd2-KO_cons_peak_80
Intron (ENSMUST00000238759.2/ENSMUSG00000028637.17, intron 5 of 14)
4
119209443
119230950
21508
2
ENSMUSG00000028637.17
ENSMUST00000238779.2
3611
chr4
131997261
131997661
Setd2-KO_cons_peak_81
Promoter (<=1kb)
4
131997391
131997524
134
2
ENSMUSG00000077323.3
ENSMUST00000104135.3
0
chr4
132037405
132037805
Setd2-KO_cons_peak_82
Promoter (<=1kb)
4
132037551
132037680
130
1
ENSMUSG00000064949.3
ENSMUST00000083015.3
0
chr5
74254042
74254442
Setd2-KO_cons_peak_83
Promoter (<=1kb)
5
74254191
74254311
121
1
ENSMUSG00000093355.3
ENSMUST00000175614.3
0
chr5
115627366
115627766
Setd2-KO_cons_peak_84
Promoter (<=1kb)
5
115627518
115627658
141
1
ENSMUSG00000119520.1
ENSMUST00000239680.1
0
chr5
118567548
118567948
Setd2-KO_cons_peak_85
Intron (ENSMUST00000279925.1/ENSMUSG00000127080.1, intron 1 of 1)
5
118563375
118571739
8365
1
ENSMUSG00000127080.1
ENSMUST00000279925.1
4174
chr5
121342929
121343329
Setd2-KO_cons_peak_86
Promoter (<=1kb)
5
121343073
121343206
134
1
ENSMUSG00000064841.3
ENSMUST00000082907.3
0
chr5
125485899
125486299
Setd2-KO_cons_peak_87
Promoter (<=1kb)
5
125483388
125486552
3165
2
ENSMUSG00000132160.1
ENSMUST00000310468.1
253
chr5
129871464
129871864
Setd2-KO_cons_peak_88
Promoter (<=1kb)
5
129871609
129871739
131
1
ENSMUSG00000093413.3
ENSMUST00000177461.3
0
chr5
146771806
146772206
Setd2-KO_cons_peak_89
Promoter (<=1kb)
5
146772016
146772796
781
1
ENSMUSG00000041453.13
ENSMUST00000135345.2
0
chr6
3201344
3201744
Setd2-KO_cons_peak_90
Intron (ENSMUST00000318661.1/ENSMUSG00000133541.1, intron 3 of 3)
6
3207869
3208706
838
1
ENSMUSG00000107601.2
ENSMUST00000203560.2
-6125
chr6
47755027
47755427
Setd2-KO_cons_peak_91
Promoter (<=1kb)
6
47755311
47757431
2121
1
ENSMUSG00000126201.1
ENSMUST00000275052.1
0
chr6
69493265
69493665
Setd2-KO_cons_peak_92
Promoter (<=1kb)
6
69493323
69493613
291
1
ENSMUSG00000092746.5
ENSMUST00000175005.5
0
chr6
71101581
71101981
Setd2-KO_cons_peak_93
Promoter (<=1kb)
6
71101594
71101947
354
1
ENSMUSG00000068396.10
ENSMUST00000121998.2
0
chr6
71859402
71859802
Setd2-KO_cons_peak_94
Promoter (<=1kb)
6
71857622
71859579
1958
2
ENSMUSG00000063884.7
ENSMUST00000205269.2
0
chr6
124692151
124692551
Setd2-KO_cons_peak_95
Promoter (<=1kb)
6
124692311
124693913
1603
1
ENSMUSG00000004264.18
ENSMUST00000143000.8
0
chr6
125098567
125098967
Setd2-KO_cons_peak_96
Promoter (<=1kb)
6
125098687
125098822
136
1
ENSMUSG00000088208.3
ENSMUST00000157583.3
0
chr6
136780969
136781369
Setd2-KO_cons_peak_97
Promoter (<=1kb)
6
136778551
136781413
2863
2
ENSMUSG00000096010.3
ENSMUST00000179285.3
44
chr7
44776096
44776496
Setd2-KO_cons_peak_98
Promoter (<=1kb)
7
44775347
44776303
957
2
ENSMUSG00000074129.15
ENSMUST00000210792.2
0
chr7
99128628
99129028
Setd2-KO_cons_peak_99
Promoter (<=1kb)
7
99128770
99128914
145
2
ENSMUSG00000064966.3
ENSMUST00000083032.3
0
chr7
99131861
99132261
Setd2-KO_cons_peak_100
Promoter (<=1kb)
7
99131992
99132139
148
2
ENSMUSG00000065822.3
ENSMUST00000083888.3
0
chr
start
end
peaknum
annotation
geneChr
geneStart
geneEnd
geneLength
geneStrand
geneId
transcriptId
distanceToTSS
chr1
45892483
45892533
Setd2-KO_rep1_peak_1
Intron (ENSMUST00000256796.1/ENSMUSG00000123184.1, intron 2 of 2)
1
45896492
45896914
423
2
ENSMUSG00000084817.4
ENSMUST00000153604.2
4381
chr1
54288281
54288331
Setd2-KO_rep1_peak_2
Promoter (<=1kb)
1
54288261
54288367
107
2
ENSMUSG00000119657.1
ENSMUST00000239682.1
36
chr1
63218213
63218263
Setd2-KO_rep1_peak_3
Promoter (<=1kb)
1
63218163
63218294
132
1
ENSMUSG00000064602.3
ENSMUST00000082668.3
51
chr1
65033660
65033710
Setd2-KO_rep1_peak_4
Promoter (<=1kb)
1
65033110
65033763
654
2
ENSMUSG00000084416.4
ENSMUST00000120360.2
53
chr1
86015073
86015123
Setd2-KO_rep1_peak_5
Promoter (<=1kb)
1
86015023
86015144
122
1
ENSMUSG00000077274.3
ENSMUST00000104086.3
51
chr1
86283983
86284033
Setd2-KO_rep1_peak_6
Promoter (<=1kb)
1
86283983
86284052
70
2
ENSMUSG00000064823.3
ENSMUST00000082889.3
19
chr1
118386921
118386971
Setd2-KO_rep1_peak_7
Promoter (<=1kb)
1
118386871
118386995
125
2
ENSMUSG00000080542.3
ENSMUST00000116892.3
24
chr1
153385361
153385411
Setd2-KO_rep1_peak_8
Intron (ENSMUST00000041874.9/ENSMUSG00000042684.9, intron 10 of 11)
1
153331504
153363406
31903
2
ENSMUSG00000042699.12
ENSMUST00000042141.12
-21956
chr1
160863420
160863470
Setd2-KO_rep1_peak_9
Promoter (<=1kb)
1
160863420
160863481
62
1
ENSMUSG00000080463.3
ENSMUST00000116813.3
1
chr1
160863627
160863677
Setd2-KO_rep1_peak_10
Promoter (<=1kb)
1
160863627
160863709
83
1
ENSMUSG00000064816.3
ENSMUST00000082882.3
1
chr1
171330666
171330716
Setd2-KO_rep1_peak_11
Promoter (<=1kb)
1
171330616
171330731
116
2
ENSMUSG00000119640.1
ENSMUST00000083099.3
15
chr1
171538706
171538756
Setd2-KO_rep1_peak_12
Promoter (<=1kb)
1
171538656
171538850
195
1
ENSMUSG00000059058.8
ENSMUST00000118448.2
51
chr2
19308163
19308213
Setd2-KO_rep1_peak_13
Intron (ENSMUST00000049255.7/ENSMUSG00000037683.15, intron 17 of 18)
2
19344481
19349004
4524
2
ENSMUSG00000124341.1
ENSMUST00000263154.1
40791
chr2
23046618
23046668
Setd2-KO_rep1_peak_14
Promoter (<=1kb)
2
23046540
23050627
4088
1
ENSMUSG00000026775.10
ENSMUST00000149240.2
79
chr2
26527909
26527959
Setd2-KO_rep1_peak_15
Promoter (<=1kb)
2
26527860
26527986
127
2
ENSMUSG00000064858.4
ENSMUST00000082924.4
27
chr2
26527910
26527960
Setd2-KO_rep1_peak_16
Promoter (<=1kb)
2
26527860
26527986
127
2
ENSMUSG00000064858.4
ENSMUST00000082924.4
26
chr2
27429867
27429917
Setd2-KO_rep1_peak_17
Promoter (<=1kb)
2
27429817
27429942
126
2
ENSMUSG00000080538.3
ENSMUST00000116888.3
25
chr2
130118207
130118257
Setd2-KO_rep1_peak_18
Promoter (<=1kb)
2
130118220
130119490
1271
1
ENSMUSG00000027405.17
ENSMUST00000160976.2
0
chr2
158201768
158201818
Setd2-KO_rep1_peak_19
Promoter (<=1kb)
2
158197699
158201807
4109
2
ENSMUSG00000085385.10
ENSMUST00000341371.1
0
chr3
83737625
83737675
Setd2-KO_rep1_peak_20
Intron (ENSMUST00000193706.3/ENSMUSG00000104082.3, intron 6 of 6)
3
83743579
83749074
5496
2
ENSMUSG00000027995.11
ENSMUST00000029623.11
11399
chr3
88707229
88707279
Setd2-KO_rep1_peak_21
Exon (ENSMUST00000253106.1/ENSMUSG00000122440.1, exon 6 of 6)
3
88724693
88728201
3509
1
ENSMUSG00000122565.1
ENSMUST00000253674.1
-17414
chr3
96177368
96177418
Setd2-KO_rep1_peak_22
Promoter (<=1kb)
3
96174391
96177605
3215
2
ENSMUSG00000093656.2
ENSMUST00000177363.2
187
chr3
96235791
96235841
Setd2-KO_rep1_peak_23
Promoter (<=1kb)
3
96235741
96235906
166
1
ENSMUSG00000119427.1
ENSMUST00000239827.1
51
chr3
96281387
96281437
Setd2-KO_rep1_peak_24
Promoter (<=1kb)
3
96281337
96281501
165
1
ENSMUSG00000119030.1
ENSMUST00000240438.1
51
chr3
96357804
96357854
Setd2-KO_rep1_peak_25
Promoter (<=1kb)
3
96357762
96357927
166
1
ENSMUSG00000119774.1
ENSMUST00000083839.3
43
chr3
96367424
96367474
Setd2-KO_rep1_peak_26
Promoter (<=1kb)
3
96367340
96367505
166
2
ENSMUSG00000118677.1
ENSMUST00000240510.1
31
chr3
96367440
96367490
Setd2-KO_rep1_peak_27
Promoter (<=1kb)
3
96367340
96367505
166
2
ENSMUSG00000118677.1
ENSMUST00000240510.1
15
chr3
123301636
123301686
Setd2-KO_rep1_peak_28
Promoter (<=1kb)
3
123301586
123301715
130
2
ENSMUSG00000092730.3
ENSMUST00000174989.3
29
chr3
153616200
153616250
Setd2-KO_rep1_peak_29
Promoter (<=1kb)
3
153616200
153616270
71
2
ENSMUSG00000064731.3
ENSMUST00000082797.3
20
chr3
153617247
153617297
Setd2-KO_rep1_peak_30
Promoter (<=1kb)
3
153617247
153617327
81
2
ENSMUSG00000065738.3
ENSMUST00000083804.3
30
chr3
153617762
153617812
Setd2-KO_rep1_peak_31
Promoter (<=1kb)
3
153612926
153617782
4857
2
ENSMUSG00000038975.15
ENSMUST00000167111.6
0
chr4
3835079
3835129
Setd2-KO_rep1_peak_32
Promoter (<=1kb)
4
3835079
3835146
68
2
ENSMUSG00000088351.2
ENSMUST00000157726.2
17
chr4
43492833
43492883
Setd2-KO_rep1_peak_33
Promoter (<=1kb)
4
43492900
43494205
1306
1
ENSMUSG00000028461.13
ENSMUST00000143073.8
-17
chr4
43492838
43492888
Setd2-KO_rep1_peak_34
Promoter (<=1kb)
4
43492900
43494205
1306
1
ENSMUSG00000028461.13
ENSMUST00000143073.8
-12
chr4
86504740
86504790
Setd2-KO_rep1_peak_35
Promoter (<=1kb)
4
86504690
86504820
131
2
ENSMUSG00000088958.3
ENSMUST00000158333.3
30
chr4
117059776
117059826
Setd2-KO_rep1_peak_36
Promoter (<=1kb)
4
117059725
117059840
116
1
ENSMUSG00000119142.1
ENSMUST00000240200.1
52
chr4
117059775
117059825
Setd2-KO_rep1_peak_37
Promoter (<=1kb)
4
117059725
117059840
116
1
ENSMUSG00000119142.1
ENSMUST00000240200.1
51
chr4
119227113
119227163
Setd2-KO_rep1_peak_38
Intron (ENSMUST00000238759.2/ENSMUSG00000028637.17, intron 5 of 14)
4
119209443
119230950
21508
2
ENSMUSG00000028637.17
ENSMUST00000238779.2
3787
chr4
131997445
131997495
Setd2-KO_rep1_peak_39
Promoter (<=1kb)
4
131997391
131997524
134
2
ENSMUSG00000077323.3
ENSMUST00000104135.3
29
chr4
132037601
132037651
Setd2-KO_rep1_peak_40
Promoter (<=1kb)
4
132037572
132038335
764
1
ENSMUSG00000086290.12
ENSMUST00000303243.1
30
chr4
132038002
132038052
Setd2-KO_rep1_peak_41
Promoter (<=1kb)
4
132038002
132038075
74
1
ENSMUSG00000080615.3
ENSMUST00000116965.3
1
chr5
74254241
74254291
Setd2-KO_rep1_peak_42
Promoter (<=1kb)
5
74254191
74254311
121
1
ENSMUSG00000093355.3
ENSMUST00000175614.3
51
chr5
115627518
115627568
Setd2-KO_rep1_peak_43
Promoter (<=1kb)
5
115627518
115628584
1067
1
ENSMUSG00000132950.1
ENSMUST00000315073.1
1
chr5
115627518
115627568
Setd2-KO_rep1_peak_44
Promoter (<=1kb)
5
115627518
115628584
1067
1
ENSMUSG00000132950.1
ENSMUST00000315073.1
1
chr5
115628313
115628363
Setd2-KO_rep1_peak_45
Promoter (<=1kb)
5
115628313
115628453
141
1
ENSMUSG00000119132.1
ENSMUST00000240114.1
1
chr5
121343144
121343194
Setd2-KO_rep1_peak_46
Promoter (<=1kb)
5
121343073
121343206
134
1
ENSMUSG00000064841.3
ENSMUST00000082907.3
72
chr5
129871659
129871709
Setd2-KO_rep1_peak_47
Promoter (<=1kb)
5
129871609
129871739
131
1
ENSMUSG00000093413.3
ENSMUST00000177461.3
51
chr5
146772004
146772054
Setd2-KO_rep1_peak_48
Promoter (<=1kb)
5
146772016
146772796
781
1
ENSMUSG00000041453.13
ENSMUST00000135345.2
0
chr6
3201494
3201544
Setd2-KO_rep1_peak_49
Intron (ENSMUST00000318661.1/ENSMUSG00000133541.1, intron 3 of 3)
6
3207869
3208706
838
1
ENSMUSG00000107601.2
ENSMUST00000203560.2
-6325
chr6
3201544
3201594
Setd2-KO_rep1_peak_50
Intron (ENSMUST00000318661.1/ENSMUSG00000133541.1, intron 3 of 3)
6
3207869
3208706
838
1
ENSMUSG00000107601.2
ENSMUST00000203560.2
-6275
chr6
47755215
47755265
Setd2-KO_rep1_peak_51
Promoter (<=1kb)
6
47755311
47757431
2121
1
ENSMUSG00000126201.1
ENSMUST00000275052.1
-46
chr6
47758619
47758669
Setd2-KO_rep1_peak_52
Promoter (<=1kb)
6
47758558
47758659
102
1
ENSMUSG00000064945.3
ENSMUST00000083011.3
62
chr6
71101744
71101794
Setd2-KO_rep1_peak_53
Promoter (<=1kb)
6
71101594
71101947
354
1
ENSMUSG00000068396.10
ENSMUST00000121998.2
151
chr6
71101844
71101894
Setd2-KO_rep1_peak_54
Promoter (<=1kb)
6
71101594
71101947
354
1
ENSMUSG00000068396.10
ENSMUST00000121998.2
251
chr6
71859591
71859641
Setd2-KO_rep1_peak_55
Promoter (<=1kb)
6
71857622
71859579
1958
2
ENSMUSG00000063884.7
ENSMUST00000205269.2
-13
chr6
125098737
125098787
Setd2-KO_rep1_peak_56
Promoter (<=1kb)
6
125098687
125098822
136
1
ENSMUSG00000088208.3
ENSMUST00000157583.3
51
chr6
128775848
128775898
Setd2-KO_rep1_peak_57
Promoter (<=1kb)
6
128775914
128778051
2138
1
ENSMUSG00000128635.1
ENSMUST00000288904.1
-16
chr6
136781051
136781101
Setd2-KO_rep1_peak_58
Promoter (<=1kb)
6
136780911
136781425
515
1
ENSMUSG00000125305.1
ENSMUST00000269361.1
141
chr6
136781151
136781201
Setd2-KO_rep1_peak_59
Promoter (<=1kb)
6
136778551
136781413
2863
2
ENSMUSG00000096010.3
ENSMUST00000179285.3
212
chr7
44776288
44776338
Setd2-KO_rep1_peak_60
Promoter (<=1kb)
7
44775347
44776303
957
2
ENSMUSG00000074129.15
ENSMUST00000210792.2
0
chr7
44776342
44776392
Setd2-KO_rep1_peak_61
Promoter (<=1kb)
7
44776288
44776371
84
2
ENSMUSG00002076766.1
ENSMUST00020182787.1
0
chr7
81179653
81179703
Setd2-KO_rep1_peak_62
Promoter (<=1kb)
7
81179664
81179736
73
1
ENSMUSG00000104618.3
ENSMUST00000196359.3
0
chr7
81179664
81179714
Setd2-KO_rep1_peak_63
Promoter (<=1kb)
7
81179664
81179736
73
1
ENSMUSG00000104618.3
ENSMUST00000196359.3
1
chr7
99128820
99128870
Setd2-KO_rep1_peak_64
Promoter (<=1kb)
7
99128770
99128914
145
2
ENSMUSG00000064966.3
ENSMUST00000083032.3
44
chr7
99132042
99132092
Setd2-KO_rep1_peak_65
Promoter (<=1kb)
7
99131992
99132139
148
2
ENSMUSG00000065822.3
ENSMUST00000083888.3
47
chr7
109119377
109119427
Setd2-KO_rep1_peak_66
Promoter (<=1kb)
7
109119327
109119458
132
1
ENSMUSG00000065016.3
ENSMUST00000083082.3
51
chr7
109120537
109120587
Setd2-KO_rep1_peak_67
Promoter (<=1kb)
7
109120487
109120616
130
1
ENSMUSG00000077575.3
ENSMUST00000104387.3
51
chr7
127127096
127127146
Setd2-KO_rep1_peak_68
Promoter (<=1kb)
7
127127046
127127175
130
1
ENSMUSG00000065259.3
ENSMUST00000083325.3
51
chr7
141028766
141028816
Setd2-KO_rep1_peak_69
Promoter (<=1kb)
7
141028716
141028852
137
1
ENSMUSG00000064666.3
ENSMUST00000082732.3
51
chr8
3853269
3853319
Setd2-KO_rep1_peak_70
Promoter (<=1kb)
8
3853069
3853358
290
2
ENSMUSG00000088025.3
ENSMUST00000157400.3
39
chr8
13926141
13926191
Setd2-KO_rep1_peak_71
Promoter (<=1kb)
8
13926097
13926226
130
1
ENSMUSG00000065817.3
ENSMUST00000083883.3
45
chr8
13926147
13926197
Setd2-KO_rep1_peak_72
Promoter (<=1kb)
8
13926097
13926226
130
1
ENSMUSG00000065817.3
ENSMUST00000083883.3
51
chr8
31639892
31639942
Setd2-KO_rep1_peak_73
Promoter (<=1kb)
8
31639892
31639995
104
2
ENSMUSG00000088252.3
ENSMUST00000157627.3
53
chr8
34181879
34181929
Setd2-KO_rep1_peak_74
Promoter (<=1kb)
8
34181829
34181972
144
1
ENSMUSG00000119577.1
ENSMUST00000239886.1
51
chr8
124294376
124294426
Setd2-KO_rep1_peak_75
Promoter (<=1kb)
8
124294376
124294494
119
2
ENSMUSG00000119210.1
ENSMUST00000240370.1
68
chr8
124312981
124313031
Setd2-KO_rep1_peak_76
Promoter (<=1kb)
8
124312981
124313099
119
2
ENSMUSG00001118664.1
ENSMUST00000240133.1
68
chr8
124321493
124321543
Setd2-KO_rep1_peak_77
Promoter (<=1kb)
8
124321493
124321611
119
2
ENSMUSG00000119324.1
ENSMUST00000239771.1
68
chr8
124323196
124323246
Setd2-KO_rep1_peak_78
Promoter (<=1kb)
8
124323196
124323314
119
2
ENSMUSG00000119587.1
ENSMUST00000240236.1
68
chr8
124324897
124324947
Setd2-KO_rep1_peak_79
Promoter (<=1kb)
8
124324897
124325015
119
2
ENSMUSG00000119280.1
ENSMUST00000239832.1
68
chr8
124329986
124330036
Setd2-KO_rep1_peak_80
Promoter (<=1kb)
8
124329986
124330104
119
2
ENSMUSG00000118796.1
ENSMUST00000240112.1
68
chr8
124333352
124333402
Setd2-KO_rep1_peak_81
Promoter (<=1kb)
8
124333352
124333470
119
2
ENSMUSG00000118747.1
ENSMUST00000239942.1
68
chr8
124335059
124335109
Setd2-KO_rep1_peak_82
Promoter (<=1kb)
8
124335059
124335177
119
2
ENSMUSG00000119615.1
ENSMUST00000240207.1
68
chr8
124336756
124336806
Setd2-KO_rep1_peak_83
Promoter (<=1kb)
8
124336756
124336874
119
2
ENSMUSG00000118920.1
ENSMUST00000239853.1
68
chr8
124338454
124338504
Setd2-KO_rep1_peak_84
Promoter (<=1kb)
8
124338454
124338572
119
2
ENSMUSG00000119038.1
ENSMUST00000239899.1
68
chr8
124340153
124340203
Setd2-KO_rep1_peak_85
Promoter (<=1kb)
8
124340153
124340271
119
2
ENSMUSG00000119414.1
ENSMUST00000239973.1
68
chr8
124341838
124341888
Setd2-KO_rep1_peak_86
Promoter (<=1kb)
8
124341838
124341956
119
2
ENSMUSG00000119561.1
ENSMUST00000240273.1
68
chr8
124343549
124343599
Setd2-KO_rep1_peak_87
Promoter (<=1kb)
8
124343549
124343667
119
2
ENSMUSG00000119014.1
ENSMUST00000240509.1
68
chr8
124346980
124347030
Setd2-KO_rep1_peak_88
Promoter (<=1kb)
8
124346980
124347098
119
2
ENSMUSG00000118727.1
ENSMUST00000239880.1
68
chr8
124348667
124348717
Setd2-KO_rep1_peak_89
Promoter (<=1kb)
8
124348667
124348785
119
2
ENSMUSG00000119808.1
ENSMUST00000240201.1
68
chr8
127671647
127671697
Setd2-KO_rep1_peak_90
Promoter (<=1kb)
8
127671597
127671730
134
2
ENSMUSG00000065637.3
ENSMUST00000083703.3
33
chr9
15237760
15237810
Setd2-KO_rep1_peak_91
Promoter (<=1kb)
9
15237760
15237835
76
2
ENSMUSG00000077394.3
ENSMUST00000104206.3
25
chr9
64203263
64203313
Setd2-KO_rep1_peak_92
Promoter (<=1kb)
9
64203213
64203347
135
1
ENSMUSG00000088254.3
ENSMUST00000157629.3
51
chr9
65103907
65103957
Setd2-KO_rep1_peak_93
Promoter (<=1kb)
9
65103854
65103969
116
2
ENSMUSG00000118734.1
ENSMUST00000093721.3
12
chr9
65103904
65103954
Setd2-KO_rep1_peak_94
Promoter (<=1kb)
9
65103854
65103969
116
2
ENSMUSG00000118734.1
ENSMUST00000093721.3
15
chr9
65109058
65109108
Setd2-KO_rep1_peak_95
Promoter (<=1kb)
9
65109008
65109123
116
2
ENSMUSG00000119286.1
ENSMUST00000101817.3
15
chr9
78082635
78082685
Setd2-KO_rep1_peak_96
Promoter (<=1kb)
9
78082585
78082915
331
2
ENSMUSG00002076161.1
ENSMUST00020183253.1
230
chr9
78082835
78082885
Setd2-KO_rep1_peak_97
Promoter (<=1kb)
9
78082585
78082915
331
2
ENSMUSG00002076161.1
ENSMUST00020183253.1
30
chr9
109961211
109961261
Setd2-KO_rep1_peak_98
Promoter (<=1kb)
9
109961105
110069246
108142
1
ENSMUSG00000032481.18
ENSMUST00000199896.2
107
chr9
119958505
119958555
Setd2-KO_rep1_peak_99
Promoter (<=1kb)
9
119958417
119958619
203
1
ENSMUSG00000064380.3
ENSMUST00000082446.3
89
chr9
119958525
119958575
Setd2-KO_rep1_peak_100
Promoter (<=1kb)
9
119958417
119958619
203
1
ENSMUSG00000064380.3
ENSMUST00000082446.3
109
chr
start
end
peaknum
annotation
geneChr
geneStart
geneEnd
geneLength
geneStrand
geneId
transcriptId
distanceToTSS
chr1
9644823
9644873
Setd2-KO_rep2_peak_1
Promoter (<=1kb)
1
9644773
9645874
1102
1
ENSMUSG00000081441.4
ENSMUST00000121942.2
51
chr1
63218213
63218263
Setd2-KO_rep2_peak_2
Promoter (<=1kb)
1
63218163
63218294
132
1
ENSMUSG00000064602.3
ENSMUST00000082668.3
51
chr1
118386921
118386971
Setd2-KO_rep2_peak_3
Promoter (<=1kb)
1
118386871
118386995
125
2
ENSMUSG00000080542.3
ENSMUST00000116892.3
24
chr1
143654730
143654780
Setd2-KO_rep2_peak_4
Promoter (<=1kb)
1
143654666
143654800
135
1
ENSMUSG00000088323.3
ENSMUST00000157698.3
65
chr1
143654716
143654766
Setd2-KO_rep2_peak_5
Promoter (<=1kb)
1
143654666
143654800
135
1
ENSMUSG00000088323.3
ENSMUST00000157698.3
51
chr1
157272994
157273044
Setd2-KO_rep2_peak_6
Promoter (1-2kb)
1
157274998
157278193
3196
1
ENSMUSG00000131784.1
ENSMUST00000308243.1
-1954
chr1
160864976
160865026
Setd2-KO_rep2_peak_7
Promoter (<=1kb)
1
160864926
160865009
84
1
ENSMUSG00000065160.3
ENSMUST00000083226.3
51
chr1
160865652
160865702
Setd2-KO_rep2_peak_8
Promoter (<=1kb)
1
160865652
160865728
77
1
ENSMUSG00000064968.3
ENSMUST00000083034.3
1
chr1
171538706
171538756
Setd2-KO_rep2_peak_9
Promoter (<=1kb)
1
171538656
171538850
195
1
ENSMUSG00000059058.8
ENSMUST00000118448.2
51
chr1
192427919
192427969
Setd2-KO_rep2_peak_10
Promoter (<=1kb)
1
192427879
192427994
116
1
ENSMUSG00000119403.1
ENSMUST00000082947.3
41
chr1
192427929
192427979
Setd2-KO_rep2_peak_11
Promoter (<=1kb)
1
192427879
192427994
116
1
ENSMUSG00000119403.1
ENSMUST00000082947.3
51
chr2
22634832
22634882
Setd2-KO_rep2_peak_12
Promoter (<=1kb)
2
22633932
22634630
699
2
ENSMUSG00000140457.1
ENSMUST00000359657.1
-203
chr2
26527909
26527959
Setd2-KO_rep2_peak_13
Promoter (<=1kb)
2
26527860
26527986
127
2
ENSMUSG00000064858.4
ENSMUST00000082924.4
27
chr2
26527910
26527960
Setd2-KO_rep2_peak_14
Promoter (<=1kb)
2
26527860
26527986
127
2
ENSMUSG00000064858.4
ENSMUST00000082924.4
26
chr2
26529252
26529302
Setd2-KO_rep2_peak_15
Promoter (<=1kb)
2
26529202
26529333
132
2
ENSMUSG00000077192.5
ENSMUST00000104004.5
31
chr2
27429867
27429917
Setd2-KO_rep2_peak_16
Promoter (<=1kb)
2
27429817
27429942
126
2
ENSMUSG00000080538.3
ENSMUST00000116888.3
25
chr2
102914770
102914820
Setd2-KO_rep2_peak_17
Promoter (1-2kb)
2
102913302
102922135
8834
1
ENSMUSG00000010911.13
ENSMUST00000155004.2
1469
chr2
126520990
126521040
Setd2-KO_rep2_peak_18
Intron (ENSMUST00000270226.1/ENSMUSG00000098024.4, intron 1 of 1)
2
126480556
126518257
37702
2
ENSMUSG00000027361.16
ENSMUST00000039978.13
-2734
chr2
130118207
130118257
Setd2-KO_rep2_peak_19
Promoter (<=1kb)
2
130118220
130119490
1271
1
ENSMUSG00000027405.17
ENSMUST00000160976.2
0
chr2
144103559
144103609
Setd2-KO_rep2_peak_20
Promoter (<=1kb)
2
144103509
144103646
138
2
ENSMUSG00000065725.3
ENSMUST00000083791.3
37
chr2
158201768
158201818
Setd2-KO_rep2_peak_21
Promoter (<=1kb)
2
158197699
158201807
4109
2
ENSMUSG00000085385.10
ENSMUST00000341371.1
0
chr3
10366726
10366776
Setd2-KO_rep2_peak_22
Promoter (<=1kb)
3
10309269
10366243
56975
2
ENSMUSG00000027530.16
ENSMUST00000029043.13
-484
chr3
37768939
37768989
Setd2-KO_rep2_peak_23
Promoter (<=1kb)
3
37768889
37769313
425
1
ENSMUSG00000100755.2
ENSMUST00000116115.3
51
chr3
58609800
58609850
Setd2-KO_rep2_peak_24
Intron (ENSMUST00000284097.1/ENSMUSG00000097725.6, intron 2 of 2)
3
58604982
58606089
1108
1
ENSMUSG00000105226.2
ENSMUST00000197219.2
4819
chr3
96147265
96147315
Setd2-KO_rep2_peak_25
Promoter (<=1kb)
3
96147184
96147321
138
1
ENSMUSG00002076697.1
ENSMUST00020181968.1
82
chr3
96153113
96153163
Setd2-KO_rep2_peak_26
Promoter (<=1kb)
3
96153142
96153279
138
2
ENSMUSG00002076967.1
ENSMUST00020182038.1
116
chr3
96153120
96153170
Setd2-KO_rep2_peak_27
Promoter (<=1kb)
3
96153142
96153279
138
2
ENSMUSG00002076967.1
ENSMUST00020182038.1
109
chr3
96153142
96153192
Setd2-KO_rep2_peak_28
Promoter (<=1kb)
3
96153142
96153279
138
2
ENSMUSG00002076967.1
ENSMUST00020182038.1
87
chr3
96177360
96177410
Setd2-KO_rep2_peak_29
Promoter (<=1kb)
3
96174391
96177605
3215
2
ENSMUSG00000093656.2
ENSMUST00000177363.2
195
chr3
96177141
96177191
Setd2-KO_rep2_peak_30
Promoter (<=1kb)
3
96177068
96177448
381
1
ENSMUSG00000105827.2
ENSMUST00000177113.2
74
chr3
96177318
96177368
Setd2-KO_rep2_peak_31
Promoter (<=1kb)
3
96174391
96177605
3215
2
ENSMUSG00000093656.2
ENSMUST00000177363.2
237
chr3
96177368
96177418
Setd2-KO_rep2_peak_32
Promoter (<=1kb)
3
96174391
96177605
3215
2
ENSMUSG00000093656.2
ENSMUST00000177363.2
187
chr3
96235791
96235841
Setd2-KO_rep2_peak_33
Promoter (<=1kb)
3
96235741
96235906
166
1
ENSMUSG00000119427.1
ENSMUST00000239827.1
51
chr3
96281387
96281437
Setd2-KO_rep2_peak_34
Promoter (<=1kb)
3
96281337
96281501
165
1
ENSMUSG00000119030.1
ENSMUST00000240438.1
51
chr3
96357804
96357854
Setd2-KO_rep2_peak_35
Promoter (<=1kb)
3
96357762
96357927
166
1
ENSMUSG00000119774.1
ENSMUST00000083839.3
43
chr3
96357812
96357862
Setd2-KO_rep2_peak_36
Promoter (<=1kb)
3
96357762
96357927
166
1
ENSMUSG00000119774.1
ENSMUST00000083839.3
51
chr3
96367424
96367474
Setd2-KO_rep2_peak_37
Promoter (<=1kb)
3
96367340
96367505
166
2
ENSMUSG00000118677.1
ENSMUST00000240510.1
31
chr3
96367440
96367490
Setd2-KO_rep2_peak_38
Promoter (<=1kb)
3
96367340
96367505
166
2
ENSMUSG00000118677.1
ENSMUST00000240510.1
15
chr3
123301636
123301686
Setd2-KO_rep2_peak_39
Promoter (<=1kb)
3
123301586
123301715
130
2
ENSMUSG00000092730.3
ENSMUST00000174989.3
29
chr3
153616200
153616250
Setd2-KO_rep2_peak_40
Promoter (<=1kb)
3
153616200
153616270
71
2
ENSMUSG00000064731.3
ENSMUST00000082797.3
20
chr4
43492833
43492883
Setd2-KO_rep2_peak_41
Promoter (<=1kb)
4
43492900
43494205
1306
1
ENSMUSG00000028461.13
ENSMUST00000143073.8
-17
chr4
43492838
43492888
Setd2-KO_rep2_peak_42
Promoter (<=1kb)
4
43492900
43494205
1306
1
ENSMUSG00000028461.13
ENSMUST00000143073.8
-12
chr4
119227113
119227163
Setd2-KO_rep2_peak_43
Intron (ENSMUST00000238759.2/ENSMUSG00000028637.17, intron 5 of 14)
4
119209443
119230950
21508
2
ENSMUSG00000028637.17
ENSMUST00000238779.2
3787
chr4
125398231
125398281
Setd2-KO_rep2_peak_44
Promoter (<=1kb)
4
125398081
125398632
552
1
ENSMUSG00000082062.2
ENSMUST00000118517.2
151
chr4
131997445
131997495
Setd2-KO_rep2_peak_45
Promoter (<=1kb)
4
131997391
131997524
134
2
ENSMUSG00000077323.3
ENSMUST00000104135.3
29
chr4
131997417
131997467
Setd2-KO_rep2_peak_46
Promoter (<=1kb)
4
131997367
131997524
158
1
ENSMUSG00000099937.2
ENSMUST00000191518.2
51
chr4
131997441
131997491
Setd2-KO_rep2_peak_47
Promoter (<=1kb)
4
131997391
131997524
134
2
ENSMUSG00000077323.3
ENSMUST00000104135.3
33
chr4
132037601
132037651
Setd2-KO_rep2_peak_48
Promoter (<=1kb)
4
132037572
132038335
764
1
ENSMUSG00000086290.12
ENSMUST00000303243.1
30
chr4
146648960
146649010
Setd2-KO_rep2_peak_49
Promoter (<=1kb)
4
146648910
146649544
635
2
ENSMUSG00000095865.2
ENSMUST00000122151.2
534
chr5
74254241
74254291
Setd2-KO_rep2_peak_50
Promoter (<=1kb)
5
74254191
74254311
121
1
ENSMUSG00000093355.3
ENSMUST00000175614.3
51
chr5
110839965
110840015
Setd2-KO_rep2_peak_51
Promoter (<=1kb)
5
110835740
110840033
4294
2
ENSMUSG00000029505.19
ENSMUST00000129884.2
18
chr5
114845345
114845395
Setd2-KO_rep2_peak_52
Promoter (<=1kb)
5
114845821
114860388
14568
1
ENSMUSG00000002486.16
ENSMUST00000094441.11
-426
chr5
115241487
115241537
Setd2-KO_rep2_peak_53
Promoter (<=1kb)
5
115241287
115241580
294
2
ENSMUSG00000072692.9
ENSMUST00000124641.2
43
chr5
115627518
115627568
Setd2-KO_rep2_peak_54
Promoter (<=1kb)
5
115627518
115628584
1067
1
ENSMUSG00000132950.1
ENSMUST00000315073.1
1
chr5
115627518
115627568
Setd2-KO_rep2_peak_55
Promoter (<=1kb)
5
115627518
115628584
1067
1
ENSMUSG00000132950.1
ENSMUST00000315073.1
1
chr5
121343123
121343173
Setd2-KO_rep2_peak_56
Promoter (<=1kb)
5
121343073
121343206
134
1
ENSMUSG00000064841.3
ENSMUST00000082907.3
51
chr5
129871659
129871709
Setd2-KO_rep2_peak_57
Promoter (<=1kb)
5
129871609
129871739
131
1
ENSMUSG00000093413.3
ENSMUST00000177461.3
51
chr5
135386599
135386649
Setd2-KO_rep2_peak_58
Intron (ENSMUST00000111180.9/ENSMUSG00000053388.11, intron 1 of 5)
5
135382150
135396859
14710
1
ENSMUSG00000053388.11
ENSMUST00000065785.4
4450
chr5
142890270
142890320
Setd2-KO_rep2_peak_59
Promoter (<=1kb)
5
142888989
142889409
421
2
ENSMUSG00000029580.15
ENSMUST00000196997.2
-862
chr6
3201544
3201594
Setd2-KO_rep2_peak_60
Intron (ENSMUST00000318661.1/ENSMUSG00000133541.1, intron 3 of 3)
6
3207869
3208706
838
1
ENSMUSG00000107601.2
ENSMUST00000203560.2
-6275
chr6
69493465
69493515
Setd2-KO_rep2_peak_61
Promoter (<=1kb)
6
69493465
69493534
70
1
ENSMUSG00002075625.1
ENSMUST00020181981.1
1
chr6
71101694
71101744
Setd2-KO_rep2_peak_62
Promoter (<=1kb)
6
71101594
71101947
354
1
ENSMUSG00000068396.10
ENSMUST00000121998.2
101
chr6
71101744
71101794
Setd2-KO_rep2_peak_63
Promoter (<=1kb)
6
71101594
71101947
354
1
ENSMUSG00000068396.10
ENSMUST00000121998.2
151
chr6
124692335
124692385
Setd2-KO_rep2_peak_64
Promoter (<=1kb)
6
124692326
124693502
1177
1
ENSMUSG00000004264.18
ENSMUST00000129422.2
10
chr6
125098737
125098787
Setd2-KO_rep2_peak_65
Promoter (<=1kb)
6
125098687
125098822
136
1
ENSMUSG00000088208.3
ENSMUST00000157583.3
51
chr7
12531650
12531700
Setd2-KO_rep2_peak_66
Promoter (<=1kb)
7
12531456
12531788
333
1
ENSMUSG00000109925.2
ENSMUST00000209283.2
195
chr7
44776288
44776338
Setd2-KO_rep2_peak_67
Promoter (<=1kb)
7
44775347
44776303
957
2
ENSMUSG00000074129.15
ENSMUST00000210792.2
0
chr7
99132042
99132092
Setd2-KO_rep2_peak_68
Promoter (<=1kb)
7
99131992
99132139
148
2
ENSMUSG00000065822.3
ENSMUST00000083888.3
47
chr7
109120537
109120587
Setd2-KO_rep2_peak_69
Promoter (<=1kb)
7
109120487
109120616
130
1
ENSMUSG00000077575.3
ENSMUST00000104387.3
51
chr7
141028766
141028816
Setd2-KO_rep2_peak_70
Promoter (<=1kb)
7
141028716
141028852
137
1
ENSMUSG00000064666.3
ENSMUST00000082732.3
51
chr8
3853269
3853319
Setd2-KO_rep2_peak_71
Promoter (<=1kb)
8
3853069
3853358
290
2
ENSMUSG00000088025.3
ENSMUST00000157400.3
39
chr8
34181879
34181929
Setd2-KO_rep2_peak_72
Promoter (<=1kb)
8
34181829
34181972
144
1
ENSMUSG00000119577.1
ENSMUST00000239886.1
51
chr8
87774717
87774767
Setd2-KO_rep2_peak_73
Promoter (<=1kb)
8
87774317
87774854
538
1
ENSMUSG00000066362.6
ENSMUST00000183478.2
401
chr8
124301136
124301186
Setd2-KO_rep2_peak_74
Promoter (<=1kb)
8
124301136
124301254
119
2
ENSMUSG00000119919.1
ENSMUST00000239807.1
68
chr8
124302815
124302865
Setd2-KO_rep2_peak_75
Promoter (<=1kb)
8
124302815
124302933
119
2
ENSMUSG00000119118.1
ENSMUST00000240190.1
68
chr8
124312981
124313031
Setd2-KO_rep2_peak_76
Promoter (<=1kb)
8
124312981
124313099
119
2
ENSMUSG00001118664.1
ENSMUST00000240133.1
68
chr8
124321493
124321543
Setd2-KO_rep2_peak_77
Promoter (<=1kb)
8
124321493
124321611
119
2
ENSMUSG00000119324.1
ENSMUST00000239771.1
68
chr8
124323196
124323246
Setd2-KO_rep2_peak_78
Promoter (<=1kb)
8
124323196
124323314
119
2
ENSMUSG00000119587.1
ENSMUST00000240236.1
68
chr8
124324897
124324947
Setd2-KO_rep2_peak_79
Promoter (<=1kb)
8
124324897
124325015
119
2
ENSMUSG00000119280.1
ENSMUST00000239832.1
68
chr8
124329986
124330036
Setd2-KO_rep2_peak_80
Promoter (<=1kb)
8
124329986
124330104
119
2
ENSMUSG00000118796.1
ENSMUST00000240112.1
68
chr8
124333352
124333402
Setd2-KO_rep2_peak_81
Promoter (<=1kb)
8
124333352
124333470
119
2
ENSMUSG00000118747.1
ENSMUST00000239942.1
68
chr8
124335059
124335109
Setd2-KO_rep2_peak_82
Promoter (<=1kb)
8
124335059
124335177
119
2
ENSMUSG00000119615.1
ENSMUST00000240207.1
68
chr8
124340153
124340203
Setd2-KO_rep2_peak_83
Promoter (<=1kb)
8
124340153
124340271
119
2
ENSMUSG00000119414.1
ENSMUST00000239973.1
68
chr8
124341838
124341888
Setd2-KO_rep2_peak_84
Promoter (<=1kb)
8
124341838
124341956
119
2
ENSMUSG00000119561.1
ENSMUST00000240273.1
68
chr8
124343549
124343599
Setd2-KO_rep2_peak_85
Promoter (<=1kb)
8
124343549
124343667
119
2
ENSMUSG00000119014.1
ENSMUST00000240509.1
68
chr8
124345275
124345325
Setd2-KO_rep2_peak_86
Promoter (<=1kb)
8
124345275
124345393
119
2
ENSMUSG00000118870.1
ENSMUST00000240449.1
68
chr8
124346980
124347030
Setd2-KO_rep2_peak_87
Promoter (<=1kb)
8
124346980
124347098
119
2
ENSMUSG00000118727.1
ENSMUST00000239880.1
68
chr8
124348667
124348717
Setd2-KO_rep2_peak_88
Promoter (<=1kb)
8
124348667
124348785
119
2
ENSMUSG00000119808.1
ENSMUST00000240201.1
68
chr9
15237760
15237810
Setd2-KO_rep2_peak_89
Promoter (<=1kb)
9
15237760
15237835
76
2
ENSMUSG00000077394.3
ENSMUST00000104206.3
25
chr9
58207921
58207971
Setd2-KO_rep2_peak_90
Intron (ENSMUST00000378352.1/ENSMUSG00000120404.2, intron 1 of 1)
9
58219098
58235579
16482
1
ENSMUSG00000120404.2
ENSMUST00000378354.1
-11127
chr9
65103907
65103957
Setd2-KO_rep2_peak_91
Promoter (<=1kb)
9
65103854
65103969
116
2
ENSMUSG00000118734.1
ENSMUST00000093721.3
12
chr9
65109035
65109085
Setd2-KO_rep2_peak_92
Promoter (<=1kb)
9
65109008
65109123
116
2
ENSMUSG00000119286.1
ENSMUST00000101817.3
38
chr9
65103904
65103954
Setd2-KO_rep2_peak_93
Promoter (<=1kb)
9
65103854
65103969
116
2
ENSMUSG00000118734.1
ENSMUST00000093721.3
15
chr9
78082635
78082685
Setd2-KO_rep2_peak_94
Promoter (<=1kb)
9
78082585
78082915
331
2
ENSMUSG00002076161.1
ENSMUST00020183253.1
230
chr9
78082835
78082885
Setd2-KO_rep2_peak_95
Promoter (<=1kb)
9
78082585
78082915
331
2
ENSMUSG00002076161.1
ENSMUST00020183253.1
30
chr9
123291192
123291242
Setd2-KO_rep2_peak_96
3' UTR
9
123283855
123290964
7110
1
ENSMUSG00000035202.9
ENSMUST00000215087.2
7338
chr10
23661295
23661345
Setd2-KO_rep2_peak_97
Promoter (<=1kb)
10
23661245
23661373
129
2
ENSMUSG00000070063.3
ENSMUST00000093556.3
28
chr10
23662368
23662418
Setd2-KO_rep2_peak_98
Promoter (<=1kb)
10
23661524
23662410
887
2
ENSMUSG00000061983.8
ENSMUST00000218185.2
0
chr10
75695237
75695287
Setd2-KO_rep2_peak_99
Promoter (<=1kb)
10
75694705
75697532
2828
1
ENSMUSG00000122183.1
ENSMUST00000251235.1
533
chr10
111317404
111317454
Setd2-KO_rep2_peak_100
Promoter (<=1kb)
10
111317354
111317497
144
1
ENSMUSG00000087819.3
ENSMUST00000157194.3
51
chr
start
end
peaknum
annotation
geneChr
geneStart
geneEnd
geneLength
geneStrand
geneId
transcriptId
distanceToTSS
chr17
40158190
40159287
Setd2-KOvsWT_up_peak_1
Promoter (<=1kb)
17
40157244
40159092
1849
1
ENSMUSG00000119584.1
ENSMUST00000240377.1
947
chr
start
end
peaknum
annotation
geneChr
geneStart
geneEnd
geneLength
geneStrand
geneId
transcriptId
distanceToTSS
chr1
63218034
63218434
WT_cons_peak_1
Promoter (<=1kb)
1
63218163
63218294
132
1
ENSMUSG00000064602.3
ENSMUST00000082668.3
0
chr1
118386728
118387128
WT_cons_peak_2
Promoter (<=1kb)
1
118386871
118386995
125
2
ENSMUSG00000080542.3
ENSMUST00000116892.3
0
chr1
143654523
143654923
WT_cons_peak_3
Promoter (<=1kb)
1
143654666
143654800
135
1
ENSMUSG00000088323.3
ENSMUST00000157698.3
0
chr1
153385166
153385566
WT_cons_peak_4
Intron (ENSMUST00000041874.9/ENSMUSG00000042684.9, intron 10 of 11)
1
153331504
153363406
31903
2
ENSMUSG00000042699.12
ENSMUST00000042141.12
-21761
chr1
160863241
160863858
WT_cons_peak_5
Promoter (<=1kb)
1
160863331
160866109
2779
1
ENSMUSG00000053332.16
ENSMUST00000310985.1
0
chr1
160865483
160865883
WT_cons_peak_6
Promoter (<=1kb)
1
160865652
160865728
77
1
ENSMUSG00000064968.3
ENSMUST00000083034.3
0
chr1
171330472
171330872
WT_cons_peak_7
Promoter (<=1kb)
1
171330616
171330731
116
2
ENSMUSG00000119640.1
ENSMUST00000083099.3
0
chr1
171538548
171538948
WT_cons_peak_8
Promoter (<=1kb)
1
171538656
171538850
195
1
ENSMUSG00000059058.8
ENSMUST00000118448.2
0
chr10
111317215
111317615
WT_cons_peak_9
Promoter (<=1kb)
10
111317354
111317497
144
1
ENSMUSG00000087819.3
ENSMUST00000157194.3
0
chr10
121273193
121273593
WT_cons_peak_10
Intron (ENSMUST00000026902.9/ENSMUSG00000025795.9, intron 1 of 4)
10
121250292
121298118
47827
2
ENSMUSG00000025795.9
ENSMUST00000219500.2
24525
chr11
48753819
48754219
WT_cons_peak_11
Exon (ENSMUST00000147151.2/ENSMUSG00000046879.8, exon 2 of 2)
11
48745257
48749020
3764
2
ENSMUSG00000132080.1
ENSMUST00000310045.1
-4800
chr11
55373405
55373805
WT_cons_peak_12
Promoter (<=1kb)
11
55373520
55373659
140
1
ENSMUSG00000065061.3
ENSMUST00000083127.3
0
chr11
68964146
68964546
WT_cons_peak_13
Promoter (<=1kb)
11
68964253
68964387
135
1
ENSMUSG00000064899.3
ENSMUST00000082965.3
0
chr11
69558547
69558947
WT_cons_peak_14
Promoter (<=1kb)
11
69558208
69558889
682
2
ENSMUSG00000059796.17
ENSMUST00000140186.2
0
chr11
69559555
69559955
WT_cons_peak_15
Promoter (<=1kb)
11
69559678
69559821
144
2
ENSMUSG00000089542.3
ENSMUST00000158917.3
0
chr11
87313590
87313990
WT_cons_peak_16
Promoter (<=1kb)
11
87313693
87313856
164
1
ENSMUSG00000119476.1
ENSMUST00000240501.1
0
chr11
87317393
87317793
WT_cons_peak_17
Promoter (<=1kb)
11
87317542
87317705
164
1
ENSMUSG00000118815.1
ENSMUST00000093684.3
0
chr11
97672347
97672747
WT_cons_peak_18
Promoter (<=1kb)
11
97672465
97672601
137
2
ENSMUSG00000064901.3
ENSMUST00000082967.3
0
chr11
106391659
106392059
WT_cons_peak_19
Promoter (<=1kb)
11
106391819
106391888
70
1
ENSMUSG00000065126.3
ENSMUST00000083192.3
0
chr11
116967982
116968382
WT_cons_peak_20
Promoter (<=1kb)
11
116968004
116969781
1778
1
ENSMUSG00000086859.7
ENSMUST00000328767.1
0
chr12
17595999
17596399
WT_cons_peak_21
Promoter (<=1kb)
12
17596147
17596282
136
1
ENSMUSG00000064427.3
ENSMUST00000082493.3
0
chr12
54765889
54766289
WT_cons_peak_22
Promoter (<=1kb)
12
54765941
54766104
164
2
ENSMUSG00000118864.1
ENSMUST00001239507.1
0
chr12
54776246
54776646
WT_cons_peak_23
Promoter (<=1kb)
12
54776380
54776543
164
1
ENSMUSG00000118751.1
ENSMUST00000240287.1
0
chr12
69205968
69206419
WT_cons_peak_24
Promoter (<=1kb)
12
69206069
69206368
300
1
ENSMUSG00000118866.1
ENSMUST00000175032.4
0
chr12
69407904
69408406
WT_cons_peak_25
Promoter (<=1kb)
12
69407956
69408255
300
2
ENSMUSG00000118841.1
ENSMUST00000174924.4
0
chr12
109510270
109510670
WT_cons_peak_26
Promoter (<=1kb)
12
109510424
109510503
80
1
ENSMUSG00000084535.3
ENSMUST00000122586.3
0
chr13
22015963
22016363
WT_cons_peak_27
Promoter (<=1kb)
13
22015937
22016366
430
2
ENSMUSG00000069305.4
ENSMUST00000102979.2
3
chr13
22220133
22220533
WT_cons_peak_28
Promoter (<=1kb)
13
22220040
22220515
476
1
ENSMUSG00000062727.5
ENSMUST00000110455.4
94
chr13
22225177
22225577
WT_cons_peak_29
Promoter (<=1kb)
13
22224806
22225532
727
2
ENSMUSG00000060639.6
ENSMUST00000102977.4
0
chr13
23715188
23715588
WT_cons_peak_30
Promoter (<=1kb)
13
23715220
23715689
470
1
ENSMUSG00000060981.8
ENSMUST00000102972.6
0
chr13
23930873
23931273
WT_cons_peak_31
Promoter (<=1kb)
13
23930717
23931224
508
1
ENSMUSG00000075031.5
ENSMUST00000099703.5
157
chr13
51802121
51802521
WT_cons_peak_32
Promoter (<=1kb)
13
51802235
51802370
136
1
ENSMUSG00000064672.3
ENSMUST00000082738.3
0
chr13
97150416
97150816
WT_cons_peak_33
Promoter (<=1kb)
13
97151393
97151807
415
2
ENSMUSG00000113934.2
ENSMUST00000222278.2
991
chr13
108807642
108808042
WT_cons_peak_34
Promoter (<=1kb)
13
108807137
108807931
795
1
ENSMUSG00000059751.8
ENSMUST00000074680.8
506
chr14
51044755
51045356
WT_cons_peak_35
Promoter (<=1kb)
14
51045298
51058758
13461
1
ENSMUSG00000036023.7
ENSMUST00000036126.7
0
chr14
64991235
64991635
WT_cons_peak_36
Promoter (<=1kb)
14
64991367
64991501
135
1
ENSMUSG00000064442.3
ENSMUST00000082508.3
0
chr15
34440813
34441213
WT_cons_peak_37
Promoter (<=1kb)
15
34440937
34441068
132
2
ENSMUSG00000065899.3
ENSMUST00000083965.3
0
chr15
83033716
83034116
WT_cons_peak_38
Promoter (<=1kb)
15
83033845
83033995
151
1
ENSMUSG00000065176.3
ENSMUST00000083242.3
0
chr15
98417451
98417851
WT_cons_peak_39
Promoter (<=1kb)
15
98417643
98417759
117
2
ENSMUSG00000106463.3
ENSMUST00000199842.3
0
chr15
98424094
98424494
WT_cons_peak_40
Promoter (<=1kb)
15
98424227
98424363
137
2
ENSMUSG00000065939.3
ENSMUST00000084005.3
0
chr16
10961801
10962253
WT_cons_peak_41
Promoter (<=1kb)
16
10961986
10968469
6484
1
ENSMUSG00000141422.1
ENSMUST00000365190.1
0
chr16
18351787
18352187
WT_cons_peak_42
Intron (ENSMUST00000231621.2/ENSMUSG00000000884.18, intron 2 of 7)
16
18367493
18371334
3842
1
ENSMUSG00000000884.18
ENSMUST00000151253.2
-15306
chr16
22927509
22927909
WT_cons_peak_43
Promoter (<=1kb)
16
22927703
22927771
69
1
ENSMUSG00000088524.3
ENSMUST00000157899.3
0
chr16
22929392
22929792
WT_cons_peak_44
Promoter (<=1kb)
16
22929422
22930690
1269
1
ENSMUSG00000022884.17
ENSMUST00000150117.2
0
chr16
22929906
22930633
WT_cons_peak_45
Promoter (<=1kb)
16
22930051
22930179
129
1
ENSMUSG00000064382.3
ENSMUST00000082448.3
0
chr16
30687753
30688153
WT_cons_peak_46
Promoter (<=1kb)
16
30687849
30688952
1104
2
ENSMUSG00000116951.3
ENSMUST00000304664.1
799
chr16
32062399
32062799
WT_cons_peak_47
Promoter (<=1kb)
16
32062530
32062673
144
2
ENSMUSG00000080440.3
ENSMUST00000116790.3
0
chr16
55855973
55856373
WT_cons_peak_48
Promoter (<=1kb)
16
55856116
55856250
135
2
ENSMUSG00000064994.3
ENSMUST00000083060.3
0
chr17
24938535
24938940
WT_cons_peak_49
Promoter (<=1kb)
17
24938650
24938777
128
2
ENSMUSG00000089255.3
ENSMUST00000158630.3
0
chr17
24939617
24940017
WT_cons_peak_50
Promoter (<=1kb)
17
24939797
24940841
1045
1
ENSMUSG00000044533.16
ENSMUST00000129580.2
0
chr17
35170798
35171198
WT_cons_peak_51
Promoter (<=1kb)
17
35154724
35170952
16229
2
ENSMUSG00000092203.10
ENSMUST00000371044.1
0
chr17
40157093
40157787
WT_cons_peak_52
Promoter (<=1kb)
17
40157244
40159092
1849
1
ENSMUSG00000119584.1
ENSMUST00000240377.1
0
chr17
40158190
40159287
WT_cons_peak_53
Promoter (<=1kb)
17
40157244
40159092
1849
1
ENSMUSG00000119584.1
ENSMUST00000240377.1
947
chr18
10150877
10151277
WT_cons_peak_54
Promoter (<=1kb)
18
10150977
10151140
164
2
ENSMUSG00000095616.2
ENSMUST00000083435.3
0
chr18
14780732
14781132
WT_cons_peak_55
Promoter (<=1kb)
18
14780824
14780987
164
2
ENSMUSG00000094306.3
ENSMUST00000084007.4
0
chr18
33928075
33928475
WT_cons_peak_56
Promoter (<=1kb)
18
33928173
33929044
872
1
ENSMUSG00000087590.5
ENSMUST00000335104.1
0
chr18
35687407
35687807
WT_cons_peak_57
Promoter (<=1kb)
18
35687620
35687689
70
1
ENSMUSG00000105743.3
ENSMUST00000199259.3
0
chr19
8701444
8701844
WT_cons_peak_58
Promoter (<=1kb)
19
8701615
8701689
75
1
ENSMUSG00000065392.3
ENSMUST00000083458.3
0
chr19
8702274
8702674
WT_cons_peak_59
Promoter (<=1kb)
19
8702456
8702520
65
1
ENSMUSG00000065378.3
ENSMUST00000083444.3
0
chr2
19307987
19308387
WT_cons_peak_60
Intron (ENSMUST00000049255.7/ENSMUSG00000037683.15, intron 17 of 18)
2
19344481
19349004
4524
2
ENSMUSG00000124341.1
ENSMUST00000263154.1
40617
chr2
26527744
26528144
WT_cons_peak_61
Promoter (<=1kb)
2
26527860
26527986
127
2
ENSMUSG00000064858.4
ENSMUST00000082924.4
0
chr2
27429692
27430092
WT_cons_peak_62
Promoter (<=1kb)
2
27429817
27429942
126
2
ENSMUSG00000080538.3
ENSMUST00000116888.3
0
chr2
102914594
102914994
WT_cons_peak_63
Promoter (1-2kb)
2
102913302
102922135
8834
1
ENSMUSG00000010911.13
ENSMUST00000155004.2
1293
chr2
130118022
130118422
WT_cons_peak_64
Promoter (<=1kb)
2
130118079
130120883
2805
1
ENSMUSG00000027405.17
ENSMUST00000149955.9
0
chr2
144103384
144103784
WT_cons_peak_65
Promoter (<=1kb)
2
144103509
144103646
138
2
ENSMUSG00000065725.3
ENSMUST00000083791.3
0
chr2
158201571
158201971
WT_cons_peak_66
Promoter (<=1kb)
2
158201718
158201849
132
2
ENSMUSG00000064405.3
ENSMUST00000082471.3
0
chr2
166907017
166907417
WT_cons_peak_67
Promoter (<=1kb)
2
166907196
166907285
90
1
ENSMUSG00000077698.3
ENSMUST00000104510.3
0
chr3
88707049
88707449
WT_cons_peak_68
Exon (ENSMUST00000253106.1/ENSMUSG00000122440.1, exon 6 of 6)
3
88724693
88728201
3509
1
ENSMUSG00000122565.1
ENSMUST00000253674.1
-17244
chr3
96147104
96147504
WT_cons_peak_69
Promoter (<=1kb)
3
96147184
96147321
138
1
ENSMUSG00002076697.1
ENSMUST00020181968.1
0
chr3
96152916
96153316
WT_cons_peak_70
Promoter (<=1kb)
3
96153142
96153279
138
2
ENSMUSG00002076967.1
ENSMUST00020182038.1
0
chr3
96176957
96177549
WT_cons_peak_71
Promoter (<=1kb)
3
96177037
96186317
9281
1
ENSMUSG00000050936.7
ENSMUST00000051089.4
0
chr3
96235632
96236032
WT_cons_peak_72
Promoter (<=1kb)
3
96235741
96235906
166
1
ENSMUSG00000119427.1
ENSMUST00000239827.1
0
chr3
96281198
96281598
WT_cons_peak_73
Promoter (<=1kb)
3
96281337
96281501
165
1
ENSMUSG00000119030.1
ENSMUST00000240438.1
0
chr3
96357653
96358053
WT_cons_peak_74
Promoter (<=1kb)
3
96357762
96357927
166
1
ENSMUSG00000119774.1
ENSMUST00000083839.3
0
chr3
96367289
96367689
WT_cons_peak_75
Promoter (<=1kb)
3
96367340
96367505
166
2
ENSMUSG00000118677.1
ENSMUST00000240510.1
0
chr3
123301473
123301873
WT_cons_peak_76
Promoter (<=1kb)
3
123301586
123301715
130
2
ENSMUSG00000092730.3
ENSMUST00000174989.3
0
chr3
153616005
153616405
WT_cons_peak_77
Promoter (<=1kb)
3
153616200
153616270
71
2
ENSMUSG00000064731.3
ENSMUST00000082797.3
0
chr3
153617597
153617997
WT_cons_peak_78
Promoter (<=1kb)
3
153612924
153617948
5025
2
ENSMUSG00000038975.15
ENSMUST00000197438.5
0
chr4
43492725
43493125
WT_cons_peak_79
Promoter (<=1kb)
4
43492900
43494205
1306
1
ENSMUSG00000028461.13
ENSMUST00000143073.8
0
chr4
119226939
119227339
WT_cons_peak_80
Intron (ENSMUST00000238759.2/ENSMUSG00000028637.17, intron 5 of 14)
4
119209443
119230950
21508
2
ENSMUSG00000028637.17
ENSMUST00000238779.2
3611
chr4
131997261
131997661
WT_cons_peak_81
Promoter (<=1kb)
4
131997391
131997524
134
2
ENSMUSG00000077323.3
ENSMUST00000104135.3
0
chr4
132037405
132037805
WT_cons_peak_82
Promoter (<=1kb)
4
132037551
132037680
130
1
ENSMUSG00000064949.3
ENSMUST00000083015.3
0
chr5
74254042
74254442
WT_cons_peak_83
Promoter (<=1kb)
5
74254191
74254311
121
1
ENSMUSG00000093355.3
ENSMUST00000175614.3
0
chr5
115627366
115627766
WT_cons_peak_84
Promoter (<=1kb)
5
115627518
115627658
141
1
ENSMUSG00000119520.1
ENSMUST00000239680.1
0
chr5
118567548
118567948
WT_cons_peak_85
Intron (ENSMUST00000279925.1/ENSMUSG00000127080.1, intron 1 of 1)
5
118563375
118571739
8365
1
ENSMUSG00000127080.1
ENSMUST00000279925.1
4174
chr5
121342929
121343329
WT_cons_peak_86
Promoter (<=1kb)
5
121343073
121343206
134
1
ENSMUSG00000064841.3
ENSMUST00000082907.3
0
chr5
125485899
125486299
WT_cons_peak_87
Promoter (<=1kb)
5
125483388
125486552
3165
2
ENSMUSG00000132160.1
ENSMUST00000310468.1
253
chr5
129871464
129871864
WT_cons_peak_88
Promoter (<=1kb)
5
129871609
129871739
131
1
ENSMUSG00000093413.3
ENSMUST00000177461.3
0
chr5
146771806
146772206
WT_cons_peak_89
Promoter (<=1kb)
5
146772016
146772796
781
1
ENSMUSG00000041453.13
ENSMUST00000135345.2
0
chr6
3201344
3201744
WT_cons_peak_90
Intron (ENSMUST00000318661.1/ENSMUSG00000133541.1, intron 3 of 3)
6
3207869
3208706
838
1
ENSMUSG00000107601.2
ENSMUST00000203560.2
-6125
chr6
47755027
47755427
WT_cons_peak_91
Promoter (<=1kb)
6
47755311
47757431
2121
1
ENSMUSG00000126201.1
ENSMUST00000275052.1
0
chr6
69493265
69493665
WT_cons_peak_92
Promoter (<=1kb)
6
69493323
69493613
291
1
ENSMUSG00000092746.5
ENSMUST00000175005.5
0
chr6
71101581
71101981
WT_cons_peak_93
Promoter (<=1kb)
6
71101594
71101947
354
1
ENSMUSG00000068396.10
ENSMUST00000121998.2
0
chr6
71859402
71859802
WT_cons_peak_94
Promoter (<=1kb)
6
71857622
71859579
1958
2
ENSMUSG00000063884.7
ENSMUST00000205269.2
0
chr6
124692151
124692551
WT_cons_peak_95
Promoter (<=1kb)
6
124692311
124693913
1603
1
ENSMUSG00000004264.18
ENSMUST00000143000.8
0
chr6
125098567
125098967
WT_cons_peak_96
Promoter (<=1kb)
6
125098687
125098822
136
1
ENSMUSG00000088208.3
ENSMUST00000157583.3
0
chr6
136780969
136781369
WT_cons_peak_97
Promoter (<=1kb)
6
136778551
136781413
2863
2
ENSMUSG00000096010.3
ENSMUST00000179285.3
44
chr7
44776096
44776496
WT_cons_peak_98
Promoter (<=1kb)
7
44775347
44776303
957
2
ENSMUSG00000074129.15
ENSMUST00000210792.2
0
chr7
99128628
99129028
WT_cons_peak_99
Promoter (<=1kb)
7
99128770
99128914
145
2
ENSMUSG00000064966.3
ENSMUST00000083032.3
0
chr7
99131861
99132261
WT_cons_peak_100
Promoter (<=1kb)
7
99131992
99132139
148
2
ENSMUSG00000065822.3
ENSMUST00000083888.3
0
chr
start
end
peaknum
annotation
geneChr
geneStart
geneEnd
geneLength
geneStrand
geneId
transcriptId
distanceToTSS
chr1
63218213
63218263
WT_rep1_peak_1
Promoter (<=1kb)
1
63218163
63218294
132
1
ENSMUSG00000064602.3
ENSMUST00000082668.3
51
chr1
72265499
72265549
WT_rep1_peak_2
Promoter (<=1kb)
1
72265399
72265589
191
1
ENSMUSG00000118839.1
ENSMUST00000240405.1
101
chr1
118386921
118386971
WT_rep1_peak_3
Promoter (<=1kb)
1
118386871
118386995
125
2
ENSMUSG00000080542.3
ENSMUST00000116892.3
24
chr1
143654716
143654766
WT_rep1_peak_4
Promoter (<=1kb)
1
143654666
143654800
135
1
ENSMUSG00000088323.3
ENSMUST00000157698.3
51
chr1
159167903
159167953
WT_rep1_peak_5
Promoter (<=1kb)
1
159167928
159167993
66
1
ENSMUSG00000105399.3
ENSMUST00000198115.3
0
chr1
159167928
159167978
WT_rep1_peak_6
Promoter (<=1kb)
1
159167928
159167993
66
1
ENSMUSG00000105399.3
ENSMUST00000198115.3
1
chr1
160863420
160863470
WT_rep1_peak_7
Promoter (<=1kb)
1
160863420
160863481
62
1
ENSMUSG00000080463.3
ENSMUST00000116813.3
1
chr1
160863627
160863677
WT_rep1_peak_8
Promoter (<=1kb)
1
160863627
160863709
83
1
ENSMUSG00000064816.3
ENSMUST00000082882.3
1
chr1
171330636
171330686
WT_rep1_peak_9
Promoter (<=1kb)
1
171330616
171330731
116
2
ENSMUSG00000119640.1
ENSMUST00000083099.3
45
chr1
171330666
171330716
WT_rep1_peak_10
Promoter (<=1kb)
1
171330616
171330731
116
2
ENSMUSG00000119640.1
ENSMUST00000083099.3
15
chr1
171538706
171538756
WT_rep1_peak_11
Promoter (<=1kb)
1
171538656
171538850
195
1
ENSMUSG00000059058.8
ENSMUST00000118448.2
51
chr2
19308163
19308213
WT_rep1_peak_12
Intron (ENSMUST00000049255.7/ENSMUSG00000037683.15, intron 17 of 18)
2
19344481
19349004
4524
2
ENSMUSG00000124341.1
ENSMUST00000263154.1
40791
chr2
26527909
26527959
WT_rep1_peak_13
Promoter (<=1kb)
2
26527860
26527986
127
2
ENSMUSG00000064858.4
ENSMUST00000082924.4
27
chr2
26527910
26527960
WT_rep1_peak_14
Promoter (<=1kb)
2
26527860
26527986
127
2
ENSMUSG00000064858.4
ENSMUST00000082924.4
26
chr2
27429867
27429917
WT_rep1_peak_15
Promoter (<=1kb)
2
27429817
27429942
126
2
ENSMUSG00000080538.3
ENSMUST00000116888.3
25
chr2
32853353
32853403
WT_rep1_peak_16
Promoter (<=1kb)
2
32853303
32853432
130
1
ENSMUSG00000065124.3
ENSMUST00000083190.3
51
chr2
102914770
102914820
WT_rep1_peak_17
Promoter (1-2kb)
2
102913302
102922135
8834
1
ENSMUSG00000010911.13
ENSMUST00000155004.2
1469
chr2
144103559
144103609
WT_rep1_peak_18
Promoter (<=1kb)
2
144103509
144103646
138
2
ENSMUSG00000065725.3
ENSMUST00000083791.3
37
chr2
144107999
144108049
WT_rep1_peak_19
Promoter (<=1kb)
2
144107899
144108136
238
2
ENSMUSG00000077714.3
ENSMUST00000104526.3
87
chr2
166907196
166907246
WT_rep1_peak_20
Promoter (<=1kb)
2
166907196
166907285
90
1
ENSMUSG00000077698.3
ENSMUST00000104510.3
1
chr3
81736781
81736831
WT_rep1_peak_21
Intron (ENSMUST00000368586.1/ENSMUSG00000056023.5, intron 1 of 1)
3
81759489
81763089
3601
1
ENSMUSG00000142084.1
ENSMUST00000368773.1
-22658
chr3
88601287
88601337
WT_rep1_peak_22
Promoter (<=1kb)
3
88601238
88601364
127
1
ENSMUSG00002076937.1
ENSMUST00020181915.1
50
chr3
88601288
88601338
WT_rep1_peak_23
Promoter (<=1kb)
3
88601238
88601364
127
1
ENSMUSG00002076937.1
ENSMUST00020181915.1
51
chr3
88707229
88707279
WT_rep1_peak_24
Exon (ENSMUST00000253106.1/ENSMUSG00000122440.1, exon 6 of 6)
3
88724693
88728201
3509
1
ENSMUSG00000122565.1
ENSMUST00000253674.1
-17414
chr3
96177141
96177191
WT_rep1_peak_25
Promoter (<=1kb)
3
96177068
96177448
381
1
ENSMUSG00000105827.2
ENSMUST00000177113.2
74
chr3
96177191
96177241
WT_rep1_peak_26
Promoter (<=1kb)
3
96177068
96177448
381
1
ENSMUSG00000105827.2
ENSMUST00000177113.2
124
chr3
96177368
96177418
WT_rep1_peak_27
Promoter (<=1kb)
3
96174391
96177605
3215
2
ENSMUSG00000093656.2
ENSMUST00000177363.2
187
chr3
96235791
96235841
WT_rep1_peak_28
Promoter (<=1kb)
3
96235741
96235906
166
1
ENSMUSG00000119427.1
ENSMUST00000239827.1
51
chr3
96281387
96281437
WT_rep1_peak_29
Promoter (<=1kb)
3
96281337
96281501
165
1
ENSMUSG00000119030.1
ENSMUST00000240438.1
51
chr3
96357804
96357854
WT_rep1_peak_30
Promoter (<=1kb)
3
96357762
96357927
166
1
ENSMUSG00000119774.1
ENSMUST00000083839.3
43
chr3
96367424
96367474
WT_rep1_peak_31
Promoter (<=1kb)
3
96367340
96367505
166
2
ENSMUSG00000118677.1
ENSMUST00000240510.1
31
chr3
96367440
96367490
WT_rep1_peak_32
Promoter (<=1kb)
3
96367340
96367505
166
2
ENSMUSG00000118677.1
ENSMUST00000240510.1
15
chr3
153617762
153617812
WT_rep1_peak_33
Promoter (<=1kb)
3
153612926
153617782
4857
2
ENSMUSG00000038975.15
ENSMUST00000167111.6
0
chr4
43492833
43492883
WT_rep1_peak_34
Promoter (<=1kb)
4
43492900
43494205
1306
1
ENSMUSG00000028461.13
ENSMUST00000143073.8
-17
chr4
43492883
43492933
WT_rep1_peak_35
Promoter (<=1kb)
4
43492900
43494205
1306
1
ENSMUSG00000028461.13
ENSMUST00000143073.8
0
chr4
43492838
43492888
WT_rep1_peak_36
Promoter (<=1kb)
4
43492900
43494205
1306
1
ENSMUSG00000028461.13
ENSMUST00000143073.8
-12
chr4
131997441
131997491
WT_rep1_peak_37
Promoter (<=1kb)
4
131997391
131997524
134
2
ENSMUSG00000077323.3
ENSMUST00000104135.3
33
chr4
132036825
132036875
WT_rep1_peak_38
Promoter (<=1kb)
4
132036776
132036911
136
1
ENSMUSG00000065097.3
ENSMUST00000083163.3
50
chr4
132036826
132036876
WT_rep1_peak_39
Promoter (<=1kb)
4
132036776
132036911
136
1
ENSMUSG00000065097.3
ENSMUST00000083163.3
51
chr5
115627518
115627568
WT_rep1_peak_40
Promoter (<=1kb)
5
115627518
115628584
1067
1
ENSMUSG00000132950.1
ENSMUST00000315073.1
1
chr5
118567725
118567775
WT_rep1_peak_41
Intron (ENSMUST00000279925.1/ENSMUSG00000127080.1, intron 1 of 1)
5
118563375
118571739
8365
1
ENSMUSG00000127080.1
ENSMUST00000279925.1
4351
chr5
121343123
121343173
WT_rep1_peak_42
Promoter (<=1kb)
5
121343073
121343206
134
1
ENSMUSG00000064841.3
ENSMUST00000082907.3
51
chr5
125486088
125486138
WT_rep1_peak_43
Promoter (<=1kb)
5
125483388
125486552
3165
2
ENSMUSG00000132160.1
ENSMUST00000310468.1
414
chr5
129871659
129871709
WT_rep1_peak_44
Promoter (<=1kb)
5
129871609
129871739
131
1
ENSMUSG00000093413.3
ENSMUST00000177461.3
51
chr5
146772004
146772054
WT_rep1_peak_45
Promoter (<=1kb)
5
146772016
146772796
781
1
ENSMUSG00000041453.13
ENSMUST00000135345.2
0
chr6
71859591
71859641
WT_rep1_peak_46
Promoter (<=1kb)
6
71857622
71859579
1958
2
ENSMUSG00000063884.7
ENSMUST00000205269.2
-13
chr6
124692335
124692385
WT_rep1_peak_47
Promoter (<=1kb)
6
124692326
124693502
1177
1
ENSMUSG00000004264.18
ENSMUST00000129422.2
10
chr6
125098737
125098787
WT_rep1_peak_48
Promoter (<=1kb)
6
125098687
125098822
136
1
ENSMUSG00000088208.3
ENSMUST00000157583.3
51
chr6
136781151
136781201
WT_rep1_peak_49
Promoter (<=1kb)
6
136778551
136781413
2863
2
ENSMUSG00000096010.3
ENSMUST00000179285.3
212
chr7
99128820
99128870
WT_rep1_peak_50
Promoter (<=1kb)
7
99128770
99128914
145
2
ENSMUSG00000064966.3
ENSMUST00000083032.3
44
chr7
99132042
99132092
WT_rep1_peak_51
Promoter (<=1kb)
7
99131992
99132139
148
2
ENSMUSG00000065822.3
ENSMUST00000083888.3
47
chr7
109119377
109119427
WT_rep1_peak_52
Promoter (<=1kb)
7
109119327
109119458
132
1
ENSMUSG00000065016.3
ENSMUST00000083082.3
51
chr7
109120537
109120587
WT_rep1_peak_53
Promoter (<=1kb)
7
109120487
109120616
130
1
ENSMUSG00000077575.3
ENSMUST00000104387.3
51
chr7
141028766
141028816
WT_rep1_peak_54
Promoter (<=1kb)
7
141028716
141028852
137
1
ENSMUSG00000064666.3
ENSMUST00000082732.3
51
chr8
52790050
52790100
WT_rep1_peak_55
Promoter (<=1kb)
8
52789950
52790140
191
2
ENSMUSG00000064682.3
ENSMUST00000082748.3
40
chr8
87774717
87774767
WT_rep1_peak_56
Promoter (<=1kb)
8
87774317
87774854
538
1
ENSMUSG00000066362.6
ENSMUST00000183478.2
401
chr8
96472738
96472788
WT_rep1_peak_57
Promoter (<=1kb)
8
96472688
96472823
136
2
ENSMUSG00000065089.3
ENSMUST00000083155.3
35
chr8
124294376
124294426
WT_rep1_peak_58
Promoter (<=1kb)
8
124294376
124294494
119
2
ENSMUSG00000119210.1
ENSMUST00000240370.1
68
chr8
124301136
124301186
WT_rep1_peak_59
Promoter (<=1kb)
8
124301136
124301254
119
2
ENSMUSG00000119919.1
ENSMUST00000239807.1
68
chr8
124304494
124304544
WT_rep1_peak_60
Promoter (<=1kb)
8
124304494
124304612
119
2
ENSMUSG00000119521.1
ENSMUST00000239660.1
68
chr8
124312981
124313031
WT_rep1_peak_61
Promoter (<=1kb)
8
124312981
124313099
119
2
ENSMUSG00001118664.1
ENSMUST00000240133.1
68
chr8
124319810
124319860
WT_rep1_peak_62
Promoter (<=1kb)
8
124319810
124319928
119
2
ENSMUSG00000119493.1
ENSMUST00000239762.1
68
chr8
124321493
124321543
WT_rep1_peak_63
Promoter (<=1kb)
8
124321493
124321611
119
2
ENSMUSG00000119324.1
ENSMUST00000239771.1
68
chr8
124324897
124324947
WT_rep1_peak_64
Promoter (<=1kb)
8
124324897
124325015
119
2
ENSMUSG00000119280.1
ENSMUST00000239832.1
68
chr8
124329986
124330036
WT_rep1_peak_65
Promoter (<=1kb)
8
124329986
124330104
119
2
ENSMUSG00000118796.1
ENSMUST00000240112.1
68
chr8
124331687
124331737
WT_rep1_peak_66
Promoter (<=1kb)
8
124331687
124331805
119
2
ENSMUSG00000119762.1
ENSMUST00000239748.1
68
chr8
124333352
124333402
WT_rep1_peak_67
Promoter (<=1kb)
8
124333352
124333470
119
2
ENSMUSG00000118747.1
ENSMUST00000239942.1
68
chr8
124335059
124335109
WT_rep1_peak_68
Promoter (<=1kb)
8
124335059
124335177
119
2
ENSMUSG00000119615.1
ENSMUST00000240207.1
68
chr8
124336756
124336806
WT_rep1_peak_69
Promoter (<=1kb)
8
124336756
124336874
119
2
ENSMUSG00000118920.1
ENSMUST00000239853.1
68
chr8
124338454
124338504
WT_rep1_peak_70
Promoter (<=1kb)
8
124338454
124338572
119
2
ENSMUSG00000119038.1
ENSMUST00000239899.1
68
chr8
124340153
124340203
WT_rep1_peak_71
Promoter (<=1kb)
8
124340153
124340271
119
2
ENSMUSG00000119414.1
ENSMUST00000239973.1
68
chr8
124341838
124341888
WT_rep1_peak_72
Promoter (<=1kb)
8
124341838
124341956
119
2
ENSMUSG00000119561.1
ENSMUST00000240273.1
68
chr8
124343549
124343599
WT_rep1_peak_73
Promoter (<=1kb)
8
124343549
124343667
119
2
ENSMUSG00000119014.1
ENSMUST00000240509.1
68
chr8
124345275
124345325
WT_rep1_peak_74
Promoter (<=1kb)
8
124345275
124345393
119
2
ENSMUSG00000118870.1
ENSMUST00000240449.1
68
chr8
124346980
124347030
WT_rep1_peak_75
Promoter (<=1kb)
8
124346980
124347098
119
2
ENSMUSG00000118727.1
ENSMUST00000239880.1
68
chr8
124348667
124348717
WT_rep1_peak_76
Promoter (<=1kb)
8
124348667
124348785
119
2
ENSMUSG00000119808.1
ENSMUST00000240201.1
68
chr9
15226535
15226585
WT_rep1_peak_77
Promoter (<=1kb)
9
15226485
15226617
133
1
ENSMUSG00000064634.3
ENSMUST00000082700.3
51
chr9
15237760
15237810
WT_rep1_peak_78
Promoter (<=1kb)
9
15237760
15237835
76
2
ENSMUSG00000077394.3
ENSMUST00000104206.3
25
chr9
21071132
21071182
WT_rep1_peak_79
Promoter (1-2kb)
9
21073005
21111325
38321
1
ENSMUSG00000032177.19
ENSMUST00000249922.1
-1823
chr9
64083993
64084043
WT_rep1_peak_80
Promoter (<=1kb)
9
64083943
64084041
99
1
ENSMUSG00000119765.1
ENSMUST00000083425.3
51
chr9
65103904
65103954
WT_rep1_peak_81
Promoter (<=1kb)
9
65103854
65103969
116
2
ENSMUSG00000118734.1
ENSMUST00000093721.3
15
chr9
88739746
88739796
WT_rep1_peak_82
Promoter (<=1kb)
9
88739746
88739817
72
2
ENSMUSG00000119491.1
ENSMUST00000240516.1
21
chr9
119958505
119958555
WT_rep1_peak_83
Promoter (<=1kb)
9
119958417
119958619
203
1
ENSMUSG00000064380.3
ENSMUST00000082446.3
89
chr9
119958525
119958575
WT_rep1_peak_84
Promoter (<=1kb)
9
119958417
119958619
203
1
ENSMUSG00000064380.3
ENSMUST00000082446.3
109
chr9
119957896
119957946
WT_rep1_peak_85
Promoter (<=1kb)
9
119957872
119959440
1569
1
ENSMUSG00000032518.7
ENSMUST00000215568.2
25
chr9
119959531
119959581
WT_rep1_peak_86
Promoter (<=1kb)
9
119959481
119959629
149
1
ENSMUSG00000064925.3
ENSMUST00000082991.3
51
chr10
40134563
40134613
WT_rep1_peak_87
Promoter (<=1kb)
10
40134463
40134676
214
1
ENSMUSG00002074875.1
ENSMUST00020183530.1
101
chr10
40134563
40134613
WT_rep1_peak_88
Promoter (<=1kb)
10
40134463
40134676
214
1
ENSMUSG00002074875.1
ENSMUST00020183530.1
101
chr10
111317404
111317454
WT_rep1_peak_89
Promoter (<=1kb)
10
111317354
111317497
144
1
ENSMUSG00000087819.3
ENSMUST00000157194.3
51
chr10
121273369
121273419
WT_rep1_peak_90
Intron (ENSMUST00000026902.9/ENSMUSG00000025795.9, intron 1 of 4)
10
121250292
121298118
47827
2
ENSMUSG00000025795.9
ENSMUST00000219500.2
24699
chr10
127150917
127150967
WT_rep1_peak_91
Promoter (1-2kb)
10
127149018
127150017
1000
1
ENSMUSG00000098057.2
ENSMUST00000182369.2
1900
chr11
68964303
68964353
WT_rep1_peak_92
Promoter (<=1kb)
11
68964253
68964387
135
1
ENSMUSG00000064899.3
ENSMUST00000082965.3
51
chr11
69558710
69558760
WT_rep1_peak_93
Promoter (<=1kb)
11
69558660
69558802
143
2
ENSMUSG00000065862.3
ENSMUST00000083928.3
42
chr11
69559728
69559778
WT_rep1_peak_94
Promoter (<=1kb)
11
69559678
69559821
144
2
ENSMUSG00000089542.3
ENSMUST00000158917.3
43
chr11
87362241
87362291
WT_rep1_peak_95
Promoter (<=1kb)
11
87362194
87362409
216
1
ENSMUSG00002075931.1
ENSMUST00020182511.1
48
chr11
87313743
87313793
WT_rep1_peak_96
Promoter (<=1kb)
11
87313693
87313856
164
1
ENSMUSG00000119476.1
ENSMUST00000240501.1
51
chr11
87317592
87317642
WT_rep1_peak_97
Promoter (<=1kb)
11
87317542
87317705
164
1
ENSMUSG00000118815.1
ENSMUST00000093684.3
51
chr11
97884854
97884904
WT_rep1_peak_98
Promoter (1-2kb)
11
97884662
97886755
2094
2
ENSMUSG00000038352.16
ENSMUST00000107563.2
1851
chr11
102171343
102171393
WT_rep1_peak_99
Intron (ENSMUST00000327589.1/ENSMUSG00000134908.1, intron 1 of 1)
11
102170293
102175510
5218
2
ENSMUSG00000134908.1
ENSMUST00000327589.1
4117
chr11
106391819
106391869
WT_rep1_peak_100
Promoter (<=1kb)
11
106391819
106391888
70
1
ENSMUSG00000065126.3
ENSMUST00000083192.3
1
chr
start
end
peaknum
annotation
geneChr
geneStart
geneEnd
geneLength
geneStrand
geneId
transcriptId
distanceToTSS
chr1
24654166
24654216
WT_rep2_peak_1
Promoter (<=1kb)
1
24653966
24654646
681
2
ENSMUSG00000102070.2
ENSMUST00000188231.2
430
chr1
63218213
63218263
WT_rep2_peak_2
Promoter (<=1kb)
1
63218163
63218294
132
1
ENSMUSG00000064602.3
ENSMUST00000082668.3
51
chr1
143654716
143654766
WT_rep2_peak_3
Promoter (<=1kb)
1
143654666
143654800
135
1
ENSMUSG00000088323.3
ENSMUST00000157698.3
51
chr1
153385361
153385411
WT_rep2_peak_4
Intron (ENSMUST00000041874.9/ENSMUSG00000042684.9, intron 10 of 11)
1
153331504
153363406
31903
2
ENSMUSG00000042699.12
ENSMUST00000042141.12
-21956
chr1
160863627
160863677
WT_rep2_peak_5
Promoter (<=1kb)
1
160863627
160863709
83
1
ENSMUSG00000064816.3
ENSMUST00000082882.3
1
chr1
160865652
160865702
WT_rep2_peak_6
Promoter (<=1kb)
1
160865652
160865728
77
1
ENSMUSG00000064968.3
ENSMUST00000083034.3
1
chr1
170855589
170855639
WT_rep2_peak_7
Promoter (<=1kb)
1
170855534
170855698
165
1
ENSMUSG00000065905.3
ENSMUST00000083971.3
56
chr1
170855577
170855627
WT_rep2_peak_8
Promoter (<=1kb)
1
170855534
170855698
165
1
ENSMUSG00000065905.3
ENSMUST00000083971.3
44
chr1
171330666
171330716
WT_rep2_peak_9
Promoter (<=1kb)
1
171330616
171330731
116
2
ENSMUSG00000119640.1
ENSMUST00000083099.3
15
chr2
27429867
27429917
WT_rep2_peak_10
Promoter (<=1kb)
2
27429817
27429942
126
2
ENSMUSG00000080538.3
ENSMUST00000116888.3
25
chr2
102914770
102914820
WT_rep2_peak_11
Promoter (1-2kb)
2
102913302
102922135
8834
1
ENSMUSG00000010911.13
ENSMUST00000155004.2
1469
chr2
130118207
130118257
WT_rep2_peak_12
Promoter (<=1kb)
2
130118220
130119490
1271
1
ENSMUSG00000027405.17
ENSMUST00000160976.2
0
chr2
144103559
144103609
WT_rep2_peak_13
Promoter (<=1kb)
2
144103509
144103646
138
2
ENSMUSG00000065725.3
ENSMUST00000083791.3
37
chr2
166907196
166907246
WT_rep2_peak_14
Promoter (<=1kb)
2
166907196
166907285
90
1
ENSMUSG00000077698.3
ENSMUST00000104510.3
1
chr3
52630108
52630158
WT_rep2_peak_15
Promoter (<=1kb)
3
52630070
52630176
107
2
ENSMUSG00000119552.1
ENSMUST00000239592.1
18
chr3
96147265
96147315
WT_rep2_peak_16
Promoter (<=1kb)
3
96147184
96147321
138
1
ENSMUSG00002076697.1
ENSMUST00020181968.1
82
chr3
96153142
96153192
WT_rep2_peak_17
Promoter (<=1kb)
3
96153142
96153279
138
2
ENSMUSG00002076967.1
ENSMUST00020182038.1
87
chr3
96235791
96235841
WT_rep2_peak_18
Promoter (<=1kb)
3
96235741
96235906
166
1
ENSMUSG00000119427.1
ENSMUST00000239827.1
51
chr3
96281387
96281437
WT_rep2_peak_19
Promoter (<=1kb)
3
96281337
96281501
165
1
ENSMUSG00000119030.1
ENSMUST00000240438.1
51
chr3
96357804
96357854
WT_rep2_peak_20
Promoter (<=1kb)
3
96357762
96357927
166
1
ENSMUSG00000119774.1
ENSMUST00000083839.3
43
chr3
96357812
96357862
WT_rep2_peak_21
Promoter (<=1kb)
3
96357762
96357927
166
1
ENSMUSG00000119774.1
ENSMUST00000083839.3
51
chr3
96367424
96367474
WT_rep2_peak_22
Promoter (<=1kb)
3
96367340
96367505
166
2
ENSMUSG00000118677.1
ENSMUST00000240510.1
31
chr3
96367440
96367490
WT_rep2_peak_23
Promoter (<=1kb)
3
96367340
96367505
166
2
ENSMUSG00000118677.1
ENSMUST00000240510.1
15
chr3
96393950
96394000
WT_rep2_peak_24
Promoter (<=1kb)
3
96393871
96394035
165
2
ENSMUSG00000118698.1
ENSMUST00000239775.1
35
chr4
43492833
43492883
WT_rep2_peak_25
Promoter (<=1kb)
4
43492900
43494205
1306
1
ENSMUSG00000028461.13
ENSMUST00000143073.8
-17
chr4
43492883
43492933
WT_rep2_peak_26
Promoter (<=1kb)
4
43492900
43494205
1306
1
ENSMUSG00000028461.13
ENSMUST00000143073.8
0
chr4
43492838
43492888
WT_rep2_peak_27
Promoter (<=1kb)
4
43492900
43494205
1306
1
ENSMUSG00000028461.13
ENSMUST00000143073.8
-12
chr4
43492900
43492950
WT_rep2_peak_28
Promoter (<=1kb)
4
43492900
43494205
1306
1
ENSMUSG00000028461.13
ENSMUST00000143073.8
1
chr4
51812533
51812583
WT_rep2_peak_29
Promoter (<=1kb)
4
51812483
51812647
165
2
ENSMUSG00000064923.2
ENSMUST00000082989.2
64
chr4
119227113
119227163
WT_rep2_peak_30
Intron (ENSMUST00000238759.2/ENSMUSG00000028637.17, intron 5 of 14)
4
119209443
119230950
21508
2
ENSMUSG00000028637.17
ENSMUST00000238779.2
3787
chr4
131997445
131997495
WT_rep2_peak_31
Promoter (<=1kb)
4
131997391
131997524
134
2
ENSMUSG00000077323.3
ENSMUST00000104135.3
29
chr4
131997441
131997491
WT_rep2_peak_32
Promoter (<=1kb)
4
131997391
131997524
134
2
ENSMUSG00000077323.3
ENSMUST00000104135.3
33
chr4
132037302
132037352
WT_rep2_peak_33
Promoter (<=1kb)
4
132037252
132037380
129
1
ENSMUSG00000064604.3
ENSMUST00000082670.3
51
chr4
132037601
132037651
WT_rep2_peak_34
Promoter (<=1kb)
4
132037572
132038335
764
1
ENSMUSG00000086290.12
ENSMUST00000303243.1
30
chr5
74253903
74253953
WT_rep2_peak_35
Promoter (<=1kb)
5
74252426
74253973
1548
2
ENSMUSG00000128868.1
ENSMUST00000290359.1
20
chr5
74254241
74254291
WT_rep2_peak_36
Promoter (<=1kb)
5
74254191
74254311
121
1
ENSMUSG00000093355.3
ENSMUST00000175614.3
51
chr5
92203973
92204023
WT_rep2_peak_37
Promoter (<=1kb)
5
92203923
92204051
129
2
ENSMUSG00000088712.3
ENSMUST00000158087.3
28
chr5
100577238
100577288
WT_rep2_peak_38
Promoter (<=1kb)
5
100575626
100577296
1671
2
ENSMUSG00000097772.10
ENSMUST00000326650.1
8
chr5
115627518
115627568
WT_rep2_peak_39
Promoter (<=1kb)
5
115627518
115628584
1067
1
ENSMUSG00000132950.1
ENSMUST00000315073.1
1
chr5
118567725
118567775
WT_rep2_peak_40
Intron (ENSMUST00000279925.1/ENSMUSG00000127080.1, intron 1 of 1)
5
118563375
118571739
8365
1
ENSMUSG00000127080.1
ENSMUST00000279925.1
4351
chr5
125486088
125486138
WT_rep2_peak_41
Promoter (<=1kb)
5
125483388
125486552
3165
2
ENSMUSG00000132160.1
ENSMUST00000310468.1
414
chr5
129866653
129866703
WT_rep2_peak_42
Promoter (<=1kb)
5
129866745
129869120
2376
1
ENSMUSG00000029447.14
ENSMUST00000202854.5
-42
chr5
129871659
129871709
WT_rep2_peak_43
Promoter (<=1kb)
5
129871609
129871739
131
1
ENSMUSG00000093413.3
ENSMUST00000177461.3
51
chr5
146772004
146772054
WT_rep2_peak_44
Promoter (<=1kb)
5
146772016
146772796
781
1
ENSMUSG00000041453.13
ENSMUST00000135345.2
0
chr6
47755215
47755265
WT_rep2_peak_45
Promoter (<=1kb)
6
47755311
47757431
2121
1
ENSMUSG00000126201.1
ENSMUST00000275052.1
-46
chr6
47758557
47758607
WT_rep2_peak_46
Promoter (<=1kb)
6
47758558
47758659
102
1
ENSMUSG00000064945.3
ENSMUST00000083011.3
0
chr6
47758558
47758608
WT_rep2_peak_47
Promoter (<=1kb)
6
47758558
47758659
102
1
ENSMUSG00000064945.3
ENSMUST00000083011.3
1
chr6
69493465
69493515
WT_rep2_peak_48
Promoter (<=1kb)
6
69493465
69493534
70
1
ENSMUSG00002075625.1
ENSMUST00020181981.1
1
chr6
71859591
71859641
WT_rep2_peak_49
Promoter (<=1kb)
6
71857622
71859579
1958
2
ENSMUSG00000063884.7
ENSMUST00000205269.2
-13
chr6
124692335
124692385
WT_rep2_peak_50
Promoter (<=1kb)
6
124692326
124693502
1177
1
ENSMUSG00000004264.18
ENSMUST00000129422.2
10
chr6
125098737
125098787
WT_rep2_peak_51
Promoter (<=1kb)
6
125098687
125098822
136
1
ENSMUSG00000088208.3
ENSMUST00000157583.3
51
chr7
28050983
28051033
WT_rep2_peak_52
Promoter (<=1kb)
7
28050933
28051057
125
1
ENSMUSG00000077711.3
ENSMUST00000104523.3
51
chr7
83972536
83972586
WT_rep2_peak_53
Promoter (<=1kb)
7
83972517
83972623
107
2
ENSMUSG00000119308.1
ENSMUST00000240311.1
37
chr7
99128820
99128870
WT_rep2_peak_54
Promoter (<=1kb)
7
99128770
99128914
145
2
ENSMUSG00000064966.3
ENSMUST00000083032.3
44
chr7
99132042
99132092
WT_rep2_peak_55
Promoter (<=1kb)
7
99131992
99132139
148
2
ENSMUSG00000065822.3
ENSMUST00000083888.3
47
chr7
109120537
109120587
WT_rep2_peak_56
Promoter (<=1kb)
7
109120487
109120616
130
1
ENSMUSG00000077575.3
ENSMUST00000104387.3
51
chr7
109645621
109645671
WT_rep2_peak_57
Promoter (<=1kb)
7
109645571
109645754
184
1
ENSMUSG00000064451.3
ENSMUST00000082517.3
51
chr7
127127096
127127146
WT_rep2_peak_58
Promoter (<=1kb)
7
127127046
127127175
130
1
ENSMUSG00000065259.3
ENSMUST00000083325.3
51
chr7
141028766
141028816
WT_rep2_peak_59
Promoter (<=1kb)
7
141028716
141028852
137
1
ENSMUSG00000064666.3
ENSMUST00000082732.3
51
chr8
52790050
52790100
WT_rep2_peak_60
Promoter (<=1kb)
8
52789950
52790140
191
2
ENSMUSG00000064682.3
ENSMUST00000082748.3
40
chr8
105210401
105210451
WT_rep2_peak_61
Intron (ENSMUST00000064576.8/ENSMUSG00000052616.11, intron 12 of 19)
8
105234534
105234640
107
1
ENSMUSG00000077633.3
ENSMUST00000104445.3
-24083
chr8
123829777
123829827
WT_rep2_peak_62
Promoter (<=1kb)
8
123829777
123829862
86
1
ENSMUSG00000064450.3
ENSMUST00000082516.3
1
chr8
124312981
124313031
WT_rep2_peak_63
Promoter (<=1kb)
8
124312981
124313099
119
2
ENSMUSG00001118664.1
ENSMUST00000240133.1
68
chr8
124323196
124323246
WT_rep2_peak_64
Promoter (<=1kb)
8
124323196
124323314
119
2
ENSMUSG00000119587.1
ENSMUST00000240236.1
68
chr8
124329986
124330036
WT_rep2_peak_65
Promoter (<=1kb)
8
124329986
124330104
119
2
ENSMUSG00000118796.1
ENSMUST00000240112.1
68
chr8
124331687
124331737
WT_rep2_peak_66
Promoter (<=1kb)
8
124331687
124331805
119
2
ENSMUSG00000119762.1
ENSMUST00000239748.1
68
chr8
124333352
124333402
WT_rep2_peak_67
Promoter (<=1kb)
8
124333352
124333470
119
2
ENSMUSG00000118747.1
ENSMUST00000239942.1
68
chr8
124335059
124335109
WT_rep2_peak_68
Promoter (<=1kb)
8
124335059
124335177
119
2
ENSMUSG00000119615.1
ENSMUST00000240207.1
68
chr8
124336756
124336806
WT_rep2_peak_69
Promoter (<=1kb)
8
124336756
124336874
119
2
ENSMUSG00000118920.1
ENSMUST00000239853.1
68
chr8
124338454
124338504
WT_rep2_peak_70
Promoter (<=1kb)
8
124338454
124338572
119
2
ENSMUSG00000119038.1
ENSMUST00000239899.1
68
chr8
124340153
124340203
WT_rep2_peak_71
Promoter (<=1kb)
8
124340153
124340271
119
2
ENSMUSG00000119414.1
ENSMUST00000239973.1
68
chr8
124341838
124341888
WT_rep2_peak_72
Promoter (<=1kb)
8
124341838
124341956
119
2
ENSMUSG00000119561.1
ENSMUST00000240273.1
68
chr8
124345275
124345325
WT_rep2_peak_73
Promoter (<=1kb)
8
124345275
124345393
119
2
ENSMUSG00000118870.1
ENSMUST00000240449.1
68
chr8
124346980
124347030
WT_rep2_peak_74
Promoter (<=1kb)
8
124346980
124347098
119
2
ENSMUSG00000118727.1
ENSMUST00000239880.1
68
chr8
124348667
124348717
WT_rep2_peak_75
Promoter (<=1kb)
8
124348667
124348785
119
2
ENSMUSG00000119808.1
ENSMUST00000240201.1
68
chr8
127671647
127671697
WT_rep2_peak_76
Promoter (<=1kb)
8
127671597
127671730
134
2
ENSMUSG00000065637.3
ENSMUST00000083703.3
33
chr9
15237760
15237810
WT_rep2_peak_77
Promoter (<=1kb)
9
15237760
15237835
76
2
ENSMUSG00000077394.3
ENSMUST00000104206.3
25
chr9
61820666
61820716
WT_rep2_peak_78
Promoter (1-2kb)
9
61820566
61821824
1259
2
ENSMUSG00000007892.9
ENSMUST00000008036.9
1108
chr9
61821666
61821716
WT_rep2_peak_79
Promoter (<=1kb)
9
61820566
61821824
1259
2
ENSMUSG00000007892.9
ENSMUST00000008036.9
108
chr9
64203263
64203313
WT_rep2_peak_80
Promoter (<=1kb)
9
64203213
64203347
135
1
ENSMUSG00000088254.3
ENSMUST00000157629.3
51
chr9
65103907
65103957
WT_rep2_peak_81
Promoter (<=1kb)
9
65103854
65103969
116
2
ENSMUSG00000118734.1
ENSMUST00000093721.3
12
chr9
65103904
65103954
WT_rep2_peak_82
Promoter (<=1kb)
9
65103854
65103969
116
2
ENSMUSG00000118734.1
ENSMUST00000093721.3
15
chr9
65109058
65109108
WT_rep2_peak_83
Promoter (<=1kb)
9
65109008
65109123
116
2
ENSMUSG00000119286.1
ENSMUST00000101817.3
15
chr9
78082635
78082685
WT_rep2_peak_84
Promoter (<=1kb)
9
78082585
78082915
331
2
ENSMUSG00002076161.1
ENSMUST00020183253.1
230
chr10
111317404
111317454
WT_rep2_peak_85
Promoter (<=1kb)
10
111317354
111317497
144
1
ENSMUSG00000087819.3
ENSMUST00000157194.3
51
chr11
48753995
48754045
WT_rep2_peak_86
Exon (ENSMUST00000147151.2/ENSMUSG00000046879.8, exon 2 of 2)
11
48745257
48749020
3764
2
ENSMUSG00000132080.1
ENSMUST00000310045.1
-4976
chr11
68964303
68964353
WT_rep2_peak_87
Promoter (<=1kb)
11
68964253
68964387
135
1
ENSMUSG00000064899.3
ENSMUST00000082965.3
51
chr11
69558710
69558760
WT_rep2_peak_88
Promoter (<=1kb)
11
69558660
69558802
143
2
ENSMUSG00000065862.3
ENSMUST00000083928.3
42
chr11
87313741
87313791
WT_rep2_peak_89
Promoter (<=1kb)
11
87313693
87313856
164
1
ENSMUSG00000119476.1
ENSMUST00000240501.1
49
chr11
87313743
87313793
WT_rep2_peak_90
Promoter (<=1kb)
11
87313693
87313856
164
1
ENSMUSG00000119476.1
ENSMUST00000240501.1
51
chr11
87317592
87317642
WT_rep2_peak_91
Promoter (<=1kb)
11
87317542
87317705
164
1
ENSMUSG00000118815.1
ENSMUST00000093684.3
51
chr11
97672515
97672565
WT_rep2_peak_92
Promoter (<=1kb)
11
97672465
97672601
137
2
ENSMUSG00000064901.3
ENSMUST00000082967.3
36
chr11
106391819
106391869
WT_rep2_peak_93
Promoter (<=1kb)
11
106391819
106391888
70
1
ENSMUSG00000065126.3
ENSMUST00000083192.3
1
chr11
116968174
116968224
WT_rep2_peak_94
Promoter (<=1kb)
11
116968174
116968283
110
1
ENSMUSG00000104740.3
ENSMUST00000196236.3
1
chr12
54776430
54776480
WT_rep2_peak_95
Promoter (<=1kb)
12
54776380
54776543
164
1
ENSMUSG00000118751.1
ENSMUST00000240287.1
51
chr12
69206068
69206118
WT_rep2_peak_96
Promoter (<=1kb)
12
69206069
69206368
300
1
ENSMUSG00000118866.1
ENSMUST00000175032.4
0
chr12
69206118
69206168
WT_rep2_peak_97
Promoter (<=1kb)
12
69206211
69206280
70
1
ENSMUSG00002076451.1
ENSMUST00020183515.1
-43
chr12
69206218
69206268
WT_rep2_peak_98
Promoter (<=1kb)
12
69206211
69206280
70
1
ENSMUSG00002076451.1
ENSMUST00020183515.1
8
chr12
69206268
69206318
WT_rep2_peak_99
Promoter (<=1kb)
12
69206292
69206370
79
1
ENSMUSG00002075000.1
ENSMUST00020183101.1
0
chr12
69206069
69206119
WT_rep2_peak_100
Promoter (<=1kb)
12
69206069
69206368
300
1
ENSMUSG00000118866.1
ENSMUST00000175032.4
1
❯
上表第一列到第三列为peak在基因组位置;第五列annotation为peak的基因组功能元件身份;第六列到第十列为关联基因的位置信息; 第十一列geneId为基因ID;第十二列transcriptId为转录本ID;第十三列distanceToTSS为peak到TSS距离。
7. 基因富集分析
我们使用clusterprofiler(version 4.14.6)(Wu T. et al., 2021)进行GO和KEGG通路富集分析。富集分析结果表格未使用阈值过滤,您可以在表格中查看所有可能富集的通路。
7.1 GO富集分析
GO (Gene Ontology, http://www.geneontology.org) 是基因本体论联合会建立的将全世界所有与基因有关的研究结果进行分类汇总的综合数据库。该数据库标准化了不同数据库中关于基因和基因产物的生物学术语,适用于各物种,对基因和蛋白功能进行限定和描述。利用GO 数据库,可以对peak峰相关基因进行富集分析,可以找到不同条件下的peak峰相关基因按照其参与的BP(Biological Process, 生物过程)、MF(Molecular Function, 分子功能) 及CC(Cellular Component, 细胞组分) 三个方面进行分类注释。GO 注释有助于理解基因背后所代表的生物学意义。GO功能显著性富集分析给出与基因组背景相比,在相关基因中显著富集的GO功能条目,从而给出与peak峰相关基因与哪些生物学功能显著相关。该分析首先把所有相关向Gene Ontology数据库的各个term映射,计算每个term的基因数目,然后应用超几何检验,找出与整个基因组背景相比,在与peak峰相关基因中显著富集的GO条目。
下面展示peak关联的基因富集GO富集分析部分结果,完整结果请见/result/6.gokegg/GOALLterm_peakanno_*.csv。GO富集分析完整结果请详见位于report/result/6.gokegg 文件夹的*_GO_res.csv表格文件。
Setd2-KO_GO_res Setd2-KO_rep1_GO_res Setd2-KO_rep2_GO_res WT_GO_res WT_rep1_GO_res WT_rep2_GO_res
❮
ONTOLOGY
ID
Description
GeneRatio
BgRatio
RichFactor
FoldEnrichment
zScore
pvalue
p.adjust
qvalue
geneID
Count
BP
GO:0002181
cytoplasmic translation
7/48
142/22777
0.049
23.392
12.300
0.000
0.000
0.000
ENSMUSG00000042699/ENSMUSG00000059796/ENSMUSG00000022884/ENSMUSG00000044533/ENSMUSG00000041453/ENSMUSG00000074129/ENSMUSG00000032518
7
BP
GO:0002183
cytoplasmic translational initiation
3/48
27/22777
0.111
52.725
12.358
0.000
0.005
0.005
ENSMUSG00000059796/ENSMUSG00000022884/ENSMUSG00000074129
3
BP
GO:2000765
regulation of cytoplasmic translation
2/48
27/22777
0.074
35.150
8.159
0.001
0.188
0.175
ENSMUSG00000042699/ENSMUSG00000074129
2
BP
GO:0006413
translational initiation
3/48
115/22777
0.026
12.379
5.622
0.002
0.188
0.175
ENSMUSG00000059796/ENSMUSG00000022884/ENSMUSG00000074129
3
BP
GO:0070269
pyroptotic inflammatory response
2/48
40/22777
0.050
23.726
6.611
0.003
0.264
0.245
ENSMUSG00000042699/ENSMUSG00000010911
2
BP
GO:0022618
protein-RNA complex assembly
3/48
168/22777
0.018
8.474
4.468
0.005
0.355
0.330
ENSMUSG00000042699/ENSMUSG00000074129/ENSMUSG00000032518
3
BP
GO:0071826
protein-RNA complex organization
3/48
176/22777
0.017
8.088
4.338
0.006
0.355
0.330
ENSMUSG00000042699/ENSMUSG00000074129/ENSMUSG00000032518
3
BP
GO:0022613
ribonucleoprotein complex biogenesis
4/48
417/22777
0.010
4.552
3.364
0.011
0.377
0.351
ENSMUSG00000042699/ENSMUSG00000027405/ENSMUSG00000074129/ENSMUSG00000032518
4
BP
GO:0001731
formation of translation preinitiation complex
1/48
10/22777
0.100
47.452
6.752
0.021
0.377
0.351
ENSMUSG00000074129
1
BP
GO:0010501
RNA secondary structure unwinding
1/48
10/22777
0.100
47.452
6.752
0.021
0.377
0.351
ENSMUSG00000042699
1
BP
GO:0032661
regulation of interleukin-18 production
1/48
10/22777
0.100
47.452
6.752
0.021
0.377
0.351
ENSMUSG00000042699
1
BP
GO:0046543
development of secondary female sexual characteristics
1/48
10/22777
0.100
47.452
6.752
0.021
0.377
0.351
ENSMUSG00000004264
1
BP
GO:0070934
CRD-mediated mRNA stabilization
1/48
10/22777
0.100
47.452
6.752
0.021
0.377
0.351
ENSMUSG00000042699
1
BP
GO:1904959
regulation of cytochrome-c oxidase activity
1/48
10/22777
0.100
47.452
6.752
0.021
0.377
0.351
ENSMUSG00000004264
1
BP
GO:0070213
protein auto-ADP-ribosylation
1/48
11/22777
0.091
43.138
6.424
0.023
0.377
0.351
ENSMUSG00000036023
1
BP
GO:1900152
negative regulation of nuclear-transcribed mRNA catabolic process, deadenylation-dependent decay
1/48
11/22777
0.091
43.138
6.424
0.023
0.377
0.351
ENSMUSG00000042699
1
BP
GO:1904732
regulation of electron transfer activity
1/48
11/22777
0.091
43.138
6.424
0.023
0.377
0.351
ENSMUSG00000004264
1
BP
GO:0032621
interleukin-18 production
1/48
12/22777
0.083
39.543
6.137
0.025
0.377
0.351
ENSMUSG00000042699
1
BP
GO:0009086
methionine biosynthetic process
1/48
13/22777
0.077
36.502
5.884
0.027
0.377
0.351
ENSMUSG00000010911
1
BP
GO:0045136
development of secondary sexual characteristics
1/48
13/22777
0.077
36.502
5.884
0.027
0.377
0.351
ENSMUSG00000004264
1
BP
GO:0046831
regulation of RNA export from nucleus
1/48
13/22777
0.077
36.502
5.884
0.027
0.377
0.351
ENSMUSG00000042699
1
BP
GO:0018342
protein prenylation
1/48
14/22777
0.071
33.894
5.658
0.029
0.377
0.351
ENSMUSG00000038975
1
BP
GO:0097354
prenylation
1/48
14/22777
0.071
33.894
5.658
0.029
0.377
0.351
ENSMUSG00000038975
1
BP
GO:2000767
positive regulation of cytoplasmic translation
1/48
14/22777
0.071
33.894
5.658
0.029
0.377
0.351
ENSMUSG00000042699
1
BP
GO:0006555
methionine metabolic process
1/48
15/22777
0.067
31.635
5.454
0.031
0.377
0.351
ENSMUSG00000010911
1
BP
GO:0033147
negative regulation of intracellular estrogen receptor signaling pathway
1/48
15/22777
0.067
31.635
5.454
0.031
0.377
0.351
ENSMUSG00000004264
1
BP
GO:0071360
cellular response to exogenous dsRNA
1/48
15/22777
0.067
31.635
5.454
0.031
0.377
0.351
ENSMUSG00000042699
1
BP
GO:0032543
mitochondrial translation
2/48
132/22777
0.015
7.190
3.277
0.032
0.377
0.351
ENSMUSG00000063884/ENSMUSG00000035202
2
BP
GO:0000097
sulfur amino acid biosynthetic process
1/48
16/22777
0.062
29.658
5.270
0.033
0.377
0.351
ENSMUSG00000010911
1
BP
GO:0023035
CD40 signaling pathway
1/48
16/22777
0.062
29.658
5.270
0.033
0.377
0.351
ENSMUSG00000004264
1
BP
GO:0032048
cardiolipin metabolic process
1/48
16/22777
0.062
29.658
5.270
0.033
0.377
0.351
ENSMUSG00000004264
1
BP
GO:0032239
regulation of nucleobase-containing compound transport
1/48
16/22777
0.062
29.658
5.270
0.033
0.377
0.351
ENSMUSG00000042699
1
BP
GO:0007096
regulation of exit from mitosis
1/48
17/22777
0.059
27.913
5.101
0.035
0.377
0.351
ENSMUSG00000004264
1
BP
GO:0045947
negative regulation of translational initiation
1/48
17/22777
0.059
27.913
5.101
0.035
0.377
0.351
ENSMUSG00000074129
1
BP
GO:2000637
positive regulation of miRNA-mediated gene silencing
1/48
17/22777
0.059
27.913
5.101
0.035
0.377
0.351
ENSMUSG00000042699
1
BP
GO:0019081
viral translation
1/48
18/22777
0.056
26.362
4.947
0.037
0.377
0.351
ENSMUSG00000042699
1
BP
GO:0060148
positive regulation of post-transcriptional gene silencing
1/48
18/22777
0.056
26.362
4.947
0.037
0.377
0.351
ENSMUSG00000042699
1
BP
GO:0061051
positive regulation of cell growth involved in cardiac muscle cell development
1/48
18/22777
0.056
26.362
4.947
0.037
0.377
0.351
ENSMUSG00000036023
1
BP
GO:1900370
positive regulation of post-transcriptional gene silencing by RNA
1/48
18/22777
0.056
26.362
4.947
0.037
0.377
0.351
ENSMUSG00000042699
1
BP
GO:0000028
ribosomal small subunit assembly
1/48
20/22777
0.050
23.726
4.673
0.041
0.377
0.351
ENSMUSG00000032518
1
BP
GO:0033599
regulation of mammary gland epithelial cell proliferation
1/48
20/22777
0.050
23.726
4.673
0.041
0.377
0.351
ENSMUSG00000004264
1
BP
GO:0009067
aspartate family amino acid biosynthetic process
1/48
21/22777
0.048
22.596
4.550
0.043
0.377
0.351
ENSMUSG00000010911
1
BP
GO:0071359
cellular response to dsRNA
1/48
21/22777
0.048
22.596
4.550
0.043
0.377
0.351
ENSMUSG00000042699
1
BP
GO:0046782
regulation of viral transcription
1/48
22/22777
0.045
21.569
4.436
0.045
0.377
0.351
ENSMUSG00000042699
1
BP
GO:0060749
mammary gland alveolus development
1/48
22/22777
0.045
21.569
4.436
0.045
0.377
0.351
ENSMUSG00000004264
1
BP
GO:0061377
mammary gland lobule development
1/48
22/22777
0.045
21.569
4.436
0.045
0.377
0.351
ENSMUSG00000004264
1
BP
GO:0071398
cellular response to fatty acid
1/48
22/22777
0.045
21.569
4.436
0.045
0.377
0.351
ENSMUSG00000086859
1
BP
GO:0140053
mitochondrial gene expression
2/48
167/22777
0.012
5.683
2.791
0.048
0.377
0.351
ENSMUSG00000063884/ENSMUSG00000035202
2
BP
GO:0006353
DNA-templated transcription termination
1/48
25/22777
0.040
18.981
4.134
0.051
0.377
0.351
ENSMUSG00000042699
1
BP
GO:0046697
decidualization
1/48
25/22777
0.040
18.981
4.134
0.051
0.377
0.351
ENSMUSG00000036023
1
BP
GO:0039529
RIG-I signaling pathway
1/48
26/22777
0.038
18.251
4.045
0.053
0.377
0.351
ENSMUSG00000004264
1
BP
GO:1900151
regulation of nuclear-transcribed mRNA catabolic process, deadenylation-dependent decay
1/48
26/22777
0.038
18.251
4.045
0.053
0.377
0.351
ENSMUSG00000042699
1
BP
GO:0006417
regulation of translation
3/48
408/22777
0.007
3.489
2.331
0.055
0.377
0.351
ENSMUSG00000042699/ENSMUSG00000063884/ENSMUSG00000074129
3
BP
GO:0032727
positive regulation of interferon-alpha production
1/48
27/22777
0.037
17.575
3.960
0.055
0.377
0.351
ENSMUSG00000042699
1
BP
GO:0051443
positive regulation of ubiquitin-protein transferase activity
1/48
27/22777
0.037
17.575
3.960
0.055
0.377
0.351
ENSMUSG00000044533
1
BP
GO:0046471
phosphatidylglycerol metabolic process
1/48
28/22777
0.036
16.947
3.880
0.057
0.377
0.351
ENSMUSG00000004264
1
BP
GO:0060444
branching involved in mammary gland duct morphogenesis
1/48
29/22777
0.034
16.363
3.804
0.059
0.377
0.351
ENSMUSG00000004264
1
BP
GO:0071353
cellular response to interleukin-4
1/48
30/22777
0.033
15.817
3.732
0.061
0.377
0.351
ENSMUSG00000044533
1
BP
GO:0140374
antiviral innate immune response
1/48
30/22777
0.033
15.817
3.732
0.061
0.377
0.351
ENSMUSG00000004264
1
BP
GO:0010458
exit from mitosis
1/48
31/22777
0.032
15.307
3.663
0.063
0.377
0.351
ENSMUSG00000004264
1
BP
GO:0032647
regulation of interferon-alpha production
1/48
32/22777
0.031
14.829
3.597
0.065
0.377
0.351
ENSMUSG00000042699
1
BP
GO:0070670
response to interleukin-4
1/48
32/22777
0.031
14.829
3.597
0.065
0.377
0.351
ENSMUSG00000044533
1
BP
GO:0000096
sulfur amino acid metabolic process
1/48
33/22777
0.030
14.379
3.535
0.067
0.377
0.351
ENSMUSG00000010911
1
BP
GO:0010155
regulation of proton transport
1/48
33/22777
0.030
14.379
3.535
0.067
0.377
0.351
ENSMUSG00000004264
1
BP
GO:0033598
mammary gland epithelial cell proliferation
1/48
33/22777
0.030
14.379
3.535
0.067
0.377
0.351
ENSMUSG00000004264
1
BP
GO:0060964
regulation of miRNA-mediated gene silencing
1/48
34/22777
0.029
13.956
3.474
0.069
0.377
0.351
ENSMUSG00000042699
1
BP
GO:0061050
regulation of cell growth involved in cardiac muscle cell development
1/48
34/22777
0.029
13.956
3.474
0.069
0.377
0.351
ENSMUSG00000036023
1
BP
GO:0017148
negative regulation of translation
2/48
208/22777
0.010
4.563
2.372
0.071
0.377
0.351
ENSMUSG00000042699/ENSMUSG00000074129
2
BP
GO:0032607
interferon-alpha production
1/48
35/22777
0.029
13.558
3.417
0.071
0.377
0.351
ENSMUSG00000042699
1
BP
GO:0043094
cellular metabolic compound salvage
1/48
35/22777
0.029
13.558
3.417
0.071
0.377
0.351
ENSMUSG00000010911
1
BP
GO:0001893
maternal placenta development
1/48
36/22777
0.028
13.181
3.361
0.073
0.377
0.351
ENSMUSG00000036023
1
BP
GO:0070542
response to fatty acid
1/48
36/22777
0.028
13.181
3.361
0.073
0.377
0.351
ENSMUSG00000086859
1
BP
GO:1900368
regulation of post-transcriptional gene silencing by regulatory ncRNA
1/48
36/22777
0.028
13.181
3.361
0.073
0.377
0.351
ENSMUSG00000042699
1
BP
GO:0033146
regulation of intracellular estrogen receptor signaling pathway
1/48
37/22777
0.027
12.825
3.308
0.075
0.377
0.351
ENSMUSG00000004264
1
BP
GO:0060147
regulation of post-transcriptional gene silencing
1/48
37/22777
0.027
12.825
3.308
0.075
0.377
0.351
ENSMUSG00000042699
1
BP
GO:0034248
regulation of amide metabolic process
3/48
470/22777
0.006
3.029
2.042
0.076
0.377
0.351
ENSMUSG00000042699/ENSMUSG00000063884/ENSMUSG00000074129
3
BP
GO:0000423
mitophagy
1/48
38/22777
0.026
12.487
3.257
0.077
0.377
0.351
ENSMUSG00000004264
1
BP
GO:0060966
regulation of gene silencing by regulatory ncRNA
1/48
38/22777
0.026
12.487
3.257
0.077
0.377
0.351
ENSMUSG00000042699
1
BP
GO:0006284
base-excision repair
1/48
40/22777
0.025
11.863
3.160
0.081
0.377
0.351
ENSMUSG00000036023
1
BP
GO:0033144
negative regulation of intracellular steroid hormone receptor signaling pathway
1/48
40/22777
0.025
11.863
3.160
0.081
0.377
0.351
ENSMUSG00000004264
1
BP
GO:1903725
regulation of phospholipid metabolic process
1/48
40/22777
0.025
11.863
3.160
0.081
0.377
0.351
ENSMUSG00000004264
1
BP
GO:0006418
tRNA aminoacylation for protein translation
1/48
41/22777
0.024
11.574
3.114
0.083
0.377
0.351
ENSMUSG00000035202
1
BP
GO:0009066
aspartate family amino acid metabolic process
1/48
41/22777
0.024
11.574
3.114
0.083
0.377
0.351
ENSMUSG00000010911
1
BP
GO:0060603
mammary gland duct morphogenesis
1/48
41/22777
0.024
11.574
3.114
0.083
0.377
0.351
ENSMUSG00000004264
1
BP
GO:0010613
positive regulation of cardiac muscle hypertrophy
1/48
42/22777
0.024
11.298
3.070
0.085
0.377
0.351
ENSMUSG00000036023
1
BP
GO:0034249
negative regulation of amide metabolic process
2/48
231/22777
0.009
4.108
2.182
0.085
0.377
0.351
ENSMUSG00000042699/ENSMUSG00000074129
2
BP
GO:0014742
positive regulation of muscle hypertrophy
1/48
43/22777
0.023
11.035
3.027
0.087
0.377
0.351
ENSMUSG00000036023
1
BP
GO:0032508
DNA duplex unwinding
1/48
44/22777
0.023
10.785
2.985
0.089
0.377
0.351
ENSMUSG00000042699
1
BP
GO:0043039
tRNA aminoacylation
1/48
44/22777
0.023
10.785
2.985
0.089
0.377
0.351
ENSMUSG00000035202
1
BP
GO:0050691
regulation of defense response to virus by host
1/48
44/22777
0.023
10.785
2.985
0.089
0.377
0.351
ENSMUSG00000042699
1
BP
GO:0032781
positive regulation of ATP-dependent activity
1/48
45/22777
0.022
10.545
2.945
0.091
0.377
0.351
ENSMUSG00000042699
1
BP
GO:0043038
amino acid activation
1/48
45/22777
0.022
10.545
2.945
0.091
0.377
0.351
ENSMUSG00000035202
1
BP
GO:0048246
macrophage chemotaxis
1/48
47/22777
0.021
10.096
2.869
0.094
0.377
0.351
ENSMUSG00000074129
1
BP
GO:0055023
positive regulation of cardiac muscle tissue growth
1/48
47/22777
0.021
10.096
2.869
0.094
0.377
0.351
ENSMUSG00000036023
1
BP
GO:0140236
translation at presynapse
1/48
47/22777
0.021
10.096
2.869
0.094
0.377
0.351
ENSMUSG00000074129
1
BP
GO:0003298
physiological muscle hypertrophy
1/48
48/22777
0.021
9.886
2.832
0.096
0.377
0.351
ENSMUSG00000036023
1
BP
GO:0003301
physiological cardiac muscle hypertrophy
1/48
48/22777
0.021
9.886
2.832
0.096
0.377
0.351
ENSMUSG00000036023
1
BP
GO:0061049
cell growth involved in cardiac muscle cell development
1/48
48/22777
0.021
9.886
2.832
0.096
0.377
0.351
ENSMUSG00000036023
1
BP
GO:0140241
translation at synapse
1/48
48/22777
0.021
9.886
2.832
0.096
0.377
0.351
ENSMUSG00000074129
1
BP
GO:0140242
translation at postsynapse
1/48
48/22777
0.021
9.886
2.832
0.096
0.377
0.351
ENSMUSG00000074129
1
ONTOLOGY
ID
Description
GeneRatio
BgRatio
RichFactor
FoldEnrichment
zScore
pvalue
p.adjust
qvalue
geneID
Count
BP
GO:0002181
cytoplasmic translation
5/50
142/22777
0.035
16.040
8.433
0.000
0.009
0.008
ENSMUSG00000042699/ENSMUSG00000041453/ENSMUSG00000074129/ENSMUSG00000032518/ENSMUSG00000044533
5
BP
GO:0032661
regulation of interleukin-18 production
2/50
10/22777
0.200
91.108
13.368
0.000
0.060
0.055
ENSMUSG00000042699/ENSMUSG00000027995
2
BP
GO:0032621
interleukin-18 production
2/50
12/22777
0.167
75.923
12.177
0.000
0.060
0.055
ENSMUSG00000042699/ENSMUSG00000027995
2
BP
GO:2000765
regulation of cytoplasmic translation
2/50
27/22777
0.074
33.744
7.985
0.002
0.236
0.216
ENSMUSG00000042699/ENSMUSG00000074129
2
BP
GO:0032728
positive regulation of interferon-beta production
2/50
49/22777
0.041
18.593
5.783
0.005
0.362
0.332
ENSMUSG00000042699/ENSMUSG00000027995
2
BP
GO:0022618
protein-RNA complex assembly
3/50
168/22777
0.018
8.135
4.354
0.006
0.362
0.332
ENSMUSG00000042699/ENSMUSG00000074129/ENSMUSG00000032518
3
BP
GO:0071826
protein-RNA complex organization
3/50
176/22777
0.017
7.765
4.226
0.007
0.362
0.332
ENSMUSG00000042699/ENSMUSG00000074129/ENSMUSG00000032518
3
BP
GO:0060760
positive regulation of response to cytokine stimulus
2/50
66/22777
0.030
13.804
4.886
0.009
0.362
0.332
ENSMUSG00000042699/ENSMUSG00000027995
2
BP
GO:0032608
interferon-beta production
2/50
68/22777
0.029
13.398
4.803
0.010
0.362
0.332
ENSMUSG00000042699/ENSMUSG00000027995
2
BP
GO:0032648
regulation of interferon-beta production
2/50
68/22777
0.029
13.398
4.803
0.010
0.362
0.332
ENSMUSG00000042699/ENSMUSG00000027995
2
BP
GO:0032481
positive regulation of type I interferon production
2/50
74/22777
0.027
12.312
4.572
0.012
0.362
0.332
ENSMUSG00000042699/ENSMUSG00000027995
2
BP
GO:0022613
ribonucleoprotein complex biogenesis
4/50
417/22777
0.010
4.370
3.257
0.013
0.362
0.332
ENSMUSG00000042699/ENSMUSG00000027405/ENSMUSG00000074129/ENSMUSG00000032518
4
BP
GO:0001731
formation of translation preinitiation complex
1/50
10/22777
0.100
45.554
6.610
0.022
0.362
0.332
ENSMUSG00000074129
1
BP
GO:0010501
RNA secondary structure unwinding
1/50
10/22777
0.100
45.554
6.610
0.022
0.362
0.332
ENSMUSG00000042699
1
BP
GO:0070391
response to lipoteichoic acid
1/50
10/22777
0.100
45.554
6.610
0.022
0.362
0.332
ENSMUSG00000027995
1
BP
GO:0070934
CRD-mediated mRNA stabilization
1/50
10/22777
0.100
45.554
6.610
0.022
0.362
0.332
ENSMUSG00000042699
1
BP
GO:0071223
cellular response to lipoteichoic acid
1/50
10/22777
0.100
45.554
6.610
0.022
0.362
0.332
ENSMUSG00000027995
1
BP
GO:1904851
positive regulation of establishment of protein localization to telomere
1/50
10/22777
0.100
45.554
6.610
0.022
0.362
0.332
ENSMUSG00000068039
1
BP
GO:0032490
detection of molecule of bacterial origin
1/50
11/22777
0.091
41.413
6.288
0.024
0.362
0.332
ENSMUSG00000027995
1
BP
GO:0070203
regulation of establishment of protein localization to telomere
1/50
11/22777
0.091
41.413
6.288
0.024
0.362
0.332
ENSMUSG00000068039
1
BP
GO:1900152
negative regulation of nuclear-transcribed mRNA catabolic process, deadenylation-dependent decay
1/50
11/22777
0.091
41.413
6.288
0.024
0.362
0.332
ENSMUSG00000042699
1
BP
GO:2000109
regulation of macrophage apoptotic process
1/50
11/22777
0.091
41.413
6.288
0.024
0.362
0.332
ENSMUSG00000068039
1
BP
GO:0032755
positive regulation of interleukin-6 production
2/50
109/22777
0.018
8.359
3.612
0.024
0.362
0.332
ENSMUSG00000042699/ENSMUSG00000027995
2
BP
GO:0032479
regulation of type I interferon production
2/50
111/22777
0.018
8.208
3.571
0.025
0.362
0.332
ENSMUSG00000042699/ENSMUSG00000027995
2
BP
GO:0032760
positive regulation of tumor necrosis factor production
2/50
113/22777
0.018
8.063
3.530
0.026
0.362
0.332
ENSMUSG00000042699/ENSMUSG00000027995
2
BP
GO:0044417
translocation of molecules into host
1/50
12/22777
0.083
37.962
6.007
0.026
0.362
0.332
ENSMUSG00000068039
1
BP
GO:0070202
regulation of establishment of protein localization to chromosome
1/50
12/22777
0.083
37.962
6.007
0.026
0.362
0.332
ENSMUSG00000068039
1
BP
GO:0032606
type I interferon production
2/50
115/22777
0.017
7.922
3.491
0.026
0.362
0.332
ENSMUSG00000042699/ENSMUSG00000027995
2
BP
GO:1903557
positive regulation of tumor necrosis factor superfamily cytokine production
2/50
115/22777
0.017
7.922
3.491
0.026
0.362
0.332
ENSMUSG00000042699/ENSMUSG00000027995
2
BP
GO:0071346
cellular response to type II interferon
2/50
117/22777
0.017
7.787
3.452
0.027
0.362
0.332
ENSMUSG00000027995/ENSMUSG00000074129
2
BP
GO:0034982
mitochondrial protein processing
1/50
13/22777
0.077
35.042
5.758
0.028
0.362
0.332
ENSMUSG00000026775
1
BP
GO:0036005
response to macrophage colony-stimulating factor
1/50
13/22777
0.077
35.042
5.758
0.028
0.362
0.332
ENSMUSG00000027995
1
BP
GO:0036006
cellular response to macrophage colony-stimulating factor stimulus
1/50
13/22777
0.077
35.042
5.758
0.028
0.362
0.332
ENSMUSG00000027995
1
BP
GO:0046831
regulation of RNA export from nucleus
1/50
13/22777
0.077
35.042
5.758
0.028
0.362
0.332
ENSMUSG00000042699
1
BP
GO:0071888
macrophage apoptotic process
1/50
13/22777
0.077
35.042
5.758
0.028
0.362
0.332
ENSMUSG00000068039
1
BP
GO:1904816
positive regulation of protein localization to chromosome, telomeric region
1/50
13/22777
0.077
35.042
5.758
0.028
0.362
0.332
ENSMUSG00000068039
1
BP
GO:0018342
protein prenylation
1/50
14/22777
0.071
32.539
5.537
0.030
0.362
0.332
ENSMUSG00000038975
1
BP
GO:0032494
response to peptidoglycan
1/50
14/22777
0.071
32.539
5.537
0.030
0.362
0.332
ENSMUSG00000027995
1
BP
GO:0097354
prenylation
1/50
14/22777
0.071
32.539
5.537
0.030
0.362
0.332
ENSMUSG00000038975
1
BP
GO:0098792
xenophagy
1/50
14/22777
0.071
32.539
5.537
0.030
0.362
0.332
ENSMUSG00000027995
1
BP
GO:2000767
positive regulation of cytoplasmic translation
1/50
14/22777
0.071
32.539
5.537
0.030
0.362
0.332
ENSMUSG00000042699
1
BP
GO:0014004
microglia differentiation
1/50
15/22777
0.067
30.369
5.337
0.032
0.362
0.332
ENSMUSG00000027995
1
BP
GO:0071360
cellular response to exogenous dsRNA
1/50
15/22777
0.067
30.369
5.337
0.032
0.362
0.332
ENSMUSG00000042699
1
BP
GO:1904814
regulation of protein localization to chromosome, telomeric region
1/50
15/22777
0.067
30.369
5.337
0.032
0.362
0.332
ENSMUSG00000068039
1
BP
GO:1905809
negative regulation of synapse organization
1/50
15/22777
0.067
30.369
5.337
0.032
0.362
0.332
ENSMUSG00000027995
1
BP
GO:0032543
mitochondrial translation
2/50
132/22777
0.015
6.902
3.190
0.034
0.362
0.332
ENSMUSG00000063884/ENSMUSG00000035202
2
BP
GO:0032239
regulation of nucleobase-containing compound transport
1/50
16/22777
0.062
28.471
5.156
0.035
0.362
0.332
ENSMUSG00000042699
1
BP
GO:0051054
positive regulation of DNA metabolic process
3/50
327/22777
0.009
4.179
2.716
0.035
0.362
0.332
ENSMUSG00000042699/ENSMUSG00000032481/ENSMUSG00000068039
3
BP
GO:0045739
positive regulation of DNA repair
2/50
134/22777
0.015
6.799
3.158
0.035
0.362
0.332
ENSMUSG00000042699/ENSMUSG00000032481
2
BP
GO:0002730
regulation of dendritic cell cytokine production
1/50
17/22777
0.059
26.796
4.991
0.037
0.362
0.332
ENSMUSG00000027995
1
BP
GO:0006337
nucleosome disassembly
1/50
17/22777
0.059
26.796
4.991
0.037
0.362
0.332
ENSMUSG00000032481
1
BP
GO:0016045
detection of bacterium
1/50
17/22777
0.059
26.796
4.991
0.037
0.362
0.332
ENSMUSG00000027995
1
BP
GO:0034134
toll-like receptor 2 signaling pathway
1/50
17/22777
0.059
26.796
4.991
0.037
0.362
0.332
ENSMUSG00000027995
1
BP
GO:0045947
negative regulation of translational initiation
1/50
17/22777
0.059
26.796
4.991
0.037
0.362
0.332
ENSMUSG00000074129
1
BP
GO:2000637
positive regulation of miRNA-mediated gene silencing
1/50
17/22777
0.059
26.796
4.991
0.037
0.362
0.332
ENSMUSG00000042699
1
BP
GO:0002371
dendritic cell cytokine production
1/50
18/22777
0.056
25.308
4.839
0.039
0.362
0.332
ENSMUSG00000027995
1
BP
GO:0019081
viral translation
1/50
18/22777
0.056
25.308
4.839
0.039
0.362
0.332
ENSMUSG00000042699
1
BP
GO:0060148
positive regulation of post-transcriptional gene silencing
1/50
18/22777
0.056
25.308
4.839
0.039
0.362
0.332
ENSMUSG00000042699
1
BP
GO:1900370
positive regulation of post-transcriptional gene silencing by RNA
1/50
18/22777
0.056
25.308
4.839
0.039
0.362
0.332
ENSMUSG00000042699
1
BP
GO:0034341
response to type II interferon
2/50
145/22777
0.014
6.283
2.994
0.040
0.362
0.332
ENSMUSG00000027995/ENSMUSG00000074129
2
BP
GO:0032695
negative regulation of interleukin-12 production
1/50
19/22777
0.053
23.976
4.699
0.041
0.362
0.332
ENSMUSG00000027995
1
BP
GO:0032700
negative regulation of interleukin-17 production
1/50
19/22777
0.053
23.976
4.699
0.041
0.362
0.332
ENSMUSG00000027995
1
BP
GO:0070200
establishment of protein localization to telomere
1/50
19/22777
0.053
23.976
4.699
0.041
0.362
0.332
ENSMUSG00000068039
1
BP
GO:0050729
positive regulation of inflammatory response
2/50
148/22777
0.014
6.156
2.952
0.042
0.362
0.332
ENSMUSG00000042699/ENSMUSG00000027995
2
BP
GO:0000028
ribosomal small subunit assembly
1/50
20/22777
0.050
22.777
4.570
0.043
0.362
0.332
ENSMUSG00000032518
1
BP
GO:0002755
MyD88-dependent toll-like receptor signaling pathway
1/50
20/22777
0.050
22.777
4.570
0.043
0.362
0.332
ENSMUSG00000027995
1
BP
GO:0032986
protein-DNA complex disassembly
1/50
20/22777
0.050
22.777
4.570
0.043
0.362
0.332
ENSMUSG00000032481
1
BP
GO:0098543
detection of other organism
1/50
20/22777
0.050
22.777
4.570
0.043
0.362
0.332
ENSMUSG00000027995
1
BP
GO:0031333
negative regulation of protein-containing complex assembly
2/50
154/22777
0.013
5.916
2.871
0.045
0.362
0.332
ENSMUSG00000027995/ENSMUSG00000074129
2
BP
GO:0060759
regulation of response to cytokine stimulus
2/50
154/22777
0.013
5.916
2.871
0.045
0.362
0.332
ENSMUSG00000042699/ENSMUSG00000027995
2
BP
GO:0071359
cellular response to dsRNA
1/50
21/22777
0.048
21.692
4.450
0.045
0.362
0.332
ENSMUSG00000042699
1
BP
GO:0050830
defense response to Gram-positive bacterium
2/50
157/22777
0.013
5.803
2.833
0.047
0.362
0.332
ENSMUSG00000027995/ENSMUSG00000062727
2
BP
GO:0051092
positive regulation of NF-kappaB transcription factor activity
2/50
158/22777
0.013
5.766
2.820
0.047
0.362
0.332
ENSMUSG00000042699/ENSMUSG00000027995
2
BP
GO:0007252
I-kappaB phosphorylation
1/50
22/22777
0.045
20.706
4.337
0.047
0.362
0.332
ENSMUSG00000027995
1
BP
GO:0046782
regulation of viral transcription
1/50
22/22777
0.045
20.706
4.337
0.047
0.362
0.332
ENSMUSG00000042699
1
BP
GO:0051770
positive regulation of nitric-oxide synthase biosynthetic process
1/50
22/22777
0.045
20.706
4.337
0.047
0.362
0.332
ENSMUSG00000027995
1
BP
GO:0140053
mitochondrial gene expression
2/50
167/22777
0.012
5.456
2.711
0.052
0.362
0.332
ENSMUSG00000063884/ENSMUSG00000035202
2
BP
GO:0006353
DNA-templated transcription termination
1/50
25/22777
0.040
18.222
4.041
0.053
0.362
0.332
ENSMUSG00000042699
1
BP
GO:0032288
myelin assembly
1/50
25/22777
0.040
18.222
4.041
0.053
0.362
0.332
ENSMUSG00000027995
1
BP
GO:0032675
regulation of interleukin-6 production
2/50
170/22777
0.012
5.359
2.676
0.054
0.362
0.332
ENSMUSG00000042699/ENSMUSG00000027995
2
BP
GO:0006403
RNA localization
2/50
171/22777
0.012
5.328
2.665
0.054
0.362
0.332
ENSMUSG00000042699/ENSMUSG00000068039
2
BP
GO:0098581
detection of external biotic stimulus
1/50
26/22777
0.038
17.521
3.953
0.056
0.362
0.332
ENSMUSG00000027995
1
BP
GO:1900151
regulation of nuclear-transcribed mRNA catabolic process, deadenylation-dependent decay
1/50
26/22777
0.038
17.521
3.953
0.056
0.362
0.332
ENSMUSG00000042699
1
BP
GO:0002183
cytoplasmic translational initiation
1/50
27/22777
0.037
16.872
3.871
0.058
0.362
0.332
ENSMUSG00000074129
1
BP
GO:0032727
positive regulation of interferon-alpha production
1/50
27/22777
0.037
16.872
3.871
0.058
0.362
0.332
ENSMUSG00000042699
1
BP
GO:0050765
negative regulation of phagocytosis
1/50
27/22777
0.037
16.872
3.871
0.058
0.362
0.332
ENSMUSG00000027995
1
BP
GO:0051443
positive regulation of ubiquitin-protein transferase activity
1/50
27/22777
0.037
16.872
3.871
0.058
0.362
0.332
ENSMUSG00000044533
1
BP
GO:0032635
interleukin-6 production
2/50
179/22777
0.011
5.090
2.577
0.059
0.362
0.332
ENSMUSG00000042699/ENSMUSG00000027995
2
BP
GO:0006515
protein quality control for misfolded or incompletely synthesized proteins
1/50
28/22777
0.036
16.269
3.792
0.060
0.362
0.332
ENSMUSG00000026775
1
BP
GO:0006925
inflammatory cell apoptotic process
1/50
28/22777
0.036
16.269
3.792
0.060
0.362
0.332
ENSMUSG00000068039
1
BP
GO:0006417
regulation of translation
3/50
408/22777
0.007
3.350
2.246
0.060
0.362
0.332
ENSMUSG00000042699/ENSMUSG00000063884/ENSMUSG00000074129
3
BP
GO:0006120
mitochondrial electron transport, NADH to ubiquinone
1/50
29/22777
0.034
15.708
3.717
0.062
0.362
0.332
ENSMUSG00000064363
1
BP
GO:0051767
nitric-oxide synthase biosynthetic process
1/50
29/22777
0.034
15.708
3.717
0.062
0.362
0.332
ENSMUSG00000027995
1
BP
GO:0051769
regulation of nitric-oxide synthase biosynthetic process
1/50
29/22777
0.034
15.708
3.717
0.062
0.362
0.332
ENSMUSG00000027995
1
BP
GO:2000819
regulation of nucleotide-excision repair
1/50
29/22777
0.034
15.708
3.717
0.062
0.362
0.332
ENSMUSG00000032481
1
BP
GO:0032680
regulation of tumor necrosis factor production
2/50
185/22777
0.011
4.925
2.514
0.062
0.362
0.332
ENSMUSG00000042699/ENSMUSG00000027995
2
BP
GO:0022010
central nervous system myelination
1/50
30/22777
0.033
15.185
3.646
0.064
0.362
0.332
ENSMUSG00000027995
1
BP
GO:0032291
axon ensheathment in central nervous system
1/50
30/22777
0.033
15.185
3.646
0.064
0.362
0.332
ENSMUSG00000027995
1
BP
GO:0060907
positive regulation of macrophage cytokine production
1/50
30/22777
0.033
15.185
3.646
0.064
0.362
0.332
ENSMUSG00000027995
1
BP
GO:0070199
establishment of protein localization to chromosome
1/50
30/22777
0.033
15.185
3.646
0.064
0.362
0.332
ENSMUSG00000068039
1
ONTOLOGY
ID
Description
GeneRatio
BgRatio
RichFactor
FoldEnrichment
zScore
pvalue
p.adjust
qvalue
geneID
Count
BP
GO:0000018
regulation of DNA recombination
3/50
137/22777
0.022
9.975
4.942
0.003
0.359
0.340
ENSMUSG00000029505/ENSMUSG00000029580/ENSMUSG00000058773
3
BP
GO:1905168
positive regulation of double-strand break repair via homologous recombination
2/50
40/22777
0.050
22.777
6.466
0.003
0.359
0.340
ENSMUSG00000029505/ENSMUSG00000029580
2
BP
GO:0002181
cytoplasmic translation
3/50
142/22777
0.021
9.624
4.835
0.004
0.359
0.340
ENSMUSG00000074129/ENSMUSG00000061983/ENSMUSG00000044533
3
BP
GO:0140236
translation at presynapse
2/50
47/22777
0.043
19.385
5.918
0.005
0.359
0.340
ENSMUSG00000074129/ENSMUSG00000061983
2
BP
GO:0140241
translation at synapse
2/50
48/22777
0.042
18.981
5.849
0.005
0.359
0.340
ENSMUSG00000074129/ENSMUSG00000061983
2
BP
GO:0140242
translation at postsynapse
2/50
48/22777
0.042
18.981
5.849
0.005
0.359
0.340
ENSMUSG00000074129/ENSMUSG00000061983
2
BP
GO:0006310
DNA recombination
4/50
331/22777
0.012
5.505
3.873
0.006
0.367
0.348
ENSMUSG00000029505/ENSMUSG00000029580/ENSMUSG00000058773/ENSMUSG00000071470
4
BP
GO:0006334
nucleosome assembly
2/50
69/22777
0.029
13.204
4.762
0.010
0.413
0.391
ENSMUSG00000058773/ENSMUSG00000099583
2
BP
GO:0010569
regulation of double-strand break repair via homologous recombination
2/50
72/22777
0.028
12.654
4.645
0.011
0.413
0.391
ENSMUSG00000029505/ENSMUSG00000029580
2
BP
GO:0045911
positive regulation of DNA recombination
2/50
76/22777
0.026
11.988
4.500
0.012
0.413
0.391
ENSMUSG00000029505/ENSMUSG00000029580
2
BP
GO:2000781
positive regulation of double-strand break repair
2/50
87/22777
0.023
10.472
4.152
0.016
0.413
0.391
ENSMUSG00000029505/ENSMUSG00000029580
2
BP
GO:0034728
nucleosome organization
2/50
88/22777
0.023
10.353
4.123
0.016
0.413
0.391
ENSMUSG00000058773/ENSMUSG00000099583
2
BP
GO:0001731
formation of translation preinitiation complex
1/50
10/22777
0.100
45.554
6.610
0.022
0.413
0.391
ENSMUSG00000074129
1
BP
GO:0046543
development of secondary female sexual characteristics
1/50
10/22777
0.100
45.554
6.610
0.022
0.413
0.391
ENSMUSG00000004264
1
BP
GO:0071169
establishment of protein localization to chromatin
1/50
10/22777
0.100
45.554
6.610
0.022
0.413
0.391
ENSMUSG00000058773
1
BP
GO:0071257
cellular response to electrical stimulus
1/50
10/22777
0.100
45.554
6.610
0.022
0.413
0.391
ENSMUSG00000029580
1
BP
GO:1904959
regulation of cytochrome-c oxidase activity
1/50
10/22777
0.100
45.554
6.610
0.022
0.413
0.391
ENSMUSG00000004264
1
BP
GO:1904732
regulation of electron transfer activity
1/50
11/22777
0.091
41.413
6.288
0.024
0.413
0.391
ENSMUSG00000004264
1
BP
GO:0034333
adherens junction assembly
1/50
12/22777
0.083
37.962
6.007
0.026
0.413
0.391
ENSMUSG00000029580
1
BP
GO:0009086
methionine biosynthetic process
1/50
13/22777
0.077
35.042
5.758
0.028
0.413
0.391
ENSMUSG00000010911
1
BP
GO:0045136
development of secondary sexual characteristics
1/50
13/22777
0.077
35.042
5.758
0.028
0.413
0.391
ENSMUSG00000004264
1
BP
GO:0045176
apical protein localization
1/50
14/22777
0.071
32.539
5.537
0.030
0.413
0.391
ENSMUSG00000029580
1
BP
GO:0006555
methionine metabolic process
1/50
15/22777
0.067
30.369
5.337
0.032
0.413
0.391
ENSMUSG00000010911
1
BP
GO:0033147
negative regulation of intracellular estrogen receptor signaling pathway
1/50
15/22777
0.067
30.369
5.337
0.032
0.413
0.391
ENSMUSG00000004264
1
BP
GO:2000779
regulation of double-strand break repair
2/50
132/22777
0.015
6.902
3.190
0.034
0.413
0.391
ENSMUSG00000029505/ENSMUSG00000029580
2
BP
GO:0000097
sulfur amino acid biosynthetic process
1/50
16/22777
0.062
28.471
5.156
0.035
0.413
0.391
ENSMUSG00000010911
1
BP
GO:0023035
CD40 signaling pathway
1/50
16/22777
0.062
28.471
5.156
0.035
0.413
0.391
ENSMUSG00000004264
1
BP
GO:0032048
cardiolipin metabolic process
1/50
16/22777
0.062
28.471
5.156
0.035
0.413
0.391
ENSMUSG00000004264
1
BP
GO:0045739
positive regulation of DNA repair
2/50
134/22777
0.015
6.799
3.158
0.035
0.413
0.391
ENSMUSG00000029505/ENSMUSG00000029580
2
BP
GO:0007096
regulation of exit from mitosis
1/50
17/22777
0.059
26.796
4.991
0.037
0.413
0.391
ENSMUSG00000004264
1
BP
GO:0045947
negative regulation of translational initiation
1/50
17/22777
0.059
26.796
4.991
0.037
0.413
0.391
ENSMUSG00000074129
1
BP
GO:1902018
negative regulation of cilium assembly
1/50
17/22777
0.059
26.796
4.991
0.037
0.413
0.391
ENSMUSG00000002486
1
BP
GO:0000963
mitochondrial RNA processing
1/50
18/22777
0.056
25.308
4.839
0.039
0.413
0.391
ENSMUSG00000000384
1
BP
GO:0090493
catecholamine uptake
1/50
18/22777
0.056
25.308
4.839
0.039
0.413
0.391
ENSMUSG00000029580
1
BP
GO:0033599
regulation of mammary gland epithelial cell proliferation
1/50
20/22777
0.050
22.777
4.570
0.043
0.413
0.391
ENSMUSG00000004264
1
BP
GO:0006338
chromatin remodeling
3/50
356/22777
0.008
3.839
2.532
0.043
0.413
0.391
ENSMUSG00000029580/ENSMUSG00000058773/ENSMUSG00000099583
3
BP
GO:0018205
peptidyl-lysine modification
3/50
361/22777
0.008
3.786
2.502
0.045
0.413
0.391
ENSMUSG00000029505/ENSMUSG00000029580/ENSMUSG00000058773
3
BP
GO:0009067
aspartate family amino acid biosynthetic process
1/50
21/22777
0.048
21.692
4.450
0.045
0.413
0.391
ENSMUSG00000010911
1
BP
GO:0060749
mammary gland alveolus development
1/50
22/22777
0.045
20.706
4.337
0.047
0.413
0.391
ENSMUSG00000004264
1
BP
GO:0061377
mammary gland lobule development
1/50
22/22777
0.045
20.706
4.337
0.047
0.413
0.391
ENSMUSG00000004264
1
BP
GO:0098974
postsynaptic actin cytoskeleton organization
1/50
23/22777
0.043
19.806
4.232
0.049
0.413
0.391
ENSMUSG00000029580
1
BP
GO:0099188
postsynaptic cytoskeleton organization
1/50
23/22777
0.043
19.806
4.232
0.049
0.413
0.391
ENSMUSG00000029580
1
BP
GO:0000724
double-strand break repair via homologous recombination
2/50
163/22777
0.012
5.589
2.758
0.050
0.413
0.391
ENSMUSG00000029505/ENSMUSG00000029580
2
BP
GO:0051602
response to electrical stimulus
1/50
24/22777
0.042
18.981
4.134
0.051
0.413
0.391
ENSMUSG00000029580
1
BP
GO:0150105
protein localization to cell-cell junction
1/50
24/22777
0.042
18.981
4.134
0.051
0.413
0.391
ENSMUSG00000029580
1
BP
GO:0000725
recombinational repair
2/50
167/22777
0.012
5.456
2.711
0.052
0.413
0.391
ENSMUSG00000029505/ENSMUSG00000029580
2
BP
GO:0140053
mitochondrial gene expression
2/50
167/22777
0.012
5.456
2.711
0.052
0.413
0.391
ENSMUSG00000035202/ENSMUSG00000000384
2
BP
GO:0006475
internal protein amino acid acetylation
2/50
169/22777
0.012
5.391
2.687
0.053
0.413
0.391
ENSMUSG00000029505/ENSMUSG00000029580
2
BP
GO:0018393
internal peptidyl-lysine acetylation
2/50
169/22777
0.012
5.391
2.687
0.053
0.413
0.391
ENSMUSG00000029505/ENSMUSG00000029580
2
BP
GO:0039529
RIG-I signaling pathway
1/50
26/22777
0.038
17.521
3.953
0.056
0.413
0.391
ENSMUSG00000004264
1
BP
GO:0002183
cytoplasmic translational initiation
1/50
27/22777
0.037
16.872
3.871
0.058
0.413
0.391
ENSMUSG00000074129
1
BP
GO:0051443
positive regulation of ubiquitin-protein transferase activity
1/50
27/22777
0.037
16.872
3.871
0.058
0.413
0.391
ENSMUSG00000044533
1
BP
GO:2000765
regulation of cytoplasmic translation
1/50
27/22777
0.037
16.872
3.871
0.058
0.413
0.391
ENSMUSG00000074129
1
BP
GO:0065004
protein-DNA complex assembly
2/50
180/22777
0.011
5.062
2.566
0.059
0.413
0.391
ENSMUSG00000058773/ENSMUSG00000099583
2
BP
GO:0046471
phosphatidylglycerol metabolic process
1/50
28/22777
0.036
16.269
3.792
0.060
0.413
0.391
ENSMUSG00000004264
1
BP
GO:1900242
regulation of synaptic vesicle endocytosis
1/50
28/22777
0.036
16.269
3.792
0.060
0.413
0.391
ENSMUSG00000029580
1
BP
GO:1904030
negative regulation of cyclin-dependent protein kinase activity
1/50
28/22777
0.036
16.269
3.792
0.060
0.413
0.391
ENSMUSG00000029580
1
BP
GO:0018394
peptidyl-lysine acetylation
2/50
182/22777
0.011
5.006
2.545
0.061
0.413
0.391
ENSMUSG00000029505/ENSMUSG00000029580
2
BP
GO:0060444
branching involved in mammary gland duct morphogenesis
1/50
29/22777
0.034
15.708
3.717
0.062
0.413
0.391
ENSMUSG00000004264
1
BP
GO:2000819
regulation of nucleotide-excision repair
1/50
29/22777
0.034
15.708
3.717
0.062
0.413
0.391
ENSMUSG00000029580
1
BP
GO:0015874
norepinephrine transport
1/50
30/22777
0.033
15.185
3.646
0.064
0.413
0.391
ENSMUSG00000029580
1
BP
GO:0070199
establishment of protein localization to chromosome
1/50
30/22777
0.033
15.185
3.646
0.064
0.413
0.391
ENSMUSG00000058773
1
BP
GO:0071353
cellular response to interleukin-4
1/50
30/22777
0.033
15.185
3.646
0.064
0.413
0.391
ENSMUSG00000044533
1
BP
GO:0140374
antiviral innate immune response
1/50
30/22777
0.033
15.185
3.646
0.064
0.413
0.391
ENSMUSG00000004264
1
BP
GO:0010458
exit from mitosis
1/50
31/22777
0.032
14.695
3.579
0.066
0.413
0.391
ENSMUSG00000004264
1
BP
GO:1902806
regulation of cell cycle G1/S phase transition
2/50
193/22777
0.010
4.721
2.435
0.067
0.413
0.391
ENSMUSG00000029580/ENSMUSG00000004264
2
BP
GO:0070670
response to interleukin-4
1/50
32/22777
0.031
14.236
3.514
0.068
0.413
0.391
ENSMUSG00000044533
1
BP
GO:0050821
protein stabilization
2/50
196/22777
0.010
4.648
2.406
0.069
0.413
0.391
ENSMUSG00000004264/ENSMUSG00000058773
2
BP
GO:0000096
sulfur amino acid metabolic process
1/50
33/22777
0.030
13.804
3.452
0.070
0.413
0.391
ENSMUSG00000010911
1
BP
GO:0010155
regulation of proton transport
1/50
33/22777
0.030
13.804
3.452
0.070
0.413
0.391
ENSMUSG00000004264
1
BP
GO:0033598
mammary gland epithelial cell proliferation
1/50
33/22777
0.030
13.804
3.452
0.070
0.413
0.391
ENSMUSG00000004264
1
BP
GO:0070633
transepithelial transport
1/50
33/22777
0.030
13.804
3.452
0.070
0.413
0.391
ENSMUSG00000029580
1
BP
GO:1901798
positive regulation of signal transduction by p53 class mediator
1/50
33/22777
0.030
13.804
3.452
0.070
0.413
0.391
ENSMUSG00000072692
1
BP
GO:0071824
protein-DNA complex organization
2/50
203/22777
0.010
4.488
2.341
0.073
0.413
0.391
ENSMUSG00000058773/ENSMUSG00000099583
2
BP
GO:0043094
cellular metabolic compound salvage
1/50
35/22777
0.029
13.015
3.337
0.074
0.413
0.391
ENSMUSG00000010911
1
BP
GO:0070316
regulation of G0 to G1 transition
1/50
36/22777
0.028
12.654
3.282
0.076
0.413
0.391
ENSMUSG00000029580
1
BP
GO:0120033
negative regulation of plasma membrane bounded cell projection assembly
1/50
36/22777
0.028
12.654
3.282
0.076
0.413
0.391
ENSMUSG00000002486
1
BP
GO:0033146
regulation of intracellular estrogen receptor signaling pathway
1/50
37/22777
0.027
12.312
3.230
0.078
0.413
0.391
ENSMUSG00000004264
1
BP
GO:0045023
G0 to G1 transition
1/50
37/22777
0.027
12.312
3.230
0.078
0.413
0.391
ENSMUSG00000029580
1
BP
GO:1903421
regulation of synaptic vesicle recycling
1/50
37/22777
0.027
12.312
3.230
0.078
0.413
0.391
ENSMUSG00000029580
1
BP
GO:0006473
protein acetylation
2/50
213/22777
0.009
4.277
2.254
0.080
0.413
0.391
ENSMUSG00000029505/ENSMUSG00000029580
2
BP
GO:0000423
mitophagy
1/50
38/22777
0.026
11.988
3.180
0.080
0.413
0.391
ENSMUSG00000004264
1
BP
GO:0006282
regulation of DNA repair
2/50
214/22777
0.009
4.257
2.246
0.080
0.413
0.391
ENSMUSG00000029505/ENSMUSG00000029580
2
BP
GO:0031396
regulation of protein ubiquitination
2/50
215/22777
0.009
4.238
2.237
0.081
0.413
0.391
ENSMUSG00000072692/ENSMUSG00000044533
2
BP
GO:0033144
negative regulation of intracellular steroid hormone receptor signaling pathway
1/50
40/22777
0.025
11.389
3.084
0.084
0.413
0.391
ENSMUSG00000004264
1
BP
GO:0070269
pyroptotic inflammatory response
1/50
40/22777
0.025
11.389
3.084
0.084
0.413
0.391
ENSMUSG00000010911
1
BP
GO:1903725
regulation of phospholipid metabolic process
1/50
40/22777
0.025
11.389
3.084
0.084
0.413
0.391
ENSMUSG00000004264
1
BP
GO:0006418
tRNA aminoacylation for protein translation
1/50
41/22777
0.024
11.111
3.039
0.086
0.413
0.391
ENSMUSG00000035202
1
BP
GO:0009066
aspartate family amino acid metabolic process
1/50
41/22777
0.024
11.111
3.039
0.086
0.413
0.391
ENSMUSG00000010911
1
BP
GO:0060603
mammary gland duct morphogenesis
1/50
41/22777
0.024
11.111
3.039
0.086
0.413
0.391
ENSMUSG00000004264
1
BP
GO:0030261
chromosome condensation
1/50
42/22777
0.024
10.846
2.996
0.088
0.418
0.396
ENSMUSG00000058773
1
BP
GO:1902116
negative regulation of organelle assembly
1/50
43/22777
0.023
10.594
2.954
0.090
0.423
0.401
ENSMUSG00000002486
1
BP
GO:0043039
tRNA aminoacylation
1/50
44/22777
0.023
10.353
2.913
0.092
0.423
0.401
ENSMUSG00000035202
1
BP
GO:0071168
protein localization to chromatin
1/50
44/22777
0.023
10.353
2.913
0.092
0.423
0.401
ENSMUSG00000058773
1
BP
GO:0043038
amino acid activation
1/50
45/22777
0.022
10.123
2.873
0.094
0.428
0.405
ENSMUSG00000035202
1
BP
GO:0045910
negative regulation of DNA recombination
1/50
47/22777
0.021
9.692
2.798
0.098
0.436
0.414
ENSMUSG00000058773
1
BP
GO:0048246
macrophage chemotaxis
1/50
47/22777
0.021
9.692
2.798
0.098
0.436
0.414
ENSMUSG00000074129
1
BP
GO:0045663
positive regulation of myoblast differentiation
1/50
49/22777
0.020
9.297
2.727
0.102
0.440
0.417
ENSMUSG00000029580
1
BP
GO:1902459
positive regulation of stem cell population maintenance
1/50
49/22777
0.020
9.297
2.727
0.102
0.440
0.417
ENSMUSG00000029580
1
BP
GO:1903320
regulation of protein modification by small protein conjugation or removal
2/50
250/22777
0.008
3.644
1.972
0.104
0.440
0.417
ENSMUSG00000072692/ENSMUSG00000044533
2
ONTOLOGY
ID
Description
GeneRatio
BgRatio
RichFactor
FoldEnrichment
zScore
pvalue
p.adjust
qvalue
geneID
Count
BP
GO:0002181
cytoplasmic translation
7/48
142/22777
0.049
23.392
12.300
0.000
0.000
0.000
ENSMUSG00000042699/ENSMUSG00000059796/ENSMUSG00000022884/ENSMUSG00000044533/ENSMUSG00000041453/ENSMUSG00000074129/ENSMUSG00000032518
7
BP
GO:0002183
cytoplasmic translational initiation
3/48
27/22777
0.111
52.725
12.358
0.000
0.005
0.005
ENSMUSG00000059796/ENSMUSG00000022884/ENSMUSG00000074129
3
BP
GO:2000765
regulation of cytoplasmic translation
2/48
27/22777
0.074
35.150
8.159
0.001
0.188
0.175
ENSMUSG00000042699/ENSMUSG00000074129
2
BP
GO:0006413
translational initiation
3/48
115/22777
0.026
12.379
5.622
0.002
0.188
0.175
ENSMUSG00000059796/ENSMUSG00000022884/ENSMUSG00000074129
3
BP
GO:0070269
pyroptotic inflammatory response
2/48
40/22777
0.050
23.726
6.611
0.003
0.264
0.245
ENSMUSG00000042699/ENSMUSG00000010911
2
BP
GO:0022618
protein-RNA complex assembly
3/48
168/22777
0.018
8.474
4.468
0.005
0.355
0.330
ENSMUSG00000042699/ENSMUSG00000074129/ENSMUSG00000032518
3
BP
GO:0071826
protein-RNA complex organization
3/48
176/22777
0.017
8.088
4.338
0.006
0.355
0.330
ENSMUSG00000042699/ENSMUSG00000074129/ENSMUSG00000032518
3
BP
GO:0022613
ribonucleoprotein complex biogenesis
4/48
417/22777
0.010
4.552
3.364
0.011
0.377
0.351
ENSMUSG00000042699/ENSMUSG00000027405/ENSMUSG00000074129/ENSMUSG00000032518
4
BP
GO:0001731
formation of translation preinitiation complex
1/48
10/22777
0.100
47.452
6.752
0.021
0.377
0.351
ENSMUSG00000074129
1
BP
GO:0010501
RNA secondary structure unwinding
1/48
10/22777
0.100
47.452
6.752
0.021
0.377
0.351
ENSMUSG00000042699
1
BP
GO:0032661
regulation of interleukin-18 production
1/48
10/22777
0.100
47.452
6.752
0.021
0.377
0.351
ENSMUSG00000042699
1
BP
GO:0046543
development of secondary female sexual characteristics
1/48
10/22777
0.100
47.452
6.752
0.021
0.377
0.351
ENSMUSG00000004264
1
BP
GO:0070934
CRD-mediated mRNA stabilization
1/48
10/22777
0.100
47.452
6.752
0.021
0.377
0.351
ENSMUSG00000042699
1
BP
GO:1904959
regulation of cytochrome-c oxidase activity
1/48
10/22777
0.100
47.452
6.752
0.021
0.377
0.351
ENSMUSG00000004264
1
BP
GO:0070213
protein auto-ADP-ribosylation
1/48
11/22777
0.091
43.138
6.424
0.023
0.377
0.351
ENSMUSG00000036023
1
BP
GO:1900152
negative regulation of nuclear-transcribed mRNA catabolic process, deadenylation-dependent decay
1/48
11/22777
0.091
43.138
6.424
0.023
0.377
0.351
ENSMUSG00000042699
1
BP
GO:1904732
regulation of electron transfer activity
1/48
11/22777
0.091
43.138
6.424
0.023
0.377
0.351
ENSMUSG00000004264
1
BP
GO:0032621
interleukin-18 production
1/48
12/22777
0.083
39.543
6.137
0.025
0.377
0.351
ENSMUSG00000042699
1
BP
GO:0009086
methionine biosynthetic process
1/48
13/22777
0.077
36.502
5.884
0.027
0.377
0.351
ENSMUSG00000010911
1
BP
GO:0045136
development of secondary sexual characteristics
1/48
13/22777
0.077
36.502
5.884
0.027
0.377
0.351
ENSMUSG00000004264
1
BP
GO:0046831
regulation of RNA export from nucleus
1/48
13/22777
0.077
36.502
5.884
0.027
0.377
0.351
ENSMUSG00000042699
1
BP
GO:0018342
protein prenylation
1/48
14/22777
0.071
33.894
5.658
0.029
0.377
0.351
ENSMUSG00000038975
1
BP
GO:0097354
prenylation
1/48
14/22777
0.071
33.894
5.658
0.029
0.377
0.351
ENSMUSG00000038975
1
BP
GO:2000767
positive regulation of cytoplasmic translation
1/48
14/22777
0.071
33.894
5.658
0.029
0.377
0.351
ENSMUSG00000042699
1
BP
GO:0006555
methionine metabolic process
1/48
15/22777
0.067
31.635
5.454
0.031
0.377
0.351
ENSMUSG00000010911
1
BP
GO:0033147
negative regulation of intracellular estrogen receptor signaling pathway
1/48
15/22777
0.067
31.635
5.454
0.031
0.377
0.351
ENSMUSG00000004264
1
BP
GO:0071360
cellular response to exogenous dsRNA
1/48
15/22777
0.067
31.635
5.454
0.031
0.377
0.351
ENSMUSG00000042699
1
BP
GO:0032543
mitochondrial translation
2/48
132/22777
0.015
7.190
3.277
0.032
0.377
0.351
ENSMUSG00000063884/ENSMUSG00000035202
2
BP
GO:0000097
sulfur amino acid biosynthetic process
1/48
16/22777
0.062
29.658
5.270
0.033
0.377
0.351
ENSMUSG00000010911
1
BP
GO:0023035
CD40 signaling pathway
1/48
16/22777
0.062
29.658
5.270
0.033
0.377
0.351
ENSMUSG00000004264
1
BP
GO:0032048
cardiolipin metabolic process
1/48
16/22777
0.062
29.658
5.270
0.033
0.377
0.351
ENSMUSG00000004264
1
BP
GO:0032239
regulation of nucleobase-containing compound transport
1/48
16/22777
0.062
29.658
5.270
0.033
0.377
0.351
ENSMUSG00000042699
1
BP
GO:0007096
regulation of exit from mitosis
1/48
17/22777
0.059
27.913
5.101
0.035
0.377
0.351
ENSMUSG00000004264
1
BP
GO:0045947
negative regulation of translational initiation
1/48
17/22777
0.059
27.913
5.101
0.035
0.377
0.351
ENSMUSG00000074129
1
BP
GO:2000637
positive regulation of miRNA-mediated gene silencing
1/48
17/22777
0.059
27.913
5.101
0.035
0.377
0.351
ENSMUSG00000042699
1
BP
GO:0019081
viral translation
1/48
18/22777
0.056
26.362
4.947
0.037
0.377
0.351
ENSMUSG00000042699
1
BP
GO:0060148
positive regulation of post-transcriptional gene silencing
1/48
18/22777
0.056
26.362
4.947
0.037
0.377
0.351
ENSMUSG00000042699
1
BP
GO:0061051
positive regulation of cell growth involved in cardiac muscle cell development
1/48
18/22777
0.056
26.362
4.947
0.037
0.377
0.351
ENSMUSG00000036023
1
BP
GO:1900370
positive regulation of post-transcriptional gene silencing by RNA
1/48
18/22777
0.056
26.362
4.947
0.037
0.377
0.351
ENSMUSG00000042699
1
BP
GO:0000028
ribosomal small subunit assembly
1/48
20/22777
0.050
23.726
4.673
0.041
0.377
0.351
ENSMUSG00000032518
1
BP
GO:0033599
regulation of mammary gland epithelial cell proliferation
1/48
20/22777
0.050
23.726
4.673
0.041
0.377
0.351
ENSMUSG00000004264
1
BP
GO:0009067
aspartate family amino acid biosynthetic process
1/48
21/22777
0.048
22.596
4.550
0.043
0.377
0.351
ENSMUSG00000010911
1
BP
GO:0071359
cellular response to dsRNA
1/48
21/22777
0.048
22.596
4.550
0.043
0.377
0.351
ENSMUSG00000042699
1
BP
GO:0046782
regulation of viral transcription
1/48
22/22777
0.045
21.569
4.436
0.045
0.377
0.351
ENSMUSG00000042699
1
BP
GO:0060749
mammary gland alveolus development
1/48
22/22777
0.045
21.569
4.436
0.045
0.377
0.351
ENSMUSG00000004264
1
BP
GO:0061377
mammary gland lobule development
1/48
22/22777
0.045
21.569
4.436
0.045
0.377
0.351
ENSMUSG00000004264
1
BP
GO:0071398
cellular response to fatty acid
1/48
22/22777
0.045
21.569
4.436
0.045
0.377
0.351
ENSMUSG00000086859
1
BP
GO:0140053
mitochondrial gene expression
2/48
167/22777
0.012
5.683
2.791
0.048
0.377
0.351
ENSMUSG00000063884/ENSMUSG00000035202
2
BP
GO:0006353
DNA-templated transcription termination
1/48
25/22777
0.040
18.981
4.134
0.051
0.377
0.351
ENSMUSG00000042699
1
BP
GO:0046697
decidualization
1/48
25/22777
0.040
18.981
4.134
0.051
0.377
0.351
ENSMUSG00000036023
1
BP
GO:0039529
RIG-I signaling pathway
1/48
26/22777
0.038
18.251
4.045
0.053
0.377
0.351
ENSMUSG00000004264
1
BP
GO:1900151
regulation of nuclear-transcribed mRNA catabolic process, deadenylation-dependent decay
1/48
26/22777
0.038
18.251
4.045
0.053
0.377
0.351
ENSMUSG00000042699
1
BP
GO:0006417
regulation of translation
3/48
408/22777
0.007
3.489
2.331
0.055
0.377
0.351
ENSMUSG00000042699/ENSMUSG00000063884/ENSMUSG00000074129
3
BP
GO:0032727
positive regulation of interferon-alpha production
1/48
27/22777
0.037
17.575
3.960
0.055
0.377
0.351
ENSMUSG00000042699
1
BP
GO:0051443
positive regulation of ubiquitin-protein transferase activity
1/48
27/22777
0.037
17.575
3.960
0.055
0.377
0.351
ENSMUSG00000044533
1
BP
GO:0046471
phosphatidylglycerol metabolic process
1/48
28/22777
0.036
16.947
3.880
0.057
0.377
0.351
ENSMUSG00000004264
1
BP
GO:0060444
branching involved in mammary gland duct morphogenesis
1/48
29/22777
0.034
16.363
3.804
0.059
0.377
0.351
ENSMUSG00000004264
1
BP
GO:0071353
cellular response to interleukin-4
1/48
30/22777
0.033
15.817
3.732
0.061
0.377
0.351
ENSMUSG00000044533
1
BP
GO:0140374
antiviral innate immune response
1/48
30/22777
0.033
15.817
3.732
0.061
0.377
0.351
ENSMUSG00000004264
1
BP
GO:0010458
exit from mitosis
1/48
31/22777
0.032
15.307
3.663
0.063
0.377
0.351
ENSMUSG00000004264
1
BP
GO:0032647
regulation of interferon-alpha production
1/48
32/22777
0.031
14.829
3.597
0.065
0.377
0.351
ENSMUSG00000042699
1
BP
GO:0070670
response to interleukin-4
1/48
32/22777
0.031
14.829
3.597
0.065
0.377
0.351
ENSMUSG00000044533
1
BP
GO:0000096
sulfur amino acid metabolic process
1/48
33/22777
0.030
14.379
3.535
0.067
0.377
0.351
ENSMUSG00000010911
1
BP
GO:0010155
regulation of proton transport
1/48
33/22777
0.030
14.379
3.535
0.067
0.377
0.351
ENSMUSG00000004264
1
BP
GO:0033598
mammary gland epithelial cell proliferation
1/48
33/22777
0.030
14.379
3.535
0.067
0.377
0.351
ENSMUSG00000004264
1
BP
GO:0060964
regulation of miRNA-mediated gene silencing
1/48
34/22777
0.029
13.956
3.474
0.069
0.377
0.351
ENSMUSG00000042699
1
BP
GO:0061050
regulation of cell growth involved in cardiac muscle cell development
1/48
34/22777
0.029
13.956
3.474
0.069
0.377
0.351
ENSMUSG00000036023
1
BP
GO:0017148
negative regulation of translation
2/48
208/22777
0.010
4.563
2.372
0.071
0.377
0.351
ENSMUSG00000042699/ENSMUSG00000074129
2
BP
GO:0032607
interferon-alpha production
1/48
35/22777
0.029
13.558
3.417
0.071
0.377
0.351
ENSMUSG00000042699
1
BP
GO:0043094
cellular metabolic compound salvage
1/48
35/22777
0.029
13.558
3.417
0.071
0.377
0.351
ENSMUSG00000010911
1
BP
GO:0001893
maternal placenta development
1/48
36/22777
0.028
13.181
3.361
0.073
0.377
0.351
ENSMUSG00000036023
1
BP
GO:0070542
response to fatty acid
1/48
36/22777
0.028
13.181
3.361
0.073
0.377
0.351
ENSMUSG00000086859
1
BP
GO:1900368
regulation of post-transcriptional gene silencing by regulatory ncRNA
1/48
36/22777
0.028
13.181
3.361
0.073
0.377
0.351
ENSMUSG00000042699
1
BP
GO:0033146
regulation of intracellular estrogen receptor signaling pathway
1/48
37/22777
0.027
12.825
3.308
0.075
0.377
0.351
ENSMUSG00000004264
1
BP
GO:0060147
regulation of post-transcriptional gene silencing
1/48
37/22777
0.027
12.825
3.308
0.075
0.377
0.351
ENSMUSG00000042699
1
BP
GO:0034248
regulation of amide metabolic process
3/48
470/22777
0.006
3.029
2.042
0.076
0.377
0.351
ENSMUSG00000042699/ENSMUSG00000063884/ENSMUSG00000074129
3
BP
GO:0000423
mitophagy
1/48
38/22777
0.026
12.487
3.257
0.077
0.377
0.351
ENSMUSG00000004264
1
BP
GO:0060966
regulation of gene silencing by regulatory ncRNA
1/48
38/22777
0.026
12.487
3.257
0.077
0.377
0.351
ENSMUSG00000042699
1
BP
GO:0006284
base-excision repair
1/48
40/22777
0.025
11.863
3.160
0.081
0.377
0.351
ENSMUSG00000036023
1
BP
GO:0033144
negative regulation of intracellular steroid hormone receptor signaling pathway
1/48
40/22777
0.025
11.863
3.160
0.081
0.377
0.351
ENSMUSG00000004264
1
BP
GO:1903725
regulation of phospholipid metabolic process
1/48
40/22777
0.025
11.863
3.160
0.081
0.377
0.351
ENSMUSG00000004264
1
BP
GO:0006418
tRNA aminoacylation for protein translation
1/48
41/22777
0.024
11.574
3.114
0.083
0.377
0.351
ENSMUSG00000035202
1
BP
GO:0009066
aspartate family amino acid metabolic process
1/48
41/22777
0.024
11.574
3.114
0.083
0.377
0.351
ENSMUSG00000010911
1
BP
GO:0060603
mammary gland duct morphogenesis
1/48
41/22777
0.024
11.574
3.114
0.083
0.377
0.351
ENSMUSG00000004264
1
BP
GO:0010613
positive regulation of cardiac muscle hypertrophy
1/48
42/22777
0.024
11.298
3.070
0.085
0.377
0.351
ENSMUSG00000036023
1
BP
GO:0034249
negative regulation of amide metabolic process
2/48
231/22777
0.009
4.108
2.182
0.085
0.377
0.351
ENSMUSG00000042699/ENSMUSG00000074129
2
BP
GO:0014742
positive regulation of muscle hypertrophy
1/48
43/22777
0.023
11.035
3.027
0.087
0.377
0.351
ENSMUSG00000036023
1
BP
GO:0032508
DNA duplex unwinding
1/48
44/22777
0.023
10.785
2.985
0.089
0.377
0.351
ENSMUSG00000042699
1
BP
GO:0043039
tRNA aminoacylation
1/48
44/22777
0.023
10.785
2.985
0.089
0.377
0.351
ENSMUSG00000035202
1
BP
GO:0050691
regulation of defense response to virus by host
1/48
44/22777
0.023
10.785
2.985
0.089
0.377
0.351
ENSMUSG00000042699
1
BP
GO:0032781
positive regulation of ATP-dependent activity
1/48
45/22777
0.022
10.545
2.945
0.091
0.377
0.351
ENSMUSG00000042699
1
BP
GO:0043038
amino acid activation
1/48
45/22777
0.022
10.545
2.945
0.091
0.377
0.351
ENSMUSG00000035202
1
BP
GO:0048246
macrophage chemotaxis
1/48
47/22777
0.021
10.096
2.869
0.094
0.377
0.351
ENSMUSG00000074129
1
BP
GO:0055023
positive regulation of cardiac muscle tissue growth
1/48
47/22777
0.021
10.096
2.869
0.094
0.377
0.351
ENSMUSG00000036023
1
BP
GO:0140236
translation at presynapse
1/48
47/22777
0.021
10.096
2.869
0.094
0.377
0.351
ENSMUSG00000074129
1
BP
GO:0003298
physiological muscle hypertrophy
1/48
48/22777
0.021
9.886
2.832
0.096
0.377
0.351
ENSMUSG00000036023
1
BP
GO:0003301
physiological cardiac muscle hypertrophy
1/48
48/22777
0.021
9.886
2.832
0.096
0.377
0.351
ENSMUSG00000036023
1
BP
GO:0061049
cell growth involved in cardiac muscle cell development
1/48
48/22777
0.021
9.886
2.832
0.096
0.377
0.351
ENSMUSG00000036023
1
BP
GO:0140241
translation at synapse
1/48
48/22777
0.021
9.886
2.832
0.096
0.377
0.351
ENSMUSG00000074129
1
BP
GO:0140242
translation at postsynapse
1/48
48/22777
0.021
9.886
2.832
0.096
0.377
0.351
ENSMUSG00000074129
1
ONTOLOGY
ID
Description
GeneRatio
BgRatio
RichFactor
FoldEnrichment
zScore
pvalue
p.adjust
qvalue
geneID
Count
BP
GO:0002181
cytoplasmic translation
4/37
142/22777
0.028
17.341
7.879
0.000
0.024
0.022
ENSMUSG00000041453/ENSMUSG00000032518/ENSMUSG00000022884/ENSMUSG00000044533
4
BP
GO:0046543
development of secondary female sexual characteristics
1/37
10/22777
0.100
61.559
7.726
0.016
0.346
0.320
ENSMUSG00000004264
1
BP
GO:1904959
regulation of cytochrome-c oxidase activity
1/37
10/22777
0.100
61.559
7.726
0.016
0.346
0.320
ENSMUSG00000004264
1
BP
GO:0060052
neurofilament cytoskeleton organization
1/37
11/22777
0.091
55.963
7.355
0.018
0.346
0.320
ENSMUSG00000021662
1
BP
GO:1904732
regulation of electron transfer activity
1/37
11/22777
0.091
55.963
7.355
0.018
0.346
0.320
ENSMUSG00000004264
1
BP
GO:0009086
methionine biosynthetic process
1/37
13/22777
0.077
47.353
6.743
0.021
0.346
0.320
ENSMUSG00000010911
1
BP
GO:0045136
development of secondary sexual characteristics
1/37
13/22777
0.077
47.353
6.743
0.021
0.346
0.320
ENSMUSG00000004264
1
BP
GO:0018342
protein prenylation
1/37
14/22777
0.071
43.971
6.487
0.023
0.346
0.320
ENSMUSG00000038975
1
BP
GO:0097354
prenylation
1/37
14/22777
0.071
43.971
6.487
0.023
0.346
0.320
ENSMUSG00000038975
1
BP
GO:0006555
methionine metabolic process
1/37
15/22777
0.067
41.040
6.257
0.024
0.346
0.320
ENSMUSG00000010911
1
BP
GO:0033147
negative regulation of intracellular estrogen receptor signaling pathway
1/37
15/22777
0.067
41.040
6.257
0.024
0.346
0.320
ENSMUSG00000004264
1
BP
GO:0046058
cAMP metabolic process
1/37
15/22777
0.067
41.040
6.257
0.024
0.346
0.320
ENSMUSG00000032177
1
BP
GO:0000097
sulfur amino acid biosynthetic process
1/37
16/22777
0.062
38.475
6.048
0.026
0.346
0.320
ENSMUSG00000010911
1
BP
GO:0023035
CD40 signaling pathway
1/37
16/22777
0.062
38.475
6.048
0.026
0.346
0.320
ENSMUSG00000004264
1
BP
GO:0032048
cardiolipin metabolic process
1/37
16/22777
0.062
38.475
6.048
0.026
0.346
0.320
ENSMUSG00000004264
1
BP
GO:0007096
regulation of exit from mitosis
1/37
17/22777
0.059
36.211
5.858
0.027
0.346
0.320
ENSMUSG00000004264
1
BP
GO:0033194
response to hydroperoxide
1/37
18/22777
0.056
34.200
5.684
0.029
0.346
0.320
ENSMUSG00000064341
1
BP
GO:0106070
regulation of adenylate cyclase-activating G protein-coupled receptor signaling pathway
1/37
19/22777
0.053
32.400
5.523
0.030
0.346
0.320
ENSMUSG00000032177
1
BP
GO:0000028
ribosomal small subunit assembly
1/37
20/22777
0.050
30.780
5.374
0.032
0.346
0.320
ENSMUSG00000032518
1
BP
GO:0033599
regulation of mammary gland epithelial cell proliferation
1/37
20/22777
0.050
30.780
5.374
0.032
0.346
0.320
ENSMUSG00000004264
1
BP
GO:0009067
aspartate family amino acid biosynthetic process
1/37
21/22777
0.048
29.314
5.236
0.034
0.346
0.320
ENSMUSG00000010911
1
BP
GO:0060749
mammary gland alveolus development
1/37
22/22777
0.045
27.982
5.107
0.035
0.346
0.320
ENSMUSG00000004264
1
BP
GO:0061377
mammary gland lobule development
1/37
22/22777
0.045
27.982
5.107
0.035
0.346
0.320
ENSMUSG00000004264
1
BP
GO:0010738
regulation of protein kinase A signaling
1/37
23/22777
0.043
26.765
4.987
0.037
0.346
0.320
ENSMUSG00000032177
1
BP
GO:0039529
RIG-I signaling pathway
1/37
26/22777
0.038
23.677
4.667
0.041
0.346
0.320
ENSMUSG00000004264
1
BP
GO:0002183
cytoplasmic translational initiation
1/37
27/22777
0.037
22.800
4.572
0.043
0.346
0.320
ENSMUSG00000022884
1
BP
GO:0051443
positive regulation of ubiquitin-protein transferase activity
1/37
27/22777
0.037
22.800
4.572
0.043
0.346
0.320
ENSMUSG00000044533
1
BP
GO:0046471
phosphatidylglycerol metabolic process
1/37
28/22777
0.036
21.986
4.482
0.045
0.346
0.320
ENSMUSG00000004264
1
BP
GO:0006120
mitochondrial electron transport, NADH to ubiquinone
1/37
29/22777
0.034
21.227
4.397
0.046
0.346
0.320
ENSMUSG00000064341
1
BP
GO:0060444
branching involved in mammary gland duct morphogenesis
1/37
29/22777
0.034
21.227
4.397
0.046
0.346
0.320
ENSMUSG00000004264
1
BP
GO:0034067
protein localization to Golgi apparatus
1/37
30/22777
0.033
20.520
4.315
0.048
0.346
0.320
ENSMUSG00000038352
1
BP
GO:0071353
cellular response to interleukin-4
1/37
30/22777
0.033
20.520
4.315
0.048
0.346
0.320
ENSMUSG00000044533
1
BP
GO:0140374
antiviral innate immune response
1/37
30/22777
0.033
20.520
4.315
0.048
0.346
0.320
ENSMUSG00000004264
1
BP
GO:0010458
exit from mitosis
1/37
31/22777
0.032
19.858
4.238
0.049
0.346
0.320
ENSMUSG00000004264
1
BP
GO:0032367
intracellular cholesterol transport
1/37
31/22777
0.032
19.858
4.238
0.049
0.346
0.320
ENSMUSG00000064768
1
BP
GO:0070670
response to interleukin-4
1/37
32/22777
0.031
19.237
4.164
0.051
0.346
0.320
ENSMUSG00000044533
1
BP
GO:0000096
sulfur amino acid metabolic process
1/37
33/22777
0.030
18.654
4.094
0.052
0.346
0.320
ENSMUSG00000010911
1
BP
GO:0010155
regulation of proton transport
1/37
33/22777
0.030
18.654
4.094
0.052
0.346
0.320
ENSMUSG00000004264
1
BP
GO:0033598
mammary gland epithelial cell proliferation
1/37
33/22777
0.030
18.654
4.094
0.052
0.346
0.320
ENSMUSG00000004264
1
BP
GO:0032366
intracellular sterol transport
1/37
34/22777
0.029
18.106
4.026
0.054
0.346
0.320
ENSMUSG00000064768
1
BP
GO:0043094
cellular metabolic compound salvage
1/37
35/22777
0.029
17.588
3.962
0.055
0.346
0.320
ENSMUSG00000010911
1
BP
GO:0052652
cyclic purine nucleotide metabolic process
1/37
35/22777
0.029
17.588
3.962
0.055
0.346
0.320
ENSMUSG00000032177
1
BP
GO:0009187
cyclic nucleotide metabolic process
1/37
36/22777
0.028
17.100
3.900
0.057
0.346
0.320
ENSMUSG00000032177
1
BP
GO:0033146
regulation of intracellular estrogen receptor signaling pathway
1/37
37/22777
0.027
16.638
3.840
0.058
0.346
0.320
ENSMUSG00000004264
1
BP
GO:0000423
mitophagy
1/37
38/22777
0.026
16.200
3.783
0.060
0.346
0.320
ENSMUSG00000004264
1
BP
GO:0009154
purine ribonucleotide catabolic process
1/37
39/22777
0.026
15.784
3.727
0.061
0.346
0.320
ENSMUSG00000032177
1
BP
GO:0033144
negative regulation of intracellular steroid hormone receptor signaling pathway
1/37
40/22777
0.025
15.390
3.674
0.063
0.346
0.320
ENSMUSG00000004264
1
BP
GO:0070269
pyroptotic inflammatory response
1/37
40/22777
0.025
15.390
3.674
0.063
0.346
0.320
ENSMUSG00000010911
1
BP
GO:1903725
regulation of phospholipid metabolic process
1/37
40/22777
0.025
15.390
3.674
0.063
0.346
0.320
ENSMUSG00000004264
1
BP
GO:0009066
aspartate family amino acid metabolic process
1/37
41/22777
0.024
15.015
3.623
0.065
0.346
0.320
ENSMUSG00000010911
1
BP
GO:0010737
protein kinase A signaling
1/37
41/22777
0.024
15.015
3.623
0.065
0.346
0.320
ENSMUSG00000032177
1
BP
GO:0060603
mammary gland duct morphogenesis
1/37
41/22777
0.024
15.015
3.623
0.065
0.346
0.320
ENSMUSG00000004264
1
BP
GO:0032365
intracellular lipid transport
1/37
45/22777
0.022
13.680
3.434
0.071
0.346
0.320
ENSMUSG00000064768
1
BP
GO:0021955
central nervous system neuron axonogenesis
1/37
46/22777
0.022
13.382
3.391
0.072
0.346
0.320
ENSMUSG00000021662
1
BP
GO:0009261
ribonucleotide catabolic process
1/37
48/22777
0.021
12.825
3.308
0.075
0.346
0.320
ENSMUSG00000032177
1
BP
GO:0006195
purine nucleotide catabolic process
1/37
50/22777
0.020
12.312
3.230
0.078
0.346
0.320
ENSMUSG00000032177
1
BP
GO:0010518
positive regulation of phospholipase activity
1/37
51/22777
0.020
12.070
3.193
0.080
0.346
0.320
ENSMUSG00000004264
1
BP
GO:0030520
estrogen receptor signaling pathway
1/37
51/22777
0.020
12.070
3.193
0.080
0.346
0.320
ENSMUSG00000004264
1
BP
GO:0002227
innate immune response in mucosa
1/37
52/22777
0.019
11.838
3.156
0.081
0.346
0.320
ENSMUSG00000062727
1
BP
GO:0051438
regulation of ubiquitin-protein transferase activity
1/37
52/22777
0.019
11.838
3.156
0.081
0.346
0.320
ENSMUSG00000044533
1
BP
GO:0051289
protein homotetramerization
1/37
53/22777
0.019
11.615
3.121
0.083
0.346
0.320
ENSMUSG00000010911
1
BP
GO:0007062
sister chromatid cohesion
1/37
56/22777
0.018
10.993
3.020
0.087
0.346
0.320
ENSMUSG00000004264
1
BP
GO:0072523
purine-containing compound catabolic process
1/37
56/22777
0.018
10.993
3.020
0.087
0.346
0.320
ENSMUSG00000032177
1
BP
GO:0007129
homologous chromosome pairing at meiosis
1/37
57/22777
0.018
10.800
2.988
0.089
0.346
0.320
ENSMUSG00000071470
1
BP
GO:0007131
reciprocal meiotic recombination
1/37
57/22777
0.018
10.800
2.988
0.089
0.346
0.320
ENSMUSG00000071470
1
BP
GO:0140527
reciprocal homologous recombination
1/37
57/22777
0.018
10.800
2.988
0.089
0.346
0.320
ENSMUSG00000071470
1
BP
GO:0031640
killing of cells of another organism
1/37
58/22777
0.017
10.614
2.957
0.090
0.346
0.320
ENSMUSG00000062727
1
BP
GO:0002639
positive regulation of immunoglobulin production
1/37
59/22777
0.017
10.434
2.927
0.092
0.346
0.320
ENSMUSG00000004264
1
BP
GO:1901607
alpha-amino acid biosynthetic process
1/37
59/22777
0.017
10.434
2.927
0.092
0.346
0.320
ENSMUSG00000010911
1
BP
GO:0001825
blastocyst formation
1/37
60/22777
0.017
10.260
2.897
0.093
0.346
0.320
ENSMUSG00000071470
1
BP
GO:0060443
mammary gland morphogenesis
1/37
60/22777
0.017
10.260
2.897
0.093
0.346
0.320
ENSMUSG00000004264
1
BP
GO:1902808
positive regulation of cell cycle G1/S phase transition
1/37
60/22777
0.017
10.260
2.897
0.093
0.346
0.320
ENSMUSG00000004264
1
BP
GO:0010257
NADH dehydrogenase complex assembly
1/37
62/22777
0.016
9.929
2.840
0.096
0.346
0.320
ENSMUSG00000064341
1
BP
GO:0032981
mitochondrial respiratory chain complex I assembly
1/37
62/22777
0.016
9.929
2.840
0.096
0.346
0.320
ENSMUSG00000064341
1
BP
GO:0035176
social behavior
1/37
62/22777
0.016
9.929
2.840
0.096
0.346
0.320
ENSMUSG00000000884
1
BP
GO:0042255
ribosome assembly
1/37
62/22777
0.016
9.929
2.840
0.096
0.346
0.320
ENSMUSG00000032518
1
BP
GO:0010517
regulation of phospholipase activity
1/37
63/22777
0.016
9.771
2.812
0.097
0.346
0.320
ENSMUSG00000004264
1
BP
GO:0060193
positive regulation of lipase activity
1/37
63/22777
0.016
9.771
2.812
0.097
0.346
0.320
ENSMUSG00000004264
1
BP
GO:0019646
aerobic electron transport chain
1/37
64/22777
0.016
9.619
2.785
0.099
0.346
0.320
ENSMUSG00000064341
1
BP
GO:0035825
homologous recombination
1/37
64/22777
0.016
9.619
2.785
0.099
0.346
0.320
ENSMUSG00000071470
1
BP
GO:0070372
regulation of ERK1 and ERK2 cascade
2/37
328/22777
0.006
3.754
2.026
0.099
0.346
0.320
ENSMUSG00000010911/ENSMUSG00000004264
2
BP
GO:0042776
proton motive force-driven mitochondrial ATP synthesis
1/37
65/22777
0.015
9.471
2.759
0.100
0.346
0.320
ENSMUSG00000064341
1
BP
GO:0051703
biological process involved in intraspecies interaction between organisms
1/37
65/22777
0.015
9.471
2.759
0.100
0.346
0.320
ENSMUSG00000000884
1
BP
GO:0002385
mucosal immune response
1/37
66/22777
0.015
9.327
2.733
0.102
0.346
0.320
ENSMUSG00000062727
1
BP
GO:0060688
regulation of morphogenesis of a branching structure
1/37
66/22777
0.015
9.327
2.733
0.102
0.346
0.320
ENSMUSG00000004264
1
BP
GO:0008652
amino acid biosynthetic process
1/37
67/22777
0.015
9.188
2.707
0.103
0.346
0.320
ENSMUSG00000010911
1
BP
GO:0009166
nucleotide catabolic process
1/37
68/22777
0.015
9.053
2.683
0.105
0.346
0.320
ENSMUSG00000032177
1
BP
GO:0015986
proton motive force-driven ATP synthesis
1/37
69/22777
0.014
8.922
2.658
0.106
0.346
0.320
ENSMUSG00000064341
1
BP
GO:1901224
positive regulation of non-canonical NF-kappaB signal transduction
1/37
69/22777
0.014
8.922
2.658
0.106
0.346
0.320
ENSMUSG00000004264
1
BP
GO:0002251
organ or tissue specific immune response
1/37
70/22777
0.014
8.794
2.634
0.108
0.346
0.320
ENSMUSG00000062727
1
BP
GO:0045143
homologous chromosome segregation
1/37
71/22777
0.014
8.670
2.611
0.109
0.346
0.320
ENSMUSG00000071470
1
BP
GO:0070371
ERK1 and ERK2 cascade
2/37
352/22777
0.006
3.498
1.905
0.111
0.346
0.320
ENSMUSG00000010911/ENSMUSG00000004264
2
BP
GO:0042274
ribosomal small subunit biogenesis
1/37
73/22777
0.014
8.433
2.566
0.112
0.346
0.320
ENSMUSG00000032518
1
BP
GO:1905330
regulation of morphogenesis of an epithelium
1/37
73/22777
0.014
8.433
2.566
0.112
0.346
0.320
ENSMUSG00000004264
1
BP
GO:0042775
mitochondrial ATP synthesis coupled electron transport
1/37
77/22777
0.013
7.995
2.480
0.118
0.354
0.327
ENSMUSG00000064341
1
BP
GO:1901292
nucleoside phosphate catabolic process
1/37
77/22777
0.013
7.995
2.480
0.118
0.354
0.327
ENSMUSG00000032177
1
BP
GO:0061180
mammary gland epithelium development
1/37
78/22777
0.013
7.892
2.460
0.119
0.354
0.327
ENSMUSG00000004264
1
BP
GO:0033143
regulation of intracellular steroid hormone receptor signaling pathway
1/37
79/22777
0.013
7.792
2.439
0.121
0.354
0.327
ENSMUSG00000004264
1
BP
GO:0042773
ATP synthesis coupled electron transport
1/37
79/22777
0.013
7.792
2.439
0.121
0.354
0.327
ENSMUSG00000064341
1
BP
GO:0070192
chromosome organization involved in meiotic cell cycle
1/37
81/22777
0.012
7.600
2.400
0.124
0.358
0.332
ENSMUSG00000071470
1
ONTOLOGY
ID
Description
GeneRatio
BgRatio
RichFactor
FoldEnrichment
zScore
pvalue
p.adjust
qvalue
geneID
Count
BP
GO:0002181
cytoplasmic translation
4/43
142/22777
0.028
14.921
7.237
0.000
0.058
0.053
ENSMUSG00000042699/ENSMUSG00000041453/ENSMUSG00000007892/ENSMUSG00000044533
4
BP
GO:0070269
pyroptotic inflammatory response
2/43
40/22777
0.050
26.485
7.016
0.003
0.347
0.322
ENSMUSG00000042699/ENSMUSG00000010911
2
BP
GO:0010501
RNA secondary structure unwinding
1/43
10/22777
0.100
52.970
7.149
0.019
0.347
0.322
ENSMUSG00000042699
1
BP
GO:0032661
regulation of interleukin-18 production
1/43
10/22777
0.100
52.970
7.149
0.019
0.347
0.322
ENSMUSG00000042699
1
BP
GO:0046543
development of secondary female sexual characteristics
1/43
10/22777
0.100
52.970
7.149
0.019
0.347
0.322
ENSMUSG00000004264
1
BP
GO:0070934
CRD-mediated mRNA stabilization
1/43
10/22777
0.100
52.970
7.149
0.019
0.347
0.322
ENSMUSG00000042699
1
BP
GO:1904851
positive regulation of establishment of protein localization to telomere
1/43
10/22777
0.100
52.970
7.149
0.019
0.347
0.322
ENSMUSG00000029447
1
BP
GO:1904959
regulation of cytochrome-c oxidase activity
1/43
10/22777
0.100
52.970
7.149
0.019
0.347
0.322
ENSMUSG00000004264
1
BP
GO:0070203
regulation of establishment of protein localization to telomere
1/43
11/22777
0.091
48.154
6.803
0.021
0.347
0.322
ENSMUSG00000029447
1
BP
GO:1900152
negative regulation of nuclear-transcribed mRNA catabolic process, deadenylation-dependent decay
1/43
11/22777
0.091
48.154
6.803
0.021
0.347
0.322
ENSMUSG00000042699
1
BP
GO:1904732
regulation of electron transfer activity
1/43
11/22777
0.091
48.154
6.803
0.021
0.347
0.322
ENSMUSG00000004264
1
BP
GO:0032621
interleukin-18 production
1/43
12/22777
0.083
44.141
6.501
0.022
0.347
0.322
ENSMUSG00000042699
1
BP
GO:0070202
regulation of establishment of protein localization to chromosome
1/43
12/22777
0.083
44.141
6.501
0.022
0.347
0.322
ENSMUSG00000029447
1
BP
GO:0009086
methionine biosynthetic process
1/43
13/22777
0.077
40.746
6.234
0.024
0.347
0.322
ENSMUSG00000010911
1
BP
GO:0045136
development of secondary sexual characteristics
1/43
13/22777
0.077
40.746
6.234
0.024
0.347
0.322
ENSMUSG00000004264
1
BP
GO:0046831
regulation of RNA export from nucleus
1/43
13/22777
0.077
40.746
6.234
0.024
0.347
0.322
ENSMUSG00000042699
1
BP
GO:1904816
positive regulation of protein localization to chromosome, telomeric region
1/43
13/22777
0.077
40.746
6.234
0.024
0.347
0.322
ENSMUSG00000029447
1
BP
GO:2000767
positive regulation of cytoplasmic translation
1/43
14/22777
0.071
37.836
5.996
0.026
0.347
0.322
ENSMUSG00000042699
1
BP
GO:0006555
methionine metabolic process
1/43
15/22777
0.067
35.313
5.781
0.028
0.347
0.322
ENSMUSG00000010911
1
BP
GO:0033147
negative regulation of intracellular estrogen receptor signaling pathway
1/43
15/22777
0.067
35.313
5.781
0.028
0.347
0.322
ENSMUSG00000004264
1
BP
GO:0071360
cellular response to exogenous dsRNA
1/43
15/22777
0.067
35.313
5.781
0.028
0.347
0.322
ENSMUSG00000042699
1
BP
GO:1904814
regulation of protein localization to chromosome, telomeric region
1/43
15/22777
0.067
35.313
5.781
0.028
0.347
0.322
ENSMUSG00000029447
1
BP
GO:0000097
sulfur amino acid biosynthetic process
1/43
16/22777
0.062
33.106
5.587
0.030
0.347
0.322
ENSMUSG00000010911
1
BP
GO:0023035
CD40 signaling pathway
1/43
16/22777
0.062
33.106
5.587
0.030
0.347
0.322
ENSMUSG00000004264
1
BP
GO:0032048
cardiolipin metabolic process
1/43
16/22777
0.062
33.106
5.587
0.030
0.347
0.322
ENSMUSG00000004264
1
BP
GO:0032239
regulation of nucleobase-containing compound transport
1/43
16/22777
0.062
33.106
5.587
0.030
0.347
0.322
ENSMUSG00000042699
1
BP
GO:0007096
regulation of exit from mitosis
1/43
17/22777
0.059
31.159
5.410
0.032
0.347
0.322
ENSMUSG00000004264
1
BP
GO:2000637
positive regulation of miRNA-mediated gene silencing
1/43
17/22777
0.059
31.159
5.410
0.032
0.347
0.322
ENSMUSG00000042699
1
BP
GO:0019081
viral translation
1/43
18/22777
0.056
29.428
5.247
0.033
0.347
0.322
ENSMUSG00000042699
1
BP
GO:0033194
response to hydroperoxide
1/43
18/22777
0.056
29.428
5.247
0.033
0.347
0.322
ENSMUSG00000064341
1
BP
GO:0060148
positive regulation of post-transcriptional gene silencing
1/43
18/22777
0.056
29.428
5.247
0.033
0.347
0.322
ENSMUSG00000042699
1
BP
GO:1900370
positive regulation of post-transcriptional gene silencing by RNA
1/43
18/22777
0.056
29.428
5.247
0.033
0.347
0.322
ENSMUSG00000042699
1
BP
GO:0070200
establishment of protein localization to telomere
1/43
19/22777
0.053
27.879
5.097
0.035
0.347
0.322
ENSMUSG00000029447
1
BP
GO:0033599
regulation of mammary gland epithelial cell proliferation
1/43
20/22777
0.050
26.485
4.959
0.037
0.347
0.322
ENSMUSG00000004264
1
BP
GO:0009067
aspartate family amino acid biosynthetic process
1/43
21/22777
0.048
25.224
4.830
0.039
0.347
0.322
ENSMUSG00000010911
1
BP
GO:0071359
cellular response to dsRNA
1/43
21/22777
0.048
25.224
4.830
0.039
0.347
0.322
ENSMUSG00000042699
1
BP
GO:0046782
regulation of viral transcription
1/43
22/22777
0.045
24.077
4.710
0.041
0.347
0.322
ENSMUSG00000042699
1
BP
GO:0060749
mammary gland alveolus development
1/43
22/22777
0.045
24.077
4.710
0.041
0.347
0.322
ENSMUSG00000004264
1
BP
GO:0061377
mammary gland lobule development
1/43
22/22777
0.045
24.077
4.710
0.041
0.347
0.322
ENSMUSG00000004264
1
BP
GO:0006417
regulation of translation
3/43
408/22777
0.007
3.895
2.566
0.042
0.347
0.322
ENSMUSG00000042699/ENSMUSG00000063884/ENSMUSG00000007892
3
BP
GO:0006353
DNA-templated transcription termination
1/43
25/22777
0.040
21.188
4.392
0.046
0.347
0.322
ENSMUSG00000042699
1
BP
GO:0039529
RIG-I signaling pathway
1/43
26/22777
0.038
20.373
4.299
0.048
0.347
0.322
ENSMUSG00000004264
1
BP
GO:1900151
regulation of nuclear-transcribed mRNA catabolic process, deadenylation-dependent decay
1/43
26/22777
0.038
20.373
4.299
0.048
0.347
0.322
ENSMUSG00000042699
1
BP
GO:0032727
positive regulation of interferon-alpha production
1/43
27/22777
0.037
19.618
4.210
0.050
0.347
0.322
ENSMUSG00000042699
1
BP
GO:0051443
positive regulation of ubiquitin-protein transferase activity
1/43
27/22777
0.037
19.618
4.210
0.050
0.347
0.322
ENSMUSG00000044533
1
BP
GO:2000765
regulation of cytoplasmic translation
1/43
27/22777
0.037
19.618
4.210
0.050
0.347
0.322
ENSMUSG00000042699
1
BP
GO:0046471
phosphatidylglycerol metabolic process
1/43
28/22777
0.036
18.918
4.126
0.052
0.347
0.322
ENSMUSG00000004264
1
BP
GO:0050821
protein stabilization
2/43
196/22777
0.010
5.405
2.694
0.053
0.347
0.322
ENSMUSG00000029447/ENSMUSG00000004264
2
BP
GO:0006120
mitochondrial electron transport, NADH to ubiquinone
1/43
29/22777
0.034
18.265
4.046
0.053
0.347
0.322
ENSMUSG00000064341
1
BP
GO:0060444
branching involved in mammary gland duct morphogenesis
1/43
29/22777
0.034
18.265
4.046
0.053
0.347
0.322
ENSMUSG00000004264
1
BP
GO:0070199
establishment of protein localization to chromosome
1/43
30/22777
0.033
17.657
3.970
0.055
0.347
0.322
ENSMUSG00000029447
1
BP
GO:0071353
cellular response to interleukin-4
1/43
30/22777
0.033
17.657
3.970
0.055
0.347
0.322
ENSMUSG00000044533
1
BP
GO:0140374
antiviral innate immune response
1/43
30/22777
0.033
17.657
3.970
0.055
0.347
0.322
ENSMUSG00000004264
1
BP
GO:0010458
exit from mitosis
1/43
31/22777
0.032
17.087
3.898
0.057
0.347
0.322
ENSMUSG00000004264
1
BP
GO:0032647
regulation of interferon-alpha production
1/43
32/22777
0.031
16.553
3.829
0.059
0.347
0.322
ENSMUSG00000042699
1
BP
GO:0070198
protein localization to chromosome, telomeric region
1/43
32/22777
0.031
16.553
3.829
0.059
0.347
0.322
ENSMUSG00000029447
1
BP
GO:0070670
response to interleukin-4
1/43
32/22777
0.031
16.553
3.829
0.059
0.347
0.322
ENSMUSG00000044533
1
BP
GO:0034248
regulation of amide metabolic process
3/43
470/22777
0.006
3.381
2.268
0.059
0.347
0.322
ENSMUSG00000042699/ENSMUSG00000063884/ENSMUSG00000007892
3
BP
GO:0000096
sulfur amino acid metabolic process
1/43
33/22777
0.030
16.051
3.763
0.060
0.347
0.322
ENSMUSG00000010911
1
BP
GO:0006270
DNA replication initiation
1/43
33/22777
0.030
16.051
3.763
0.060
0.347
0.322
ENSMUSG00000064945
1
BP
GO:0010155
regulation of proton transport
1/43
33/22777
0.030
16.051
3.763
0.060
0.347
0.322
ENSMUSG00000004264
1
BP
GO:0032212
positive regulation of telomere maintenance via telomerase
1/43
33/22777
0.030
16.051
3.763
0.060
0.347
0.322
ENSMUSG00000029447
1
BP
GO:0033260
nuclear DNA replication
1/43
33/22777
0.030
16.051
3.763
0.060
0.347
0.322
ENSMUSG00000064945
1
BP
GO:0033598
mammary gland epithelial cell proliferation
1/43
33/22777
0.030
16.051
3.763
0.060
0.347
0.322
ENSMUSG00000004264
1
BP
GO:0060964
regulation of miRNA-mediated gene silencing
1/43
34/22777
0.029
15.579
3.700
0.062
0.347
0.322
ENSMUSG00000042699
1
BP
GO:0032607
interferon-alpha production
1/43
35/22777
0.029
15.134
3.639
0.064
0.347
0.322
ENSMUSG00000042699
1
BP
GO:0043094
cellular metabolic compound salvage
1/43
35/22777
0.029
15.134
3.639
0.064
0.347
0.322
ENSMUSG00000010911
1
BP
GO:1900368
regulation of post-transcriptional gene silencing by regulatory ncRNA
1/43
36/22777
0.028
14.714
3.581
0.066
0.347
0.322
ENSMUSG00000042699
1
BP
GO:0033146
regulation of intracellular estrogen receptor signaling pathway
1/43
37/22777
0.027
14.316
3.525
0.068
0.347
0.322
ENSMUSG00000004264
1
BP
GO:0060147
regulation of post-transcriptional gene silencing
1/43
37/22777
0.027
14.316
3.525
0.068
0.347
0.322
ENSMUSG00000042699
1
BP
GO:1904358
positive regulation of telomere maintenance via telomere lengthening
1/43
37/22777
0.027
14.316
3.525
0.068
0.347
0.322
ENSMUSG00000029447
1
BP
GO:0000423
mitophagy
1/43
38/22777
0.026
13.939
3.472
0.069
0.347
0.322
ENSMUSG00000004264
1
BP
GO:0044786
cell cycle DNA replication
1/43
38/22777
0.026
13.939
3.472
0.069
0.347
0.322
ENSMUSG00000064945
1
BP
GO:0060966
regulation of gene silencing by regulatory ncRNA
1/43
38/22777
0.026
13.939
3.472
0.069
0.347
0.322
ENSMUSG00000042699
1
BP
GO:0033144
negative regulation of intracellular steroid hormone receptor signaling pathway
1/43
40/22777
0.025
13.242
3.370
0.073
0.347
0.322
ENSMUSG00000004264
1
BP
GO:1903725
regulation of phospholipid metabolic process
1/43
40/22777
0.025
13.242
3.370
0.073
0.347
0.322
ENSMUSG00000004264
1
BP
GO:0009066
aspartate family amino acid metabolic process
1/43
41/22777
0.024
12.919
3.322
0.075
0.347
0.322
ENSMUSG00000010911
1
BP
GO:0060603
mammary gland duct morphogenesis
1/43
41/22777
0.024
12.919
3.322
0.075
0.347
0.322
ENSMUSG00000004264
1
BP
GO:0032508
DNA duplex unwinding
1/43
44/22777
0.023
12.039
3.187
0.080
0.347
0.322
ENSMUSG00000042699
1
BP
GO:0050691
regulation of defense response to virus by host
1/43
44/22777
0.023
12.039
3.187
0.080
0.347
0.322
ENSMUSG00000042699
1
BP
GO:0032781
positive regulation of ATP-dependent activity
1/43
45/22777
0.022
11.771
3.145
0.082
0.347
0.322
ENSMUSG00000042699
1
BP
GO:0007339
binding of sperm to zona pellucida
1/43
49/22777
0.020
10.810
2.990
0.089
0.347
0.322
ENSMUSG00000029447
1
BP
GO:0032728
positive regulation of interferon-beta production
1/43
49/22777
0.020
10.810
2.990
0.089
0.347
0.322
ENSMUSG00000042699
1
BP
GO:0045740
positive regulation of DNA replication
1/43
49/22777
0.020
10.810
2.990
0.089
0.347
0.322
ENSMUSG00000042699
1
BP
GO:0032210
regulation of telomere maintenance via telomerase
1/43
50/22777
0.020
10.594
2.954
0.090
0.347
0.322
ENSMUSG00000029447
1
BP
GO:0010518
positive regulation of phospholipase activity
1/43
51/22777
0.020
10.386
2.918
0.092
0.347
0.322
ENSMUSG00000004264
1
BP
GO:0030520
estrogen receptor signaling pathway
1/43
51/22777
0.020
10.386
2.918
0.092
0.347
0.322
ENSMUSG00000004264
1
BP
GO:0032392
DNA geometric change
1/43
51/22777
0.020
10.386
2.918
0.092
0.347
0.322
ENSMUSG00000042699
1
BP
GO:0019083
viral transcription
1/43
52/22777
0.019
10.186
2.884
0.094
0.347
0.322
ENSMUSG00000042699
1
BP
GO:0051438
regulation of ubiquitin-protein transferase activity
1/43
52/22777
0.019
10.186
2.884
0.094
0.347
0.322
ENSMUSG00000044533
1
BP
GO:0006260
DNA replication
2/43
273/22777
0.007
3.881
2.082
0.094
0.347
0.322
ENSMUSG00000042699/ENSMUSG00000064945
2
BP
GO:0051289
protein homotetramerization
1/43
53/22777
0.019
9.994
2.851
0.095
0.347
0.322
ENSMUSG00000010911
1
BP
GO:0051091
positive regulation of DNA-binding transcription factor activity
2/43
276/22777
0.007
3.838
2.063
0.096
0.347
0.322
ENSMUSG00000042699/ENSMUSG00000004264
2
BP
GO:0006414
translational elongation
1/43
55/22777
0.018
9.631
2.787
0.099
0.347
0.322
ENSMUSG00000007892
1
BP
GO:0034605
cellular response to heat
1/43
55/22777
0.018
9.631
2.787
0.099
0.347
0.322
ENSMUSG00000042699
1
BP
GO:0007062
sister chromatid cohesion
1/43
56/22777
0.018
9.459
2.756
0.101
0.347
0.322
ENSMUSG00000004264
1
BP
GO:0007129
homologous chromosome pairing at meiosis
1/43
57/22777
0.018
9.293
2.726
0.102
0.347
0.322
ENSMUSG00000071470
1
BP
GO:0007131
reciprocal meiotic recombination
1/43
57/22777
0.018
9.293
2.726
0.102
0.347
0.322
ENSMUSG00000071470
1
BP
GO:0043330
response to exogenous dsRNA
1/43
57/22777
0.018
9.293
2.726
0.102
0.347
0.322
ENSMUSG00000042699
1
BP
GO:0140527
reciprocal homologous recombination
1/43
57/22777
0.018
9.293
2.726
0.102
0.347
0.322
ENSMUSG00000071470
1
❯
表7.1 GO富集分析部分结果:
Setd2-KO_GO_dotplot Setd2-KO_rep1_GO_dotplot Setd2-KO_rep2_GO_dotplot WT_GO_dotplot WT_rep1_GO_dotplot WT_rep2_GO_dotplot
图7.2 Peak关联基因GO气泡图。纵坐标是GO Term 名称,横坐标是对应GO Term 中检出的基因占背景基因的个数,颜色代表显著性,气泡大小代表该条目基因比例。
Setd2-KO_GO_barplot Setd2-KO_rep1_GO_barplot Setd2-KO_rep2_GO_barplot WT_GO_barplot WT_rep1_GO_barplot WT_rep2_GO_barplot
图7.3 Peak关联基因GO条状图。按照BP、MF、CC三个方面分别展示GO富集结果。纵坐标是GO Term 名称,横坐标值越大显著性越高,如果为0代表qvalue等于1。
7.2 KEGG富集分析
KEGG (Kyoto Encyclopedia of Genes and Genomes, http://www.genome.jp/kegg/) 是日本京都大学构建的基因组信息数据库,它将基因组序列信息与功能信息相结合,提供了一个全面的基因组功能信息资源。在PATHWAY数据库里,包括图解的细胞生化过程如代谢、膜转运、信号传递、细胞周期,还包括同系保守的子通路等信息。KEGG富集分析可以对peak关联基因进行KEGG通路富集分析。
下面展示peak关联的基因富集KEGG富集分析部分结果,完整结果请见/result/6.gokegg/GOALLterm_peakanno_*.csv。GO富集分析完整结果请详见位于report/result/6.gokegg 文件夹的*_KEGG_res.csv表格文件。
Setd2-KO_KEGG_res Setd2-KO_rep1_KEGG_res Setd2-KO_rep2_KEGG_res WT_KEGG_res WT_rep1_KEGG_res WT_rep2_KEGG_res
❮
ID
Description
GeneRatio
BgRatio
RichFactor
FoldEnrichment
zScore
pvalue
p.adjust
qvalue
geneID
Count
05322
Systemic lupus erythematosus
6/16
142/6516
0.042
17.208
9.688
0.000
0.000
0.000
ENSMUSG00000069305/ENSMUSG00000062727/ENSMUSG00000060639/ENSMUSG00000060981/ENSMUSG00000075031/ENSMUSG00000096010
6
03010
Ribosome
4/16
102/6516
0.039
15.971
7.560
0.000
0.000
0.000
ENSMUSG00000044533/ENSMUSG00000041453/ENSMUSG00000074129/ENSMUSG00000032518
4
00290
Valine, leucine and isoleucine biosynthesis
1/16
11/6516
0.091
37.023
5.932
0.027
0.071
0.047
ENSMUSG00000035202
1
03013
Nucleocytoplasmic transport
2/16
160/6516
0.013
5.091
2.599
0.057
0.112
0.074
ENSMUSG00000059796/ENSMUSG00000022884
2
03410
Base excision repair
1/16
35/6516
0.029
11.636
3.130
0.083
0.112
0.074
ENSMUSG00000036023
1
00270
Cysteine and methionine metabolism
1/16
36/6516
0.028
11.312
3.078
0.085
0.112
0.074
ENSMUSG00000010911
1
00970
Aminoacyl-tRNA biosynthesis
1/16
42/6516
0.024
9.696
2.805
0.098
0.112
0.074
ENSMUSG00000035202
1
03008
Ribosome biogenesis in eukaryotes
1/16
77/6516
0.013
5.289
1.878
0.173
0.173
0.114
ENSMUSG00000027405
1
ID
Description
GeneRatio
BgRatio
RichFactor
FoldEnrichment
zScore
pvalue
p.adjust
qvalue
geneID
Count
05322
Systemic lupus erythematosus
10/18
142/6516
0.070
25.493
15.530
0.000
0.000
0.000
ENSMUSG00000096010/ENSMUSG00000094338/ENSMUSG00000069307/ENSMUSG00000069305/ENSMUSG00000062727/ENSMUSG00000060639/ENSMUSG00000060981/ENSMUSG00000061991/ENSMUSG00000075031/ENSMUSG00000060093
10
03010
Ribosome
4/18
102/6516
0.039
14.196
7.069
0.000
0.001
0.001
ENSMUSG00000041453/ENSMUSG00000074129/ENSMUSG00000032518/ENSMUSG00000044533
4
00290
Valine, leucine and isoleucine biosynthesis
1/18
11/6516
0.091
32.909
5.574
0.030
0.150
0.126
ENSMUSG00000035202
1
00970
Aminoacyl-tRNA biosynthesis
1/18
42/6516
0.024
8.619
2.607
0.110
0.335
0.282
ENSMUSG00000035202
1
05144
Malaria
1/18
45/6516
0.022
8.044
2.496
0.117
0.335
0.282
ENSMUSG00000027995
1
05140
Leishmaniasis
1/18
64/6516
0.016
5.656
1.970
0.163
0.335
0.282
ENSMUSG00000027995
1
03008
Ribosome biogenesis in eukaryotes
1/18
77/6516
0.013
4.701
1.719
0.193
0.335
0.282
ENSMUSG00000027405
1
05323
Rheumatoid arthritis
1/18
81/6516
0.012
4.469
1.653
0.202
0.335
0.282
ENSMUSG00000027995
1
04620
Toll-like receptor signaling pathway
1/18
101/6516
0.010
3.584
1.377
0.245
0.335
0.282
ENSMUSG00000027995
1
05142
Chagas disease
1/18
101/6516
0.010
3.584
1.377
0.245
0.335
0.282
ENSMUSG00000027995
1
05146
Amoebiasis
1/18
117/6516
0.009
3.094
1.203
0.279
0.335
0.282
ENSMUSG00000027995
1
05145
Toxoplasmosis
1/18
127/6516
0.008
2.850
1.108
0.299
0.335
0.282
ENSMUSG00000027995
1
05012
Parkinson disease
1/18
133/6516
0.008
2.722
1.056
0.310
0.335
0.282
ENSMUSG00000064363
1
00190
Oxidative phosphorylation
1/18
134/6516
0.007
2.701
1.047
0.312
0.335
0.282
ENSMUSG00000064363
1
04145
Phagosome
1/18
168/6516
0.006
2.155
0.798
0.375
0.375
0.316
ENSMUSG00000027995
1
ID
Description
GeneRatio
BgRatio
RichFactor
FoldEnrichment
zScore
pvalue
p.adjust
qvalue
geneID
Count
05322
Systemic lupus erythematosus
10/19
142/6516
0.070
24.151
15.083
0.000
0.000
0.000
ENSMUSG00000105827/ENSMUSG00000101355/ENSMUSG00000095217/ENSMUSG00000069305/ENSMUSG00000062727/ENSMUSG00000058385/ENSMUSG00000099583/ENSMUSG00000061482/ENSMUSG00000018102/ENSMUSG00000075031
10
03010
Ribosome
4/19
102/6516
0.039
13.449
6.852
0.000
0.002
0.002
ENSMUSG00000100755/ENSMUSG00000074129/ENSMUSG00000061983/ENSMUSG00000044533
4
00290
Valine, leucine and isoleucine biosynthesis
1/19
11/6516
0.091
31.177
5.417
0.032
0.232
0.211
ENSMUSG00000035202
1
00270
Cysteine and methionine metabolism
1/19
36/6516
0.028
9.526
2.774
0.100
0.390
0.354
ENSMUSG00000010911
1
00970
Aminoacyl-tRNA biosynthesis
1/19
42/6516
0.024
8.165
2.519
0.116
0.390
0.354
ENSMUSG00000035202
1
05100
Bacterial invasion of epithelial cells
1/19
71/6516
0.014
4.830
1.755
0.188
0.390
0.354
ENSMUSG00000029580
1
04520
Adherens junction
1/19
73/6516
0.014
4.698
1.718
0.193
0.390
0.354
ENSMUSG00000029580
1
04971
Gastric acid secretion
1/19
73/6516
0.014
4.698
1.718
0.193
0.390
0.354
ENSMUSG00000029580
1
05412
Arrhythmogenic right ventricular cardiomyopathy
1/19
74/6516
0.014
4.634
1.700
0.195
0.390
0.354
ENSMUSG00000029580
1
03008
Ribosome biogenesis in eukaryotes
1/19
77/6516
0.013
4.454
1.649
0.202
0.390
0.354
ENSMUSG00000027405
1
05410
Hypertrophic cardiomyopathy
1/19
83/6516
0.012
4.132
1.553
0.216
0.390
0.354
ENSMUSG00000029580
1
05416
Viral myocarditis
1/19
85/6516
0.012
4.035
1.523
0.221
0.390
0.354
ENSMUSG00000029580
1
05414
Dilated cardiomyopathy
1/19
89/6516
0.011
3.853
1.466
0.230
0.390
0.354
ENSMUSG00000029580
1
04670
Leukocyte transendothelial migration
1/19
119/6516
0.008
2.882
1.120
0.296
0.423
0.384
ENSMUSG00000029580
1
05012
Parkinson disease
1/19
133/6516
0.008
2.579
0.995
0.325
0.423
0.384
ENSMUSG00000064357
1
00190
Oxidative phosphorylation
1/19
134/6516
0.007
2.559
0.986
0.327
0.423
0.384
ENSMUSG00000064357
1
04530
Tight junction
1/19
134/6516
0.007
2.559
0.986
0.327
0.423
0.384
ENSMUSG00000029580
1
04145
Phagosome
1/19
168/6516
0.006
2.041
0.739
0.392
0.456
0.415
ENSMUSG00000029580
1
05010
Alzheimer disease
1/19
174/6516
0.006
1.971
0.702
0.402
0.456
0.415
ENSMUSG00000064357
1
05016
Huntington disease
1/19
181/6516
0.006
1.895
0.660
0.415
0.456
0.415
ENSMUSG00000064357
1
04510
Focal adhesion
1/19
200/6516
0.005
1.715
0.555
0.447
0.469
0.426
ENSMUSG00000029580
1
04810
Regulation of actin cytoskeleton
1/19
215/6516
0.005
1.595
0.480
0.472
0.472
0.429
ENSMUSG00000029580
1
ID
Description
GeneRatio
BgRatio
RichFactor
FoldEnrichment
zScore
pvalue
p.adjust
qvalue
geneID
Count
05322
Systemic lupus erythematosus
6/16
142/6516
0.042
17.208
9.688
0.000
0.000
0.000
ENSMUSG00000069305/ENSMUSG00000062727/ENSMUSG00000060639/ENSMUSG00000060981/ENSMUSG00000075031/ENSMUSG00000096010
6
03010
Ribosome
4/16
102/6516
0.039
15.971
7.560
0.000
0.000
0.000
ENSMUSG00000044533/ENSMUSG00000041453/ENSMUSG00000074129/ENSMUSG00000032518
4
00290
Valine, leucine and isoleucine biosynthesis
1/16
11/6516
0.091
37.023
5.932
0.027
0.071
0.047
ENSMUSG00000035202
1
03013
Nucleocytoplasmic transport
2/16
160/6516
0.013
5.091
2.599
0.057
0.112
0.074
ENSMUSG00000059796/ENSMUSG00000022884
2
03410
Base excision repair
1/16
35/6516
0.029
11.636
3.130
0.083
0.112
0.074
ENSMUSG00000036023
1
00270
Cysteine and methionine metabolism
1/16
36/6516
0.028
11.312
3.078
0.085
0.112
0.074
ENSMUSG00000010911
1
00970
Aminoacyl-tRNA biosynthesis
1/16
42/6516
0.024
9.696
2.805
0.098
0.112
0.074
ENSMUSG00000035202
1
03008
Ribosome biogenesis in eukaryotes
1/16
77/6516
0.013
5.289
1.878
0.173
0.173
0.114
ENSMUSG00000027405
1
ID
Description
GeneRatio
BgRatio
RichFactor
FoldEnrichment
zScore
pvalue
p.adjust
qvalue
geneID
Count
05322
Systemic lupus erythematosus
5/12
142/6516
0.035
19.120
9.377
0.000
0.000
0.000
ENSMUSG00000105827/ENSMUSG00000096010/ENSMUSG00000062727/ENSMUSG00000061482/ENSMUSG00000075031
5
03010
Ribosome
3/12
102/6516
0.029
15.971
6.545
0.001
0.003
0.002
ENSMUSG00000041453/ENSMUSG00000032518/ENSMUSG00000044533
3
00270
Cysteine and methionine metabolism
1/12
36/6516
0.028
15.083
3.639
0.064
0.150
0.113
ENSMUSG00000010911
1
05012
Parkinson disease
1/12
133/6516
0.008
4.083
1.543
0.219
0.267
0.200
ENSMUSG00000064341
1
00190
Oxidative phosphorylation
1/12
134/6516
0.007
4.052
1.533
0.221
0.267
0.200
ENSMUSG00000064341
1
03013
Nucleocytoplasmic transport
1/12
160/6516
0.006
3.394
1.317
0.258
0.267
0.200
ENSMUSG00000022884
1
00230
Purine metabolism
1/12
166/6516
0.006
3.271
1.273
0.267
0.267
0.200
ENSMUSG00000032177
1
ID
Description
GeneRatio
BgRatio
RichFactor
FoldEnrichment
zScore
pvalue
p.adjust
qvalue
geneID
Count
05322
Systemic lupus erythematosus
4/11
142/6516
0.028
16.686
7.771
0.000
0.000
0.000
ENSMUSG00000069305/ENSMUSG00000060639/ENSMUSG00000060981/ENSMUSG00000069274
4
03010
Ribosome
3/11
102/6516
0.029
17.422
6.874
0.001
0.002
0.001
ENSMUSG00000041453/ENSMUSG00000007892/ENSMUSG00000044533
3
00270
Cysteine and methionine metabolism
1/11
36/6516
0.028
16.455
3.823
0.059
0.118
0.083
ENSMUSG00000010911
1
03008
Ribosome biogenesis in eukaryotes
1/11
77/6516
0.013
7.693
2.429
0.123
0.184
0.129
ENSMUSG00000027405
1
05012
Parkinson disease
1/11
133/6516
0.008
4.454
1.655
0.203
0.204
0.143
ENSMUSG00000064341
1
00190
Oxidative phosphorylation
1/11
134/6516
0.007
4.421
1.645
0.204
0.204
0.143
ENSMUSG00000064341
1
❯
表7.2 KEGG富集分析部分结果:
Setd2-KO_KEGG_dotplot Setd2-KO_rep1_KEGG_dotplot Setd2-KO_rep2_KEGG_dotplot WT_KEGG_dotplot WT_rep1_KEGG_dotplot WT_rep2_KEGG_dotplot
图7.4 Peak关联基因KEGG气泡图。纵坐标是KEGG通路名称,横坐标是对应KEGG通路中检出的基因占背景基因的个数,颜色代表显著性,气泡大小代表该通路基因比例。
Setd2-KO_KEGG_barplot Setd2-KO_rep1_KEGG_barplot Setd2-KO_rep2_KEGG_barplot WT_KEGG_barplot WT_rep1_KEGG_barplot WT_rep2_KEGG_barplot
图7.5 Peak关联基因KEGG条状图。纵坐标是KEGG通路名称,横坐标是出现在该通路的基因数,颜色代表显著性。
8. Motif分析
对于一些基因元件或peak区域,分析这些区域的序列中是否有频繁出现的一些基序(motif),从而可以进一步分析这些基序相关的转录因子或结合蛋白。各种蛋白通过不同的motif识别蛋白-DNA结合位点,因此我们通过Homer(version 4.11.1)(Heinz S et al., 2010)来提取peak所在区间的序列对peak之间共有的motif进行扫描,查找其共有的motif区域,基于富集分析预测可能与peaks结合的蛋白。对于有组内生物学重复的样本,我们取其交集({组名}_consensus)进行motif分析。各样本分析结果位于report/result/7.motif 文件夹中:knownResults.html :基于已知motifs富集的格式化输出。homerResults.html :de novo预测motif的格式化输出。
8.1 已知Motif分析
基于已知motifs富集的分析结果,请打开下方链接查看,其文件对应在各个文件夹下的“knownResults.html”
结果说明:
8.2 从头预测Motif分析
基于de novo 从头预测的motifs富集的分析结果,请打开下方链接查看,其文件对应在各个文件夹下的“homerResults.html”。
结果说明:
参考文献
联系我们
官网:武汉鸿源韬生物科技有限公司 咨询热线:18086690478
邮箱:sales@hyt-bio.com 地址:湖北省武汉市江夏区郑店街光谷南(郑店)大健康产业园东湖高新国际健康城B地块1号楼7层02号房
报告文件结构
▶ result - 项目结果文件夹 ▶ 3.peak - peak鉴定结果目录 ▶ 5.anno - peak基因组注释结果 ▶ 1.qc - 质量控制结果目录 ▶ 4.diff - 差异peak分析结果 ▶ 6.gokegg - peak关联基因富集分析结果 ▶ 7.motif - peak序列motif分析结果 ▶ 2.map - 比对结果统计 report.pdf ▶ lib - 网页渲染所需文件 report.html


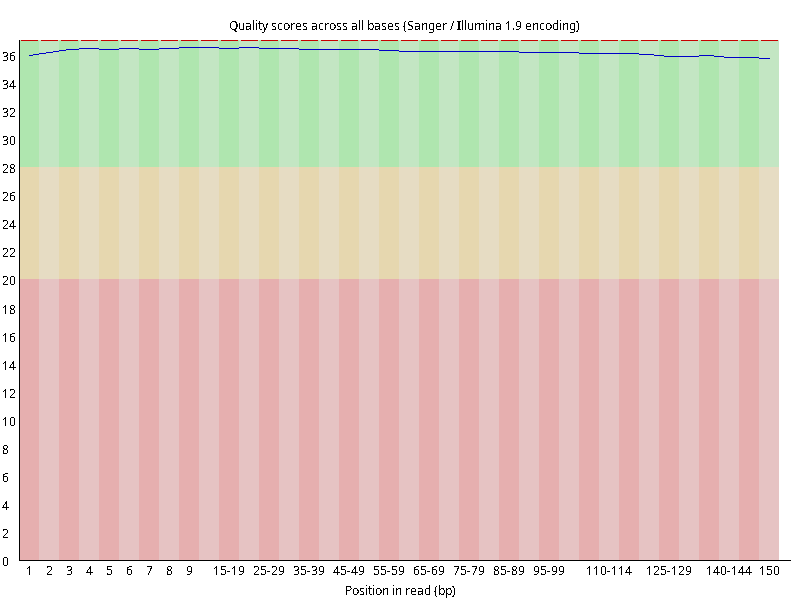
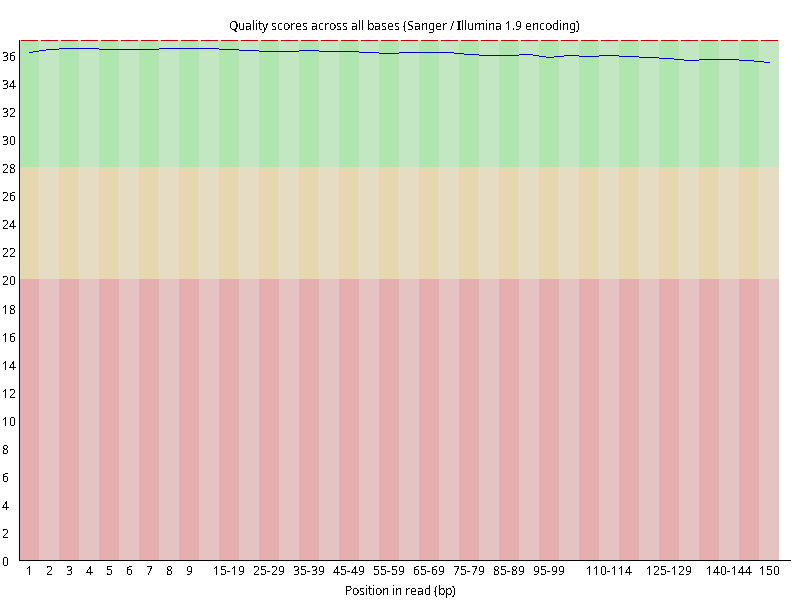
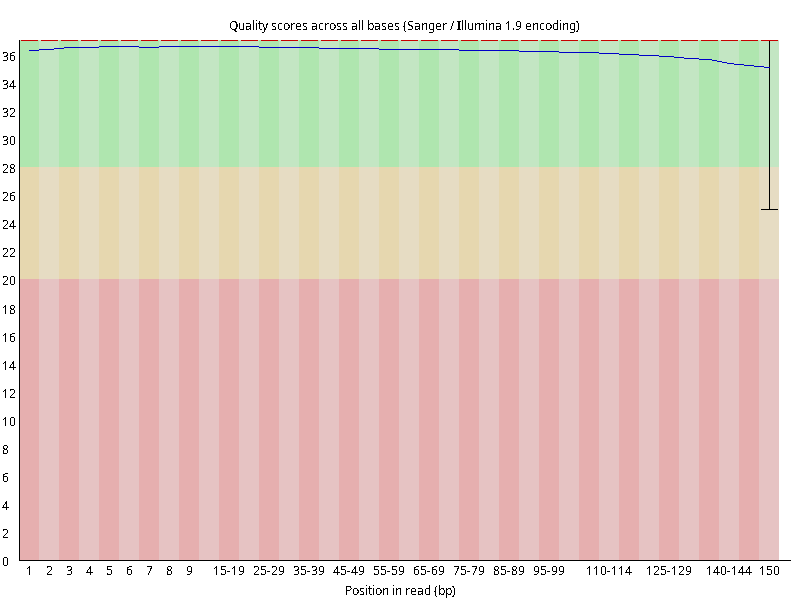
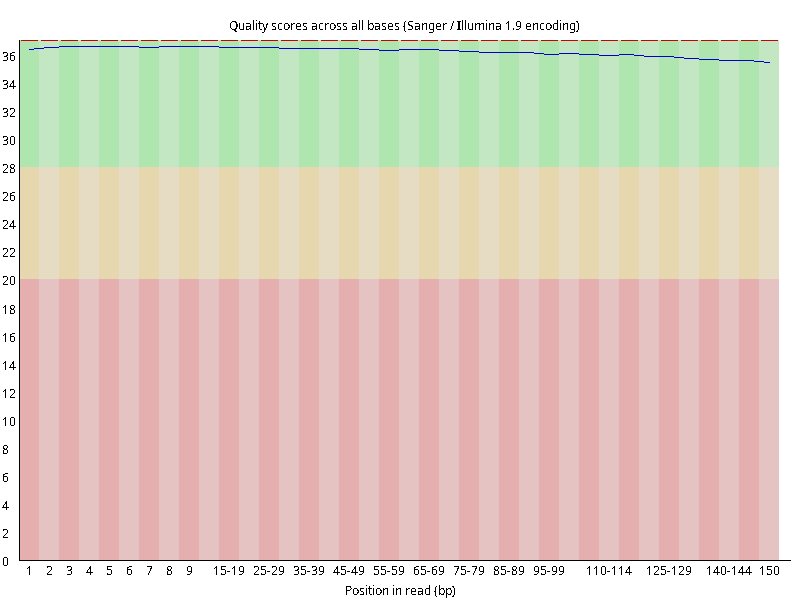
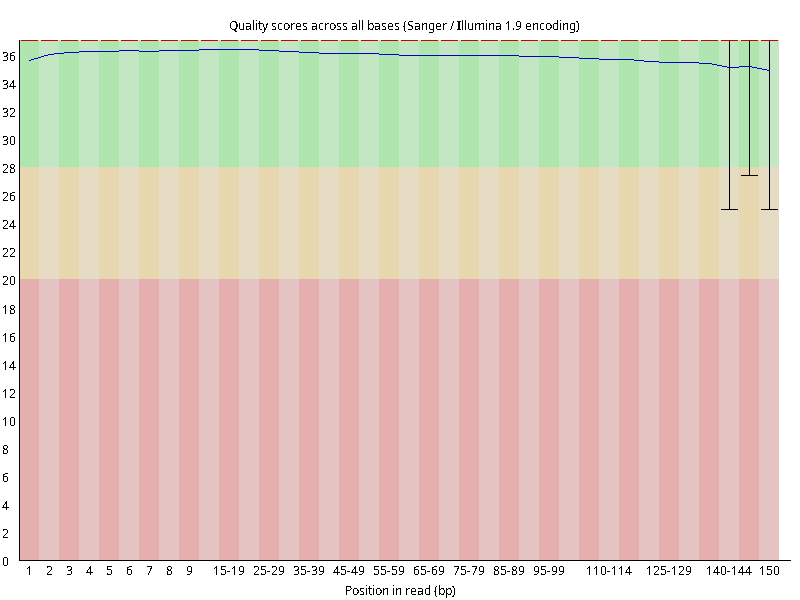
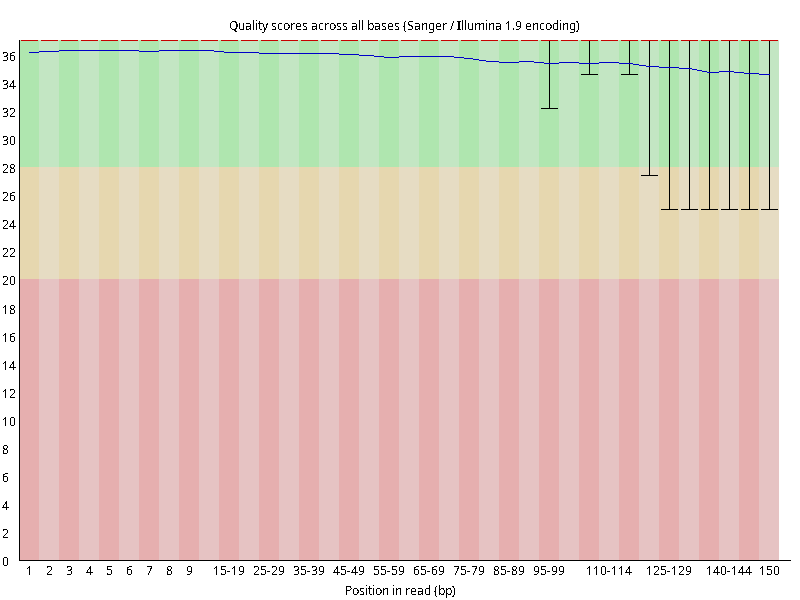
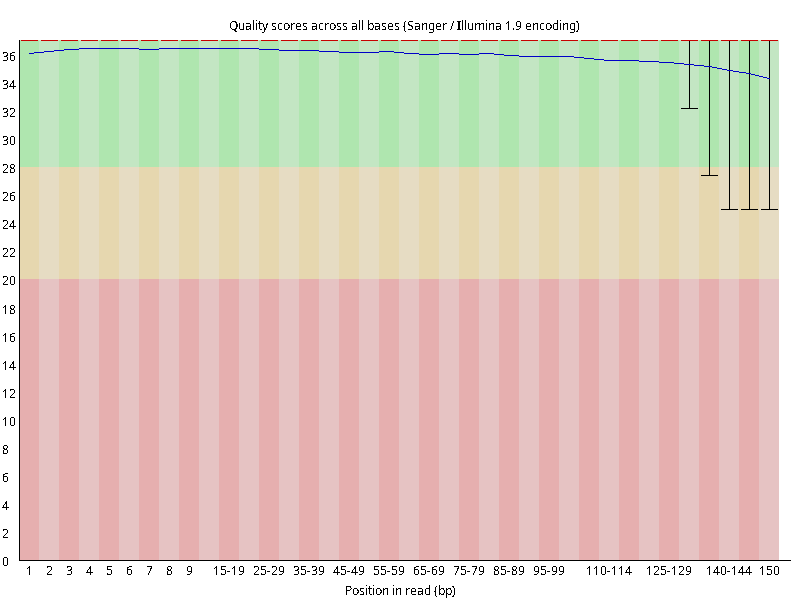
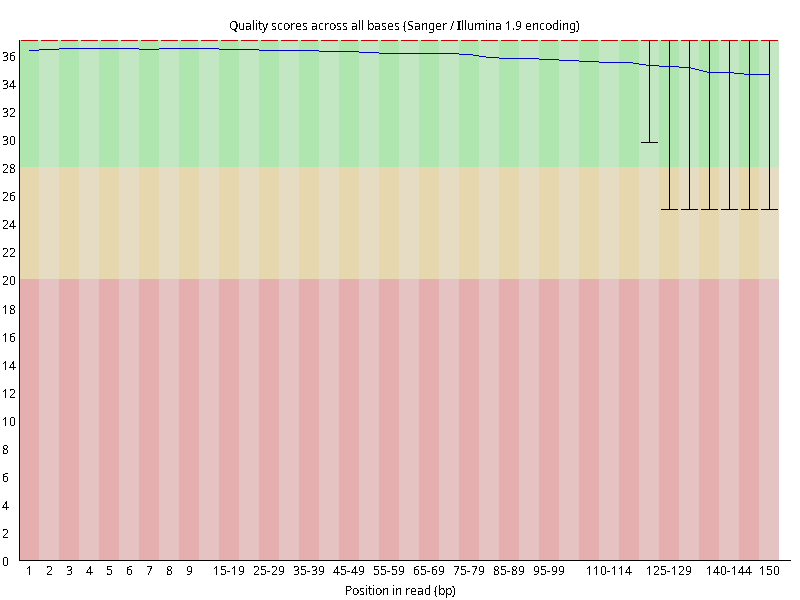
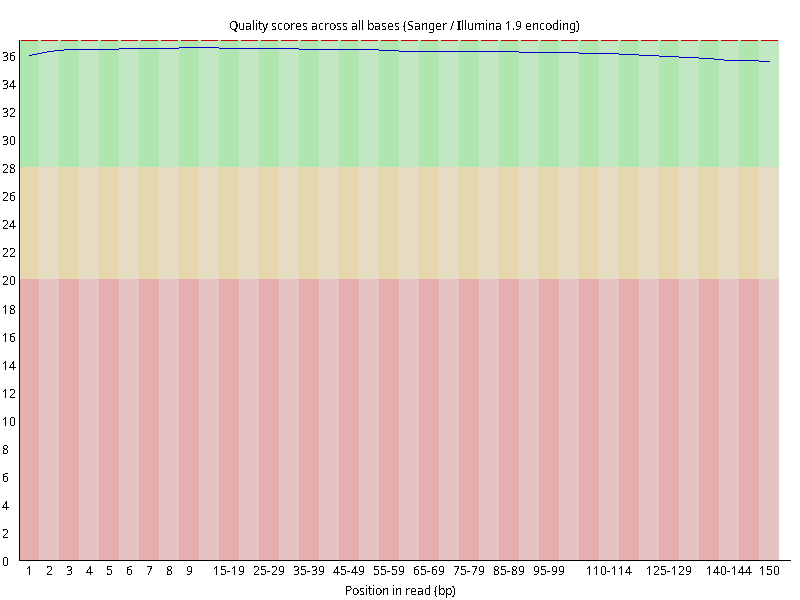
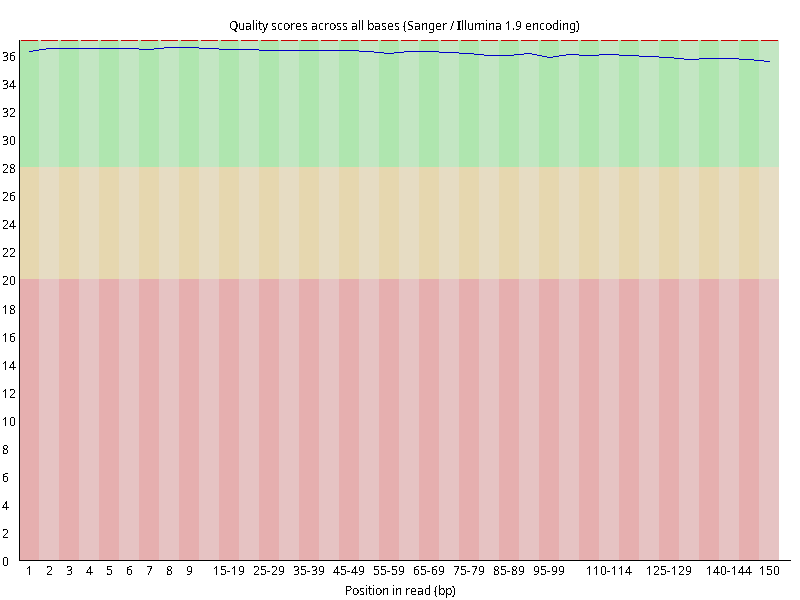
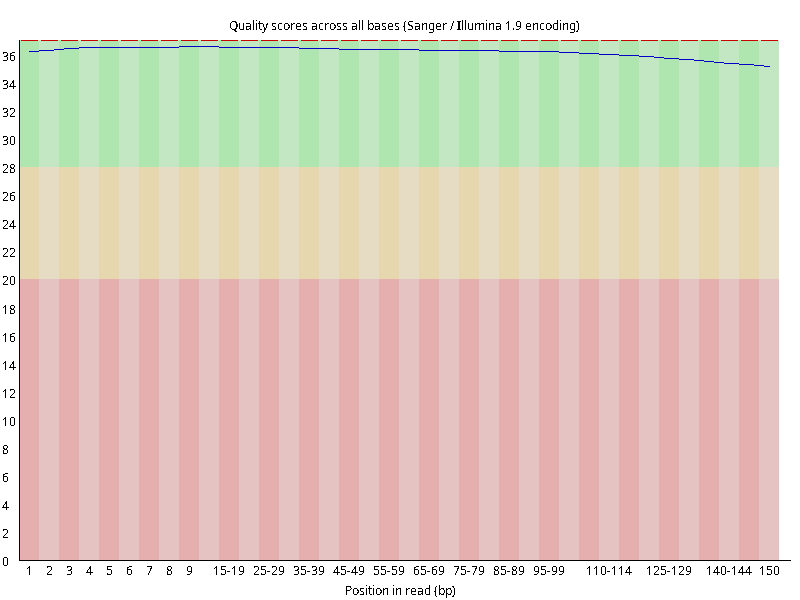
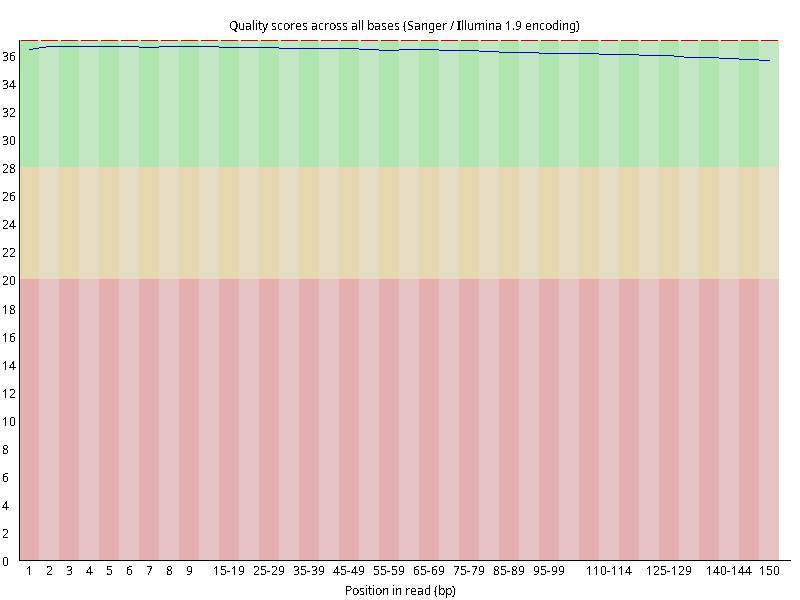
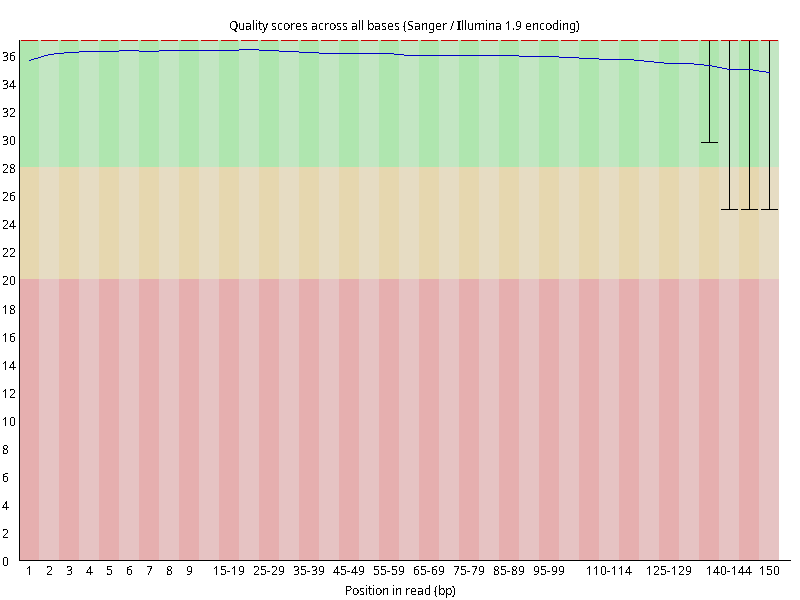
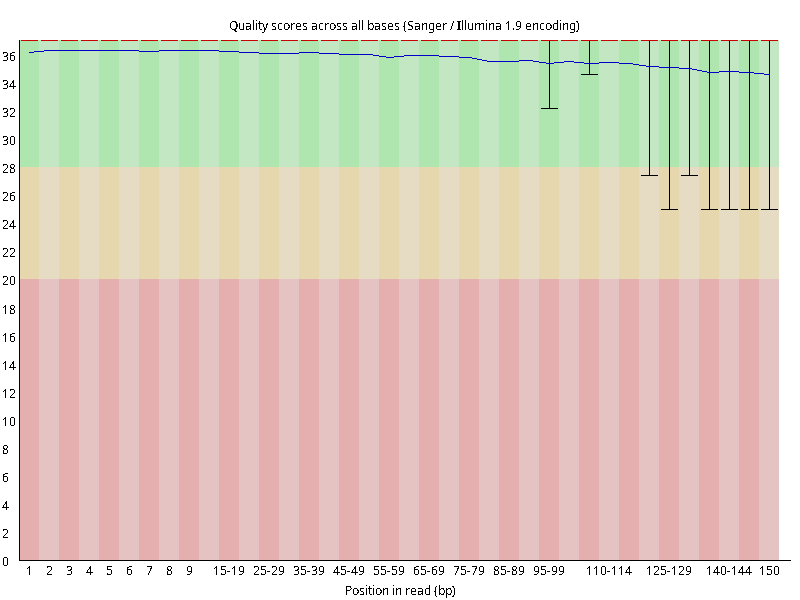
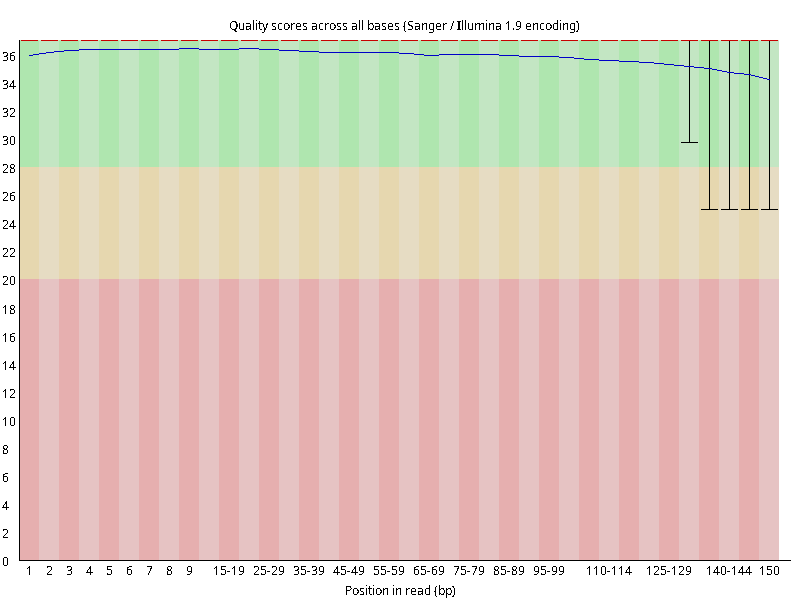
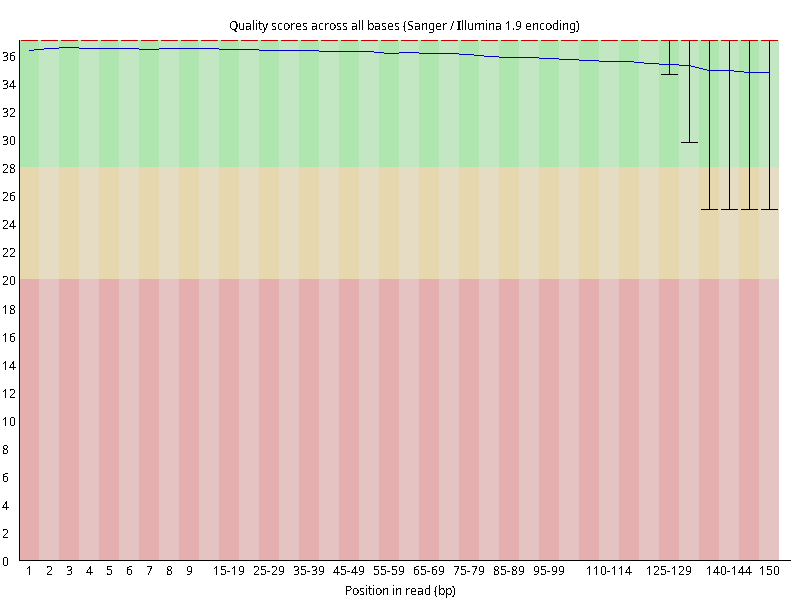
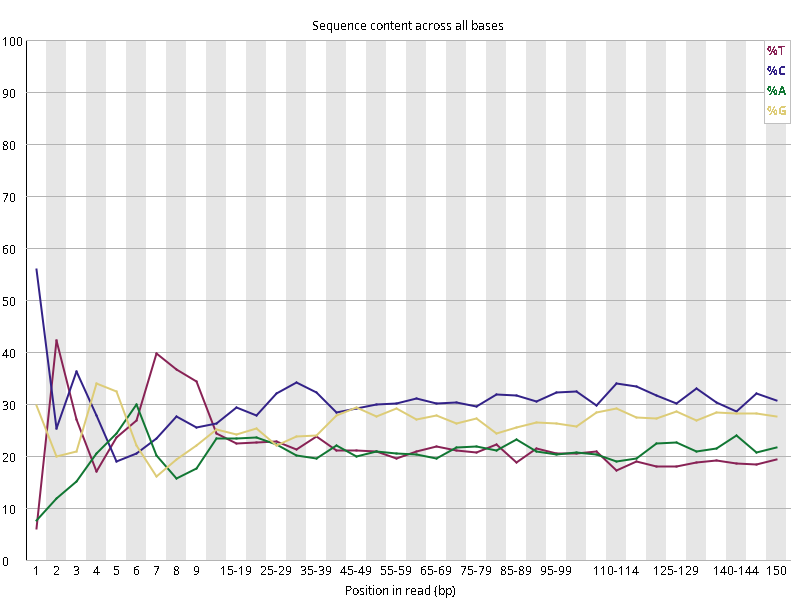
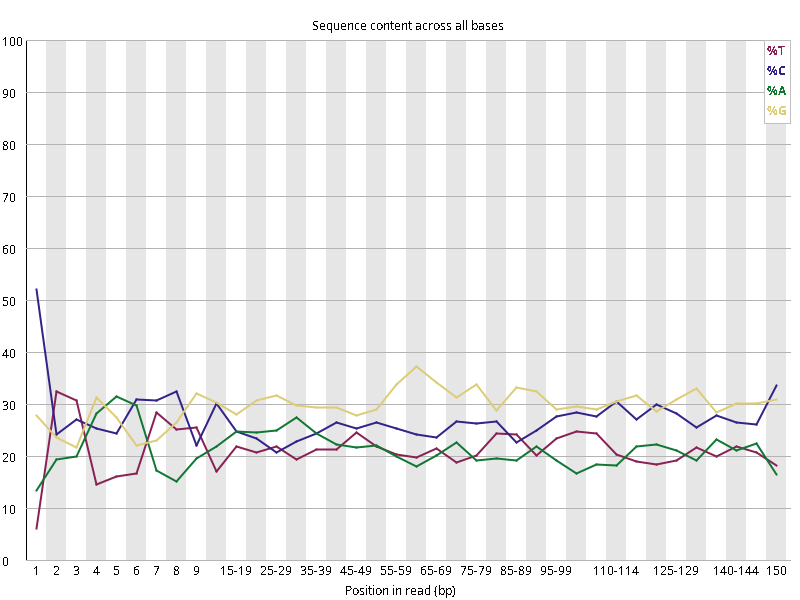
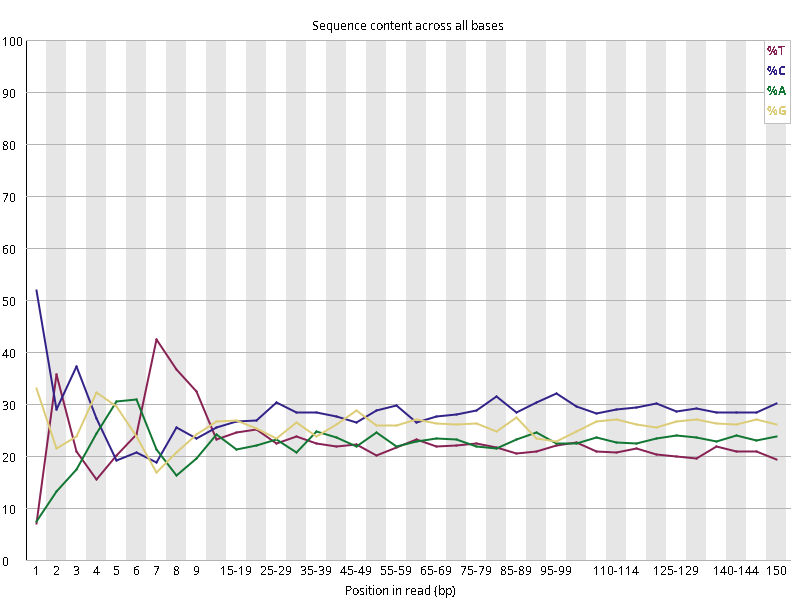
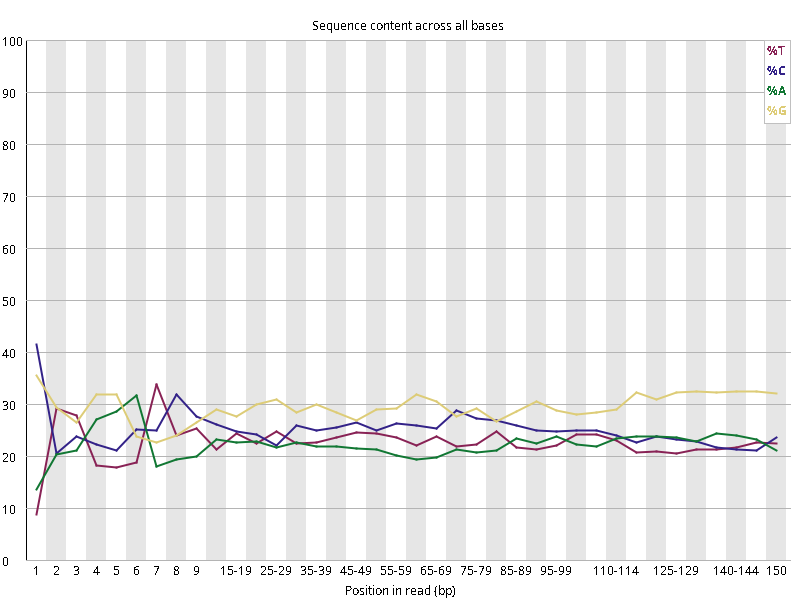
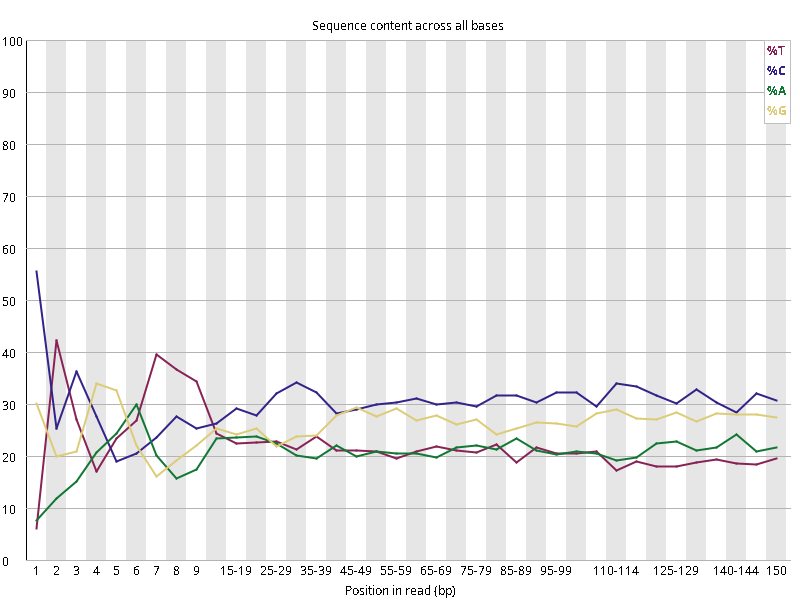
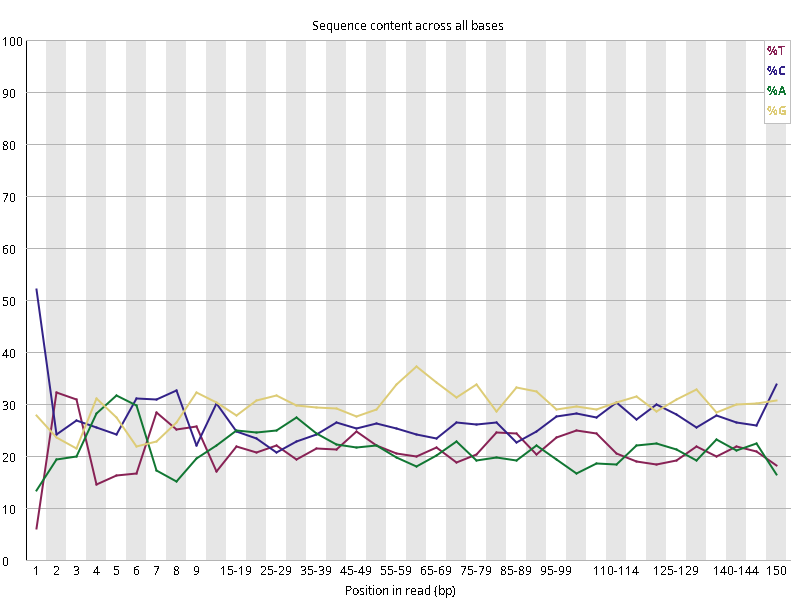
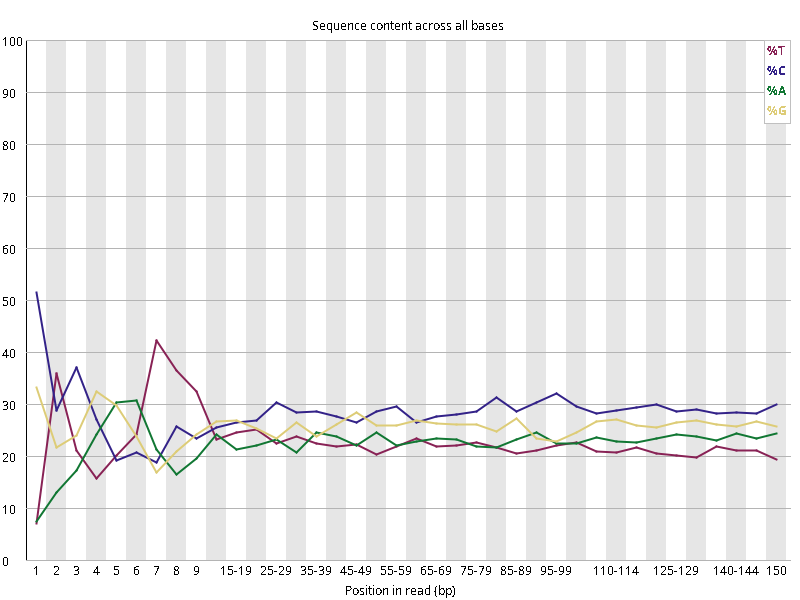
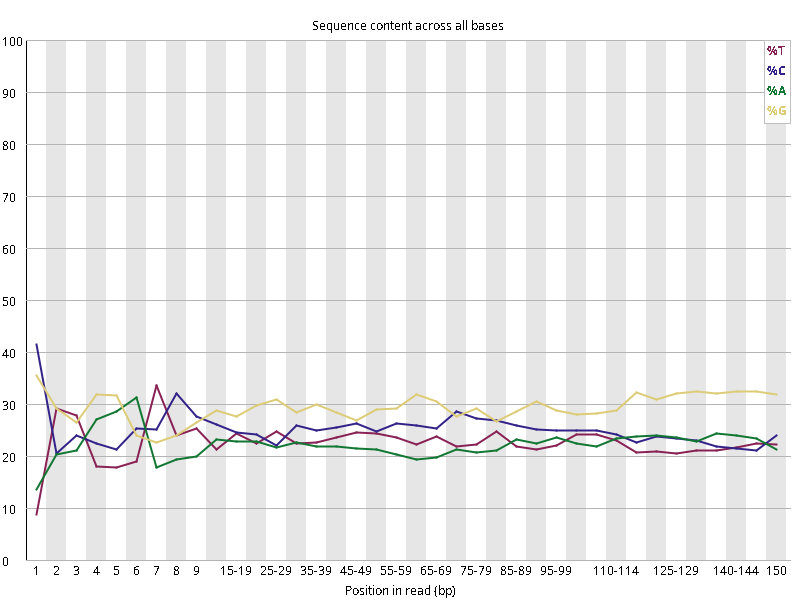
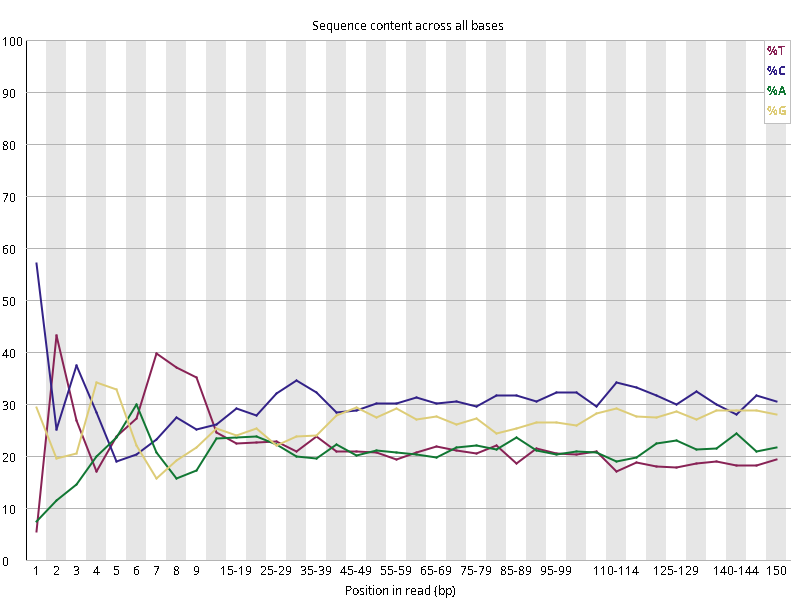
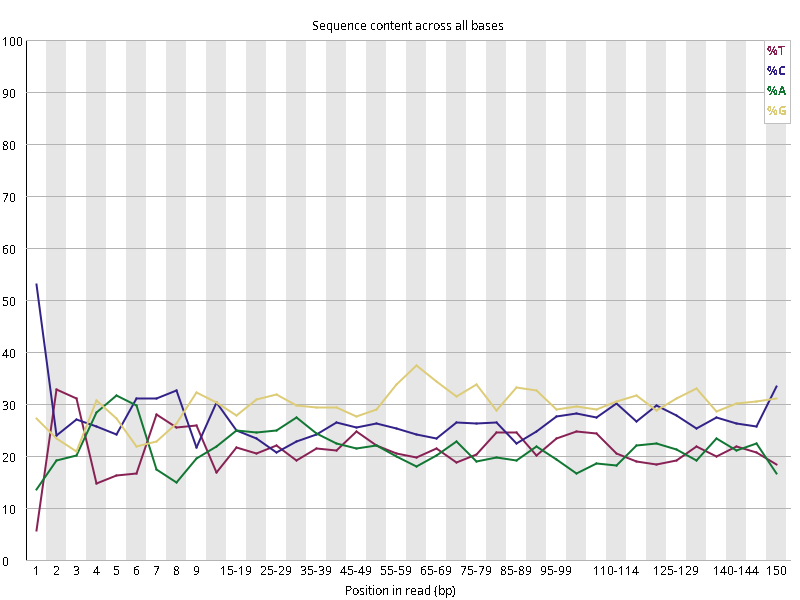
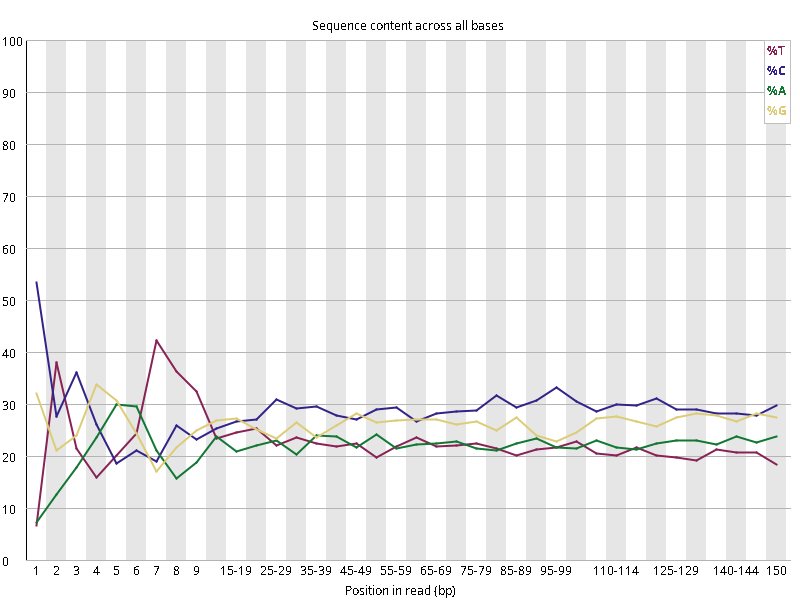
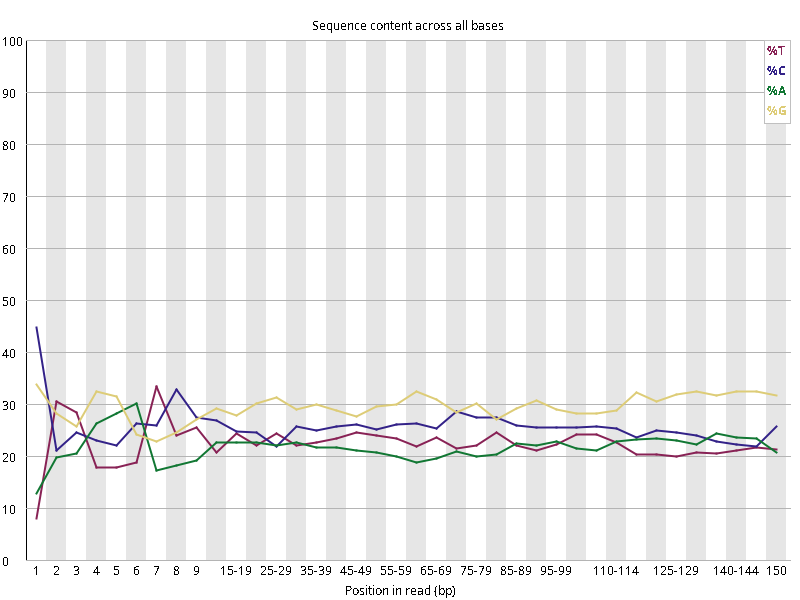
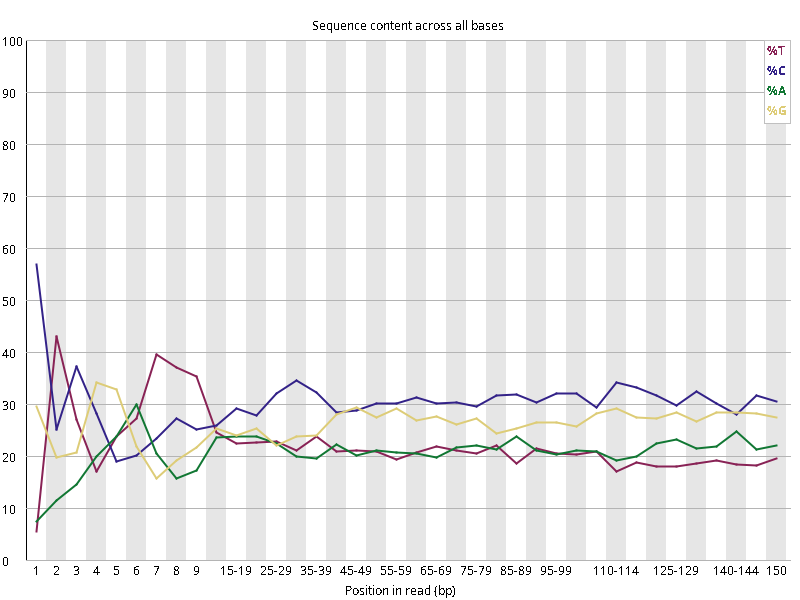
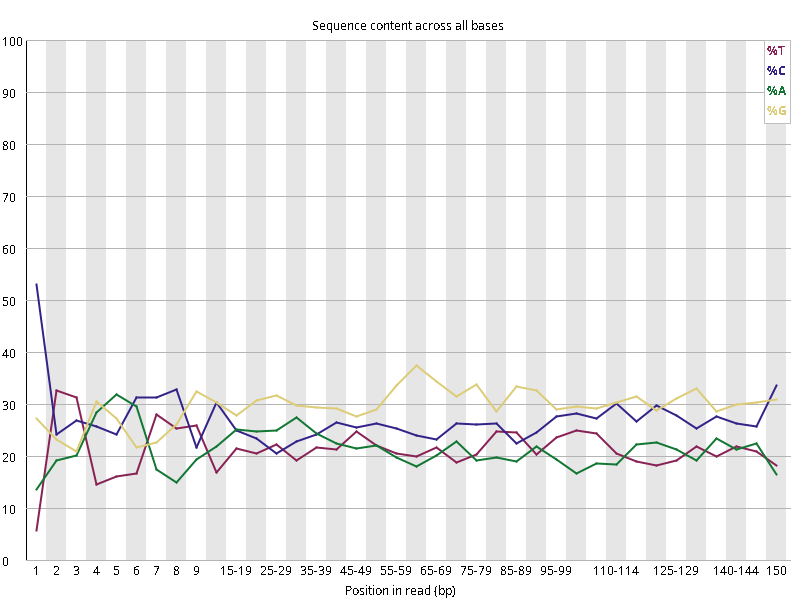
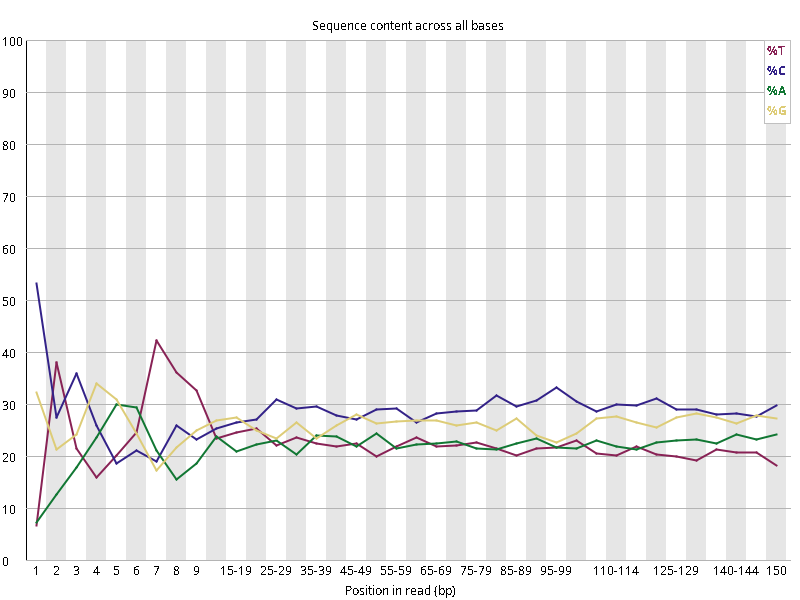
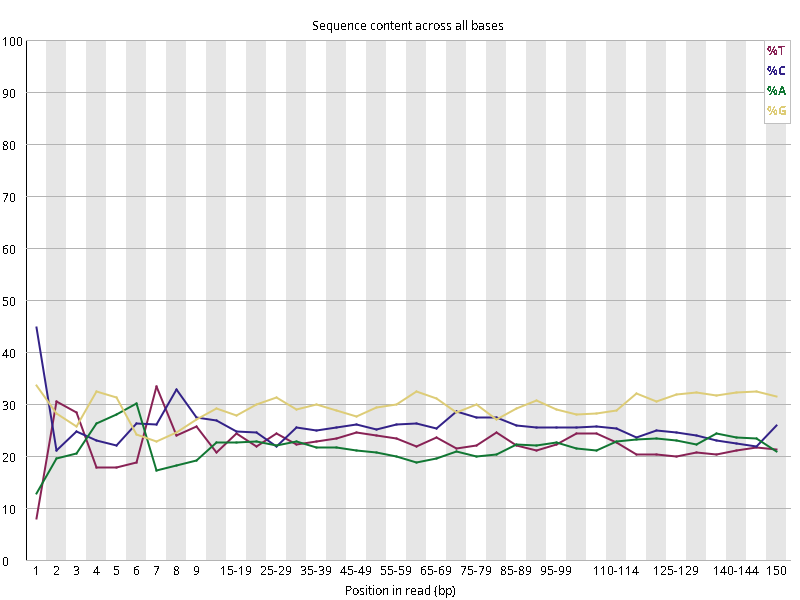
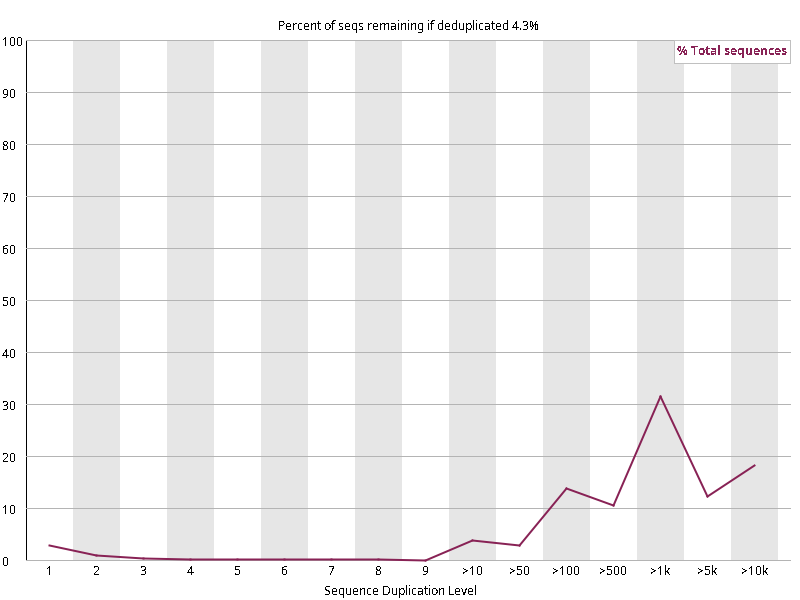
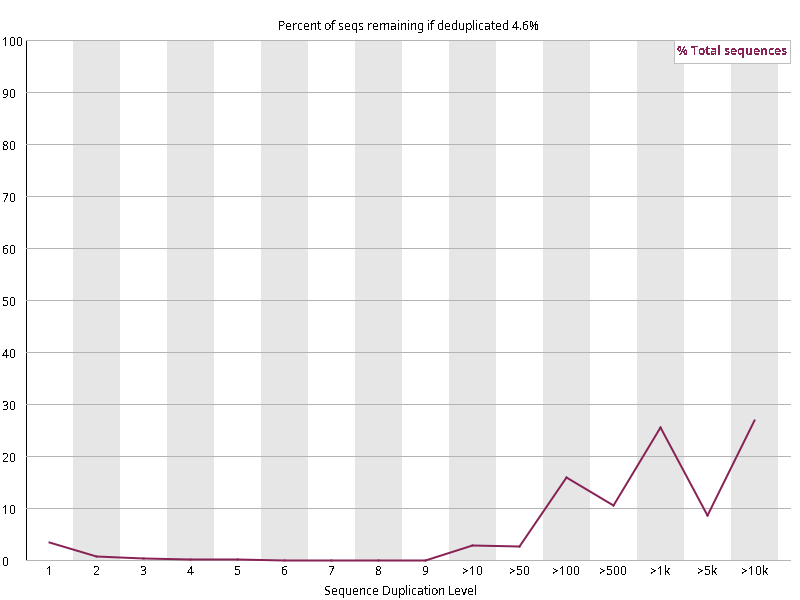
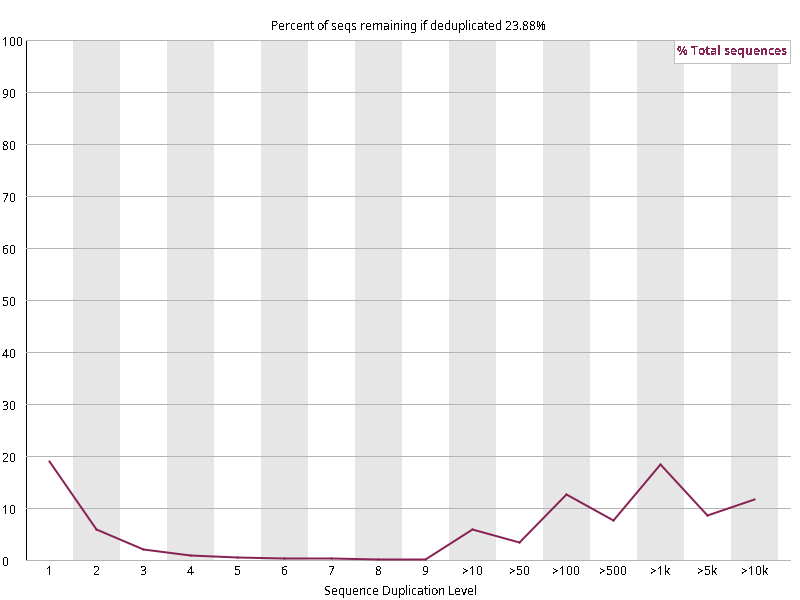
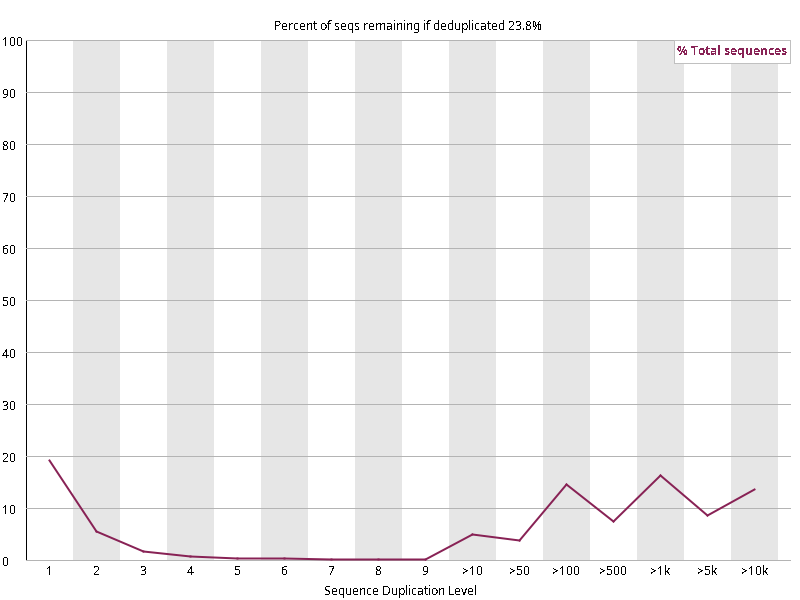
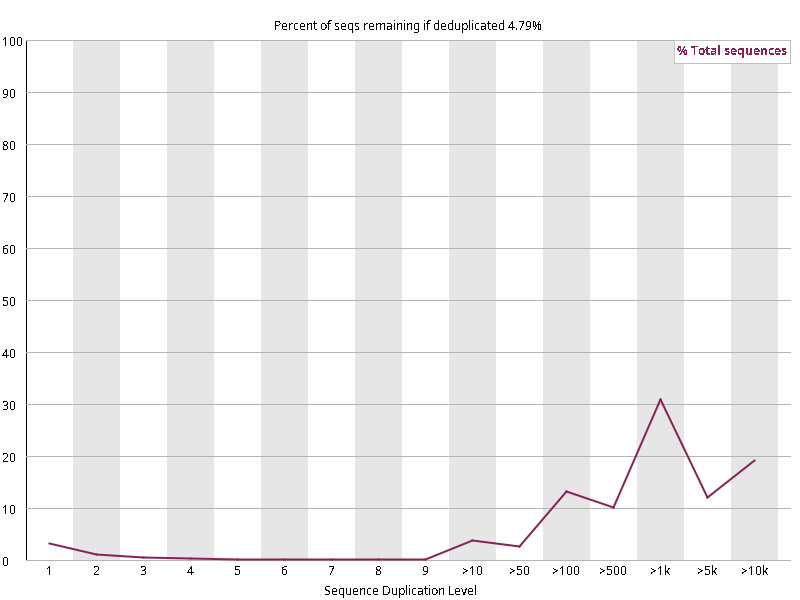
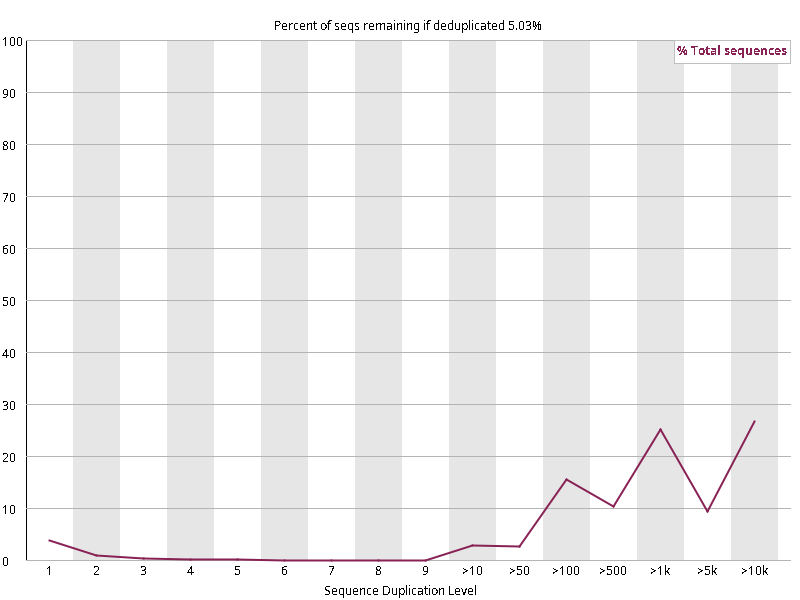
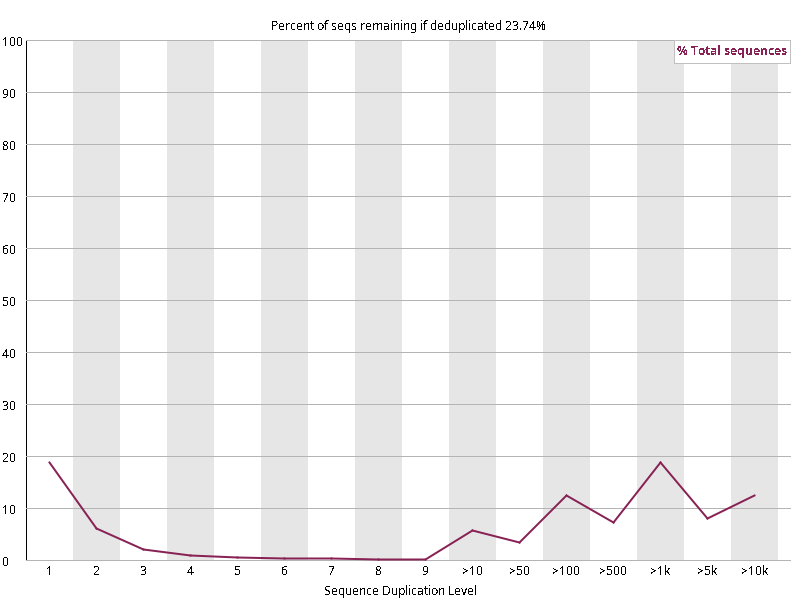
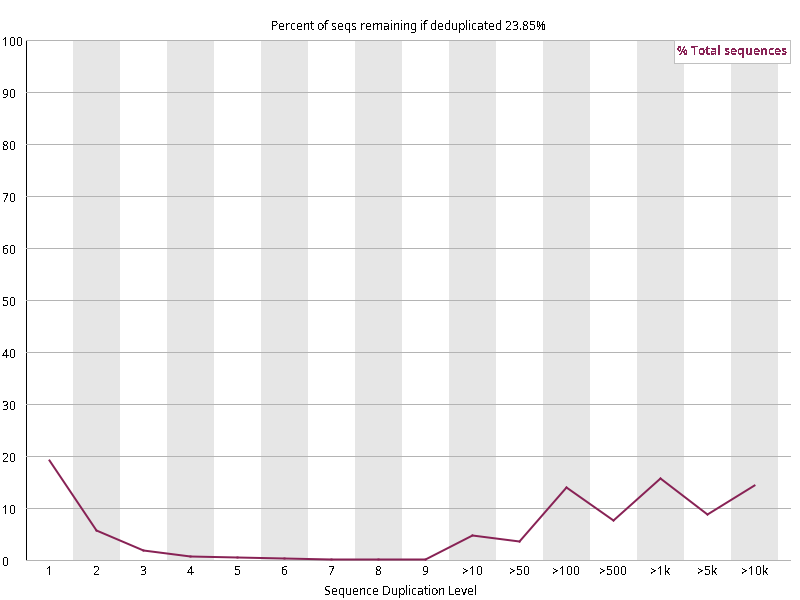
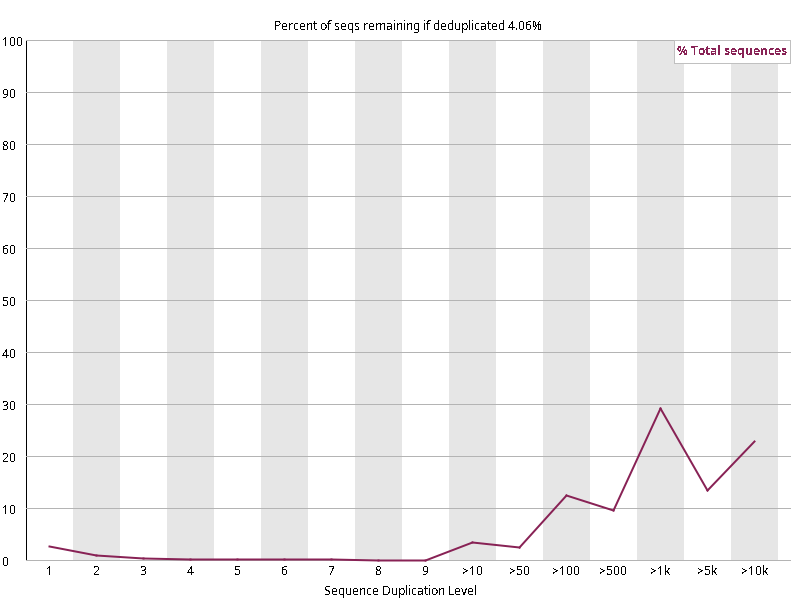
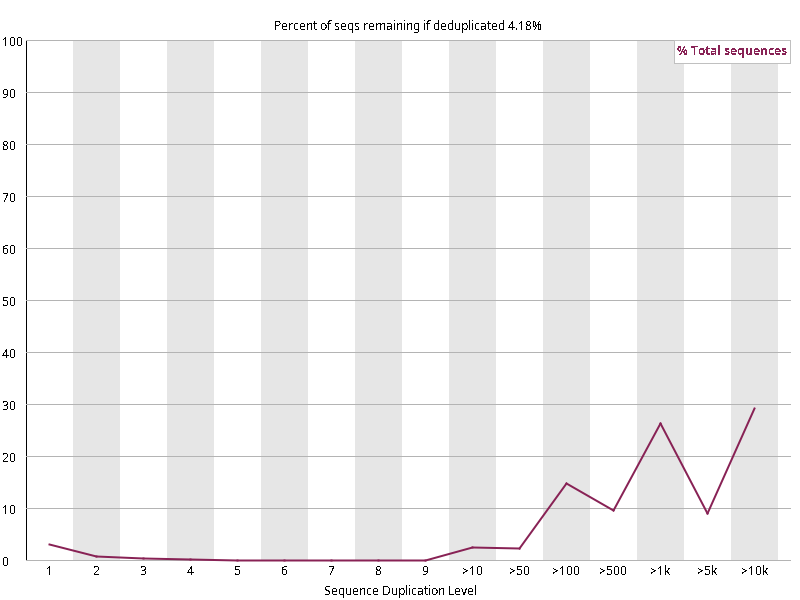
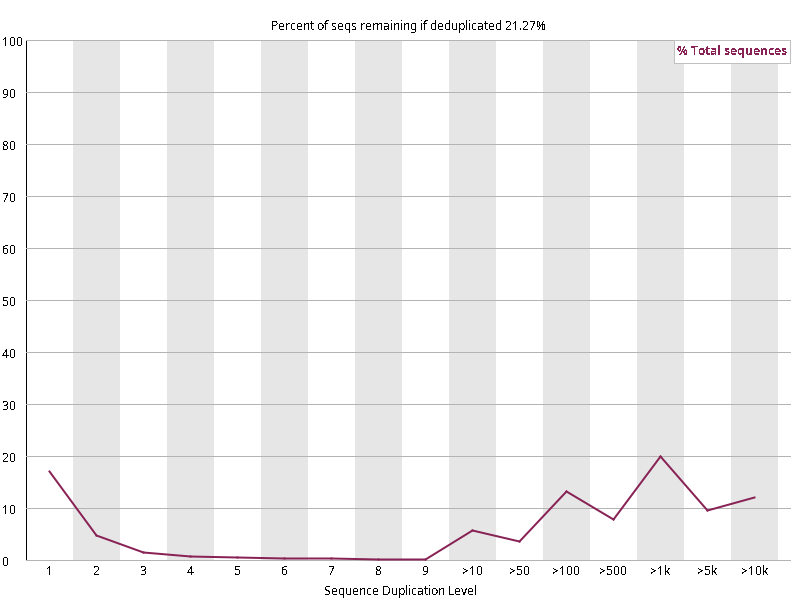
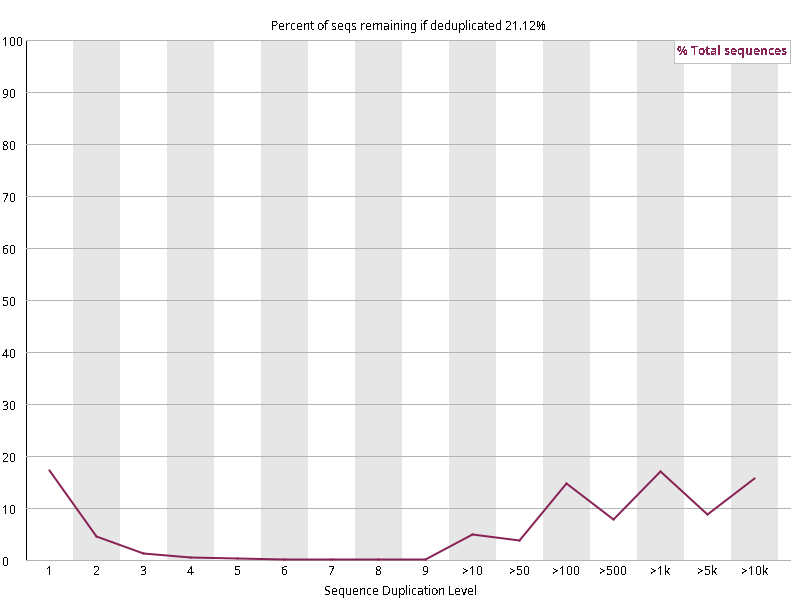
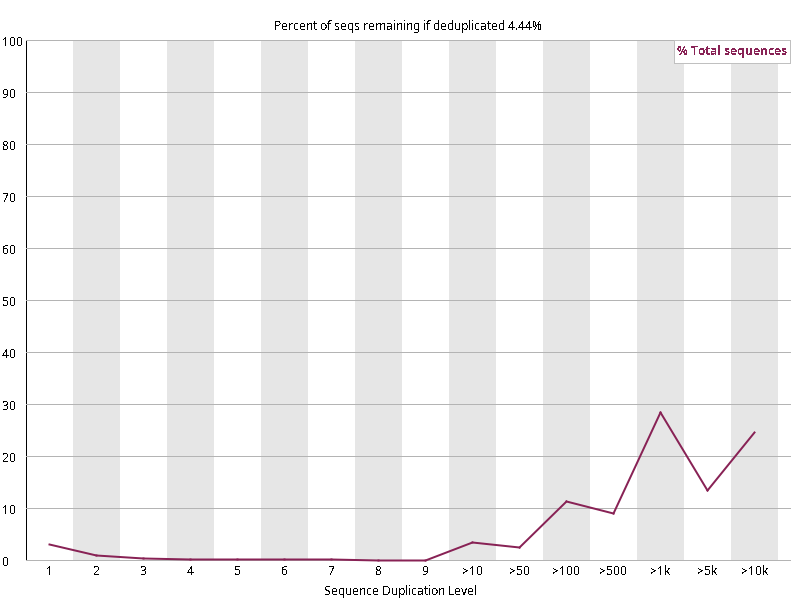
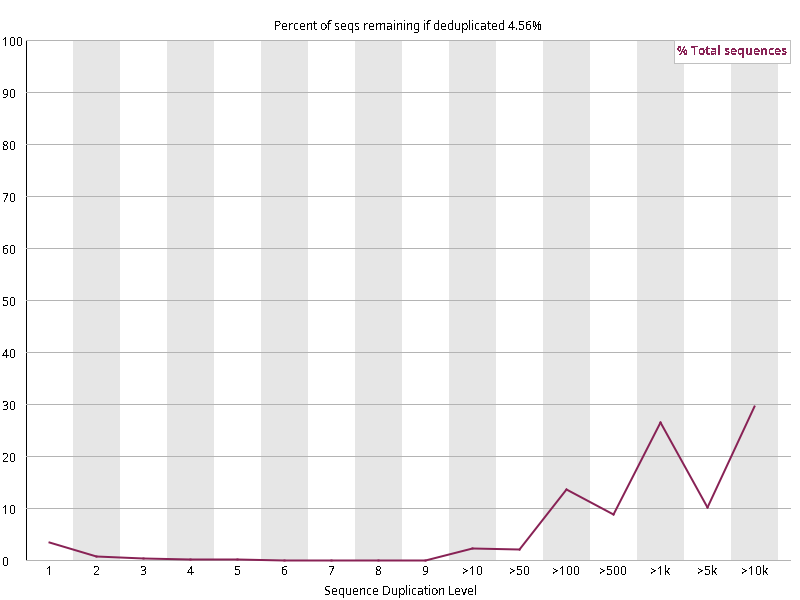
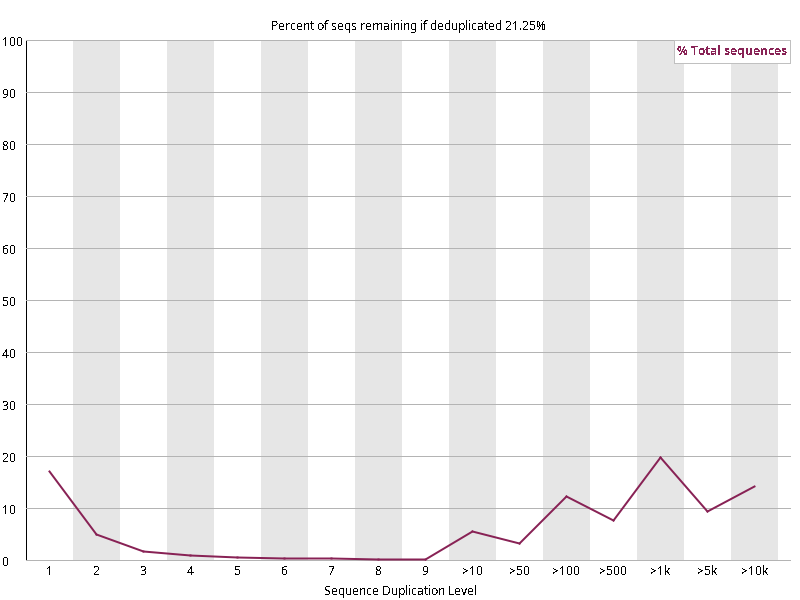
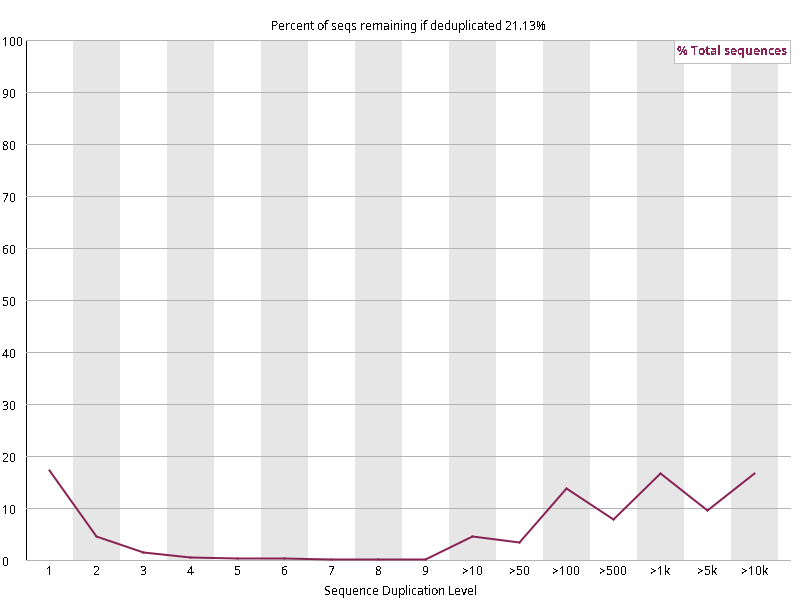
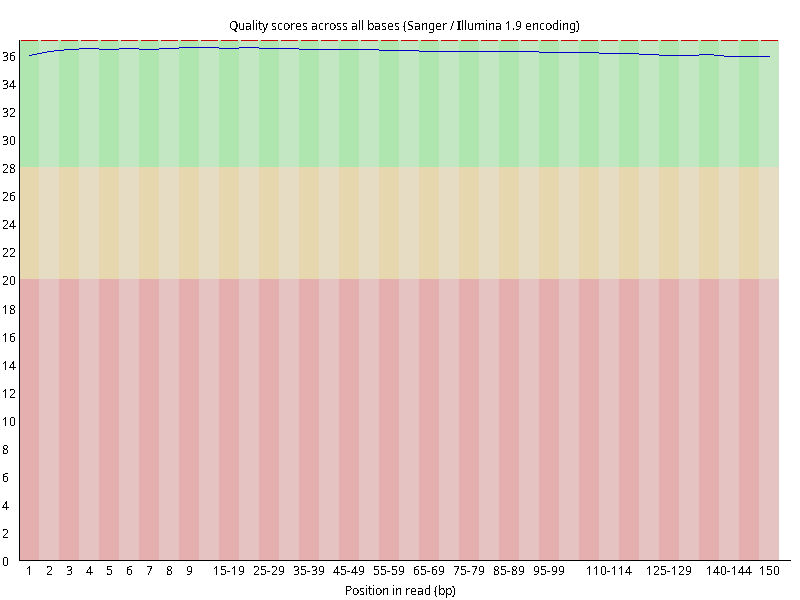
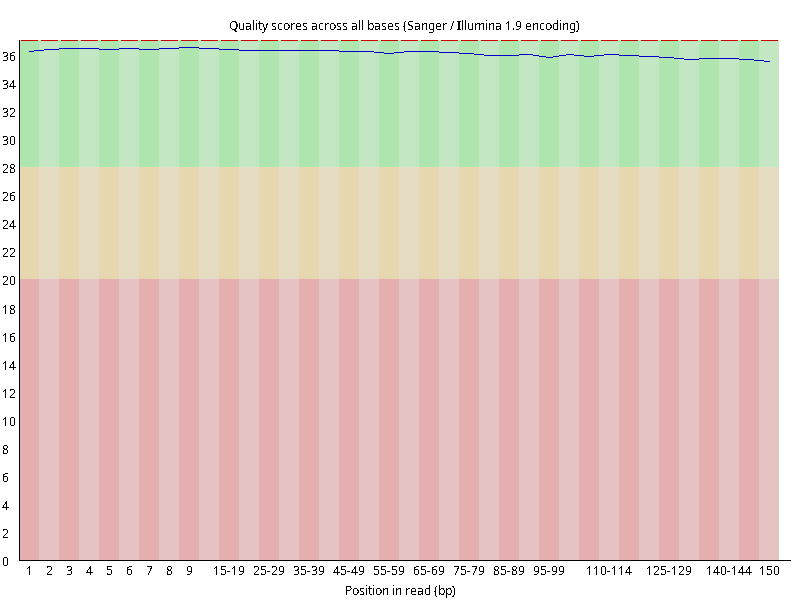
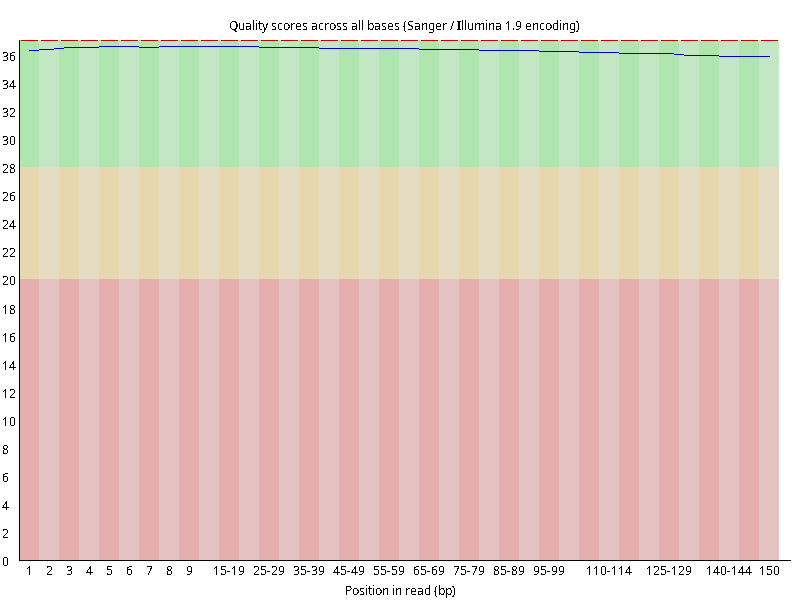
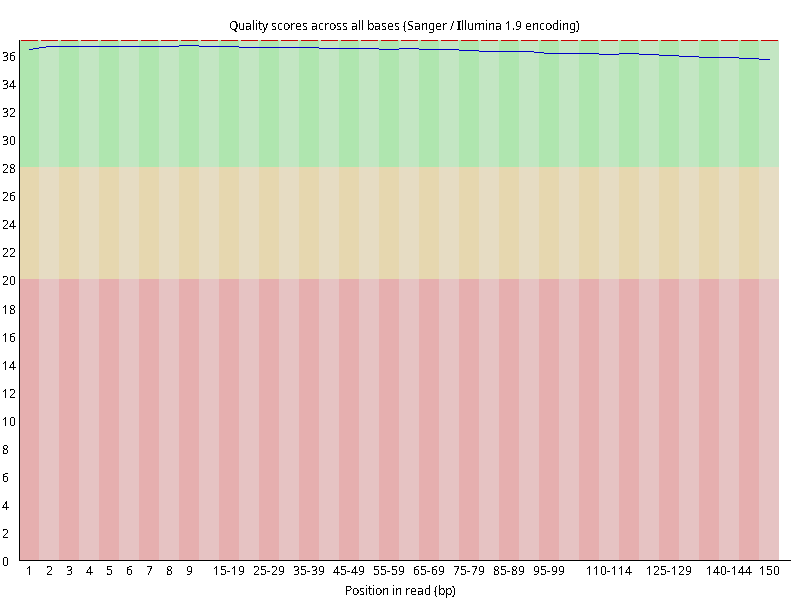
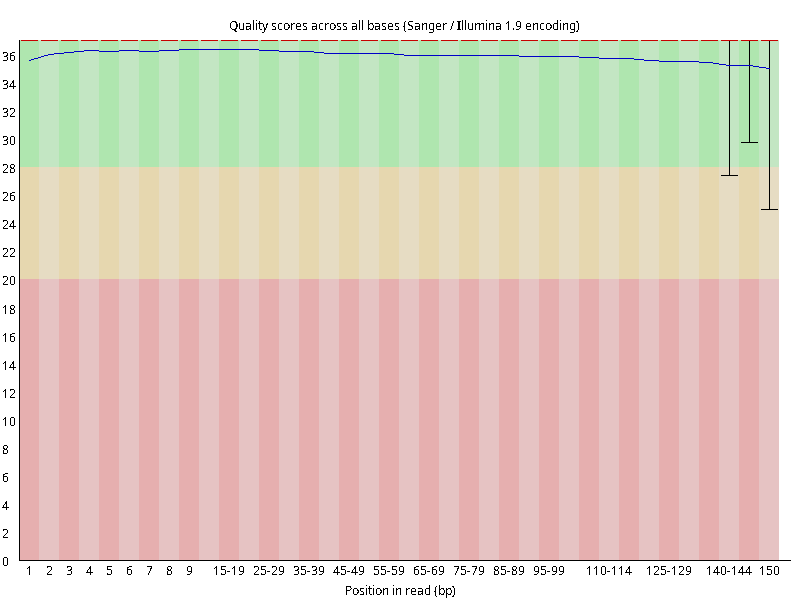
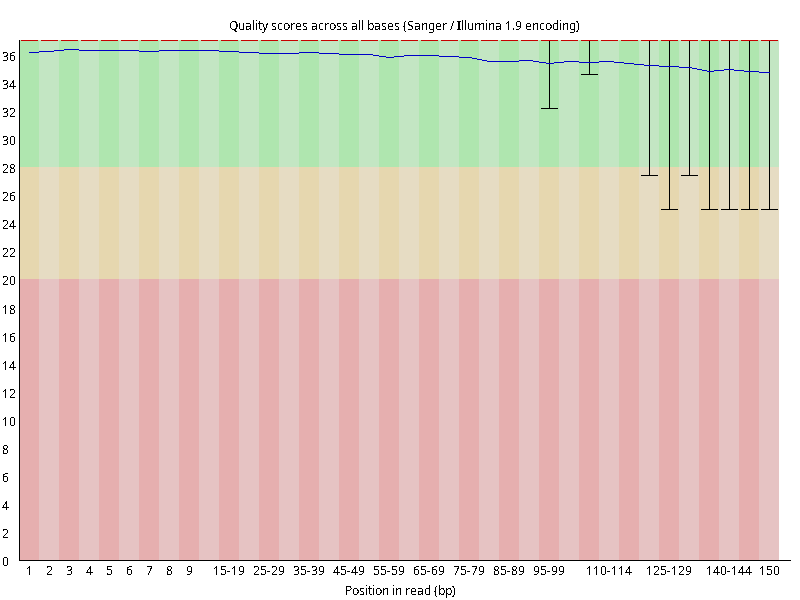

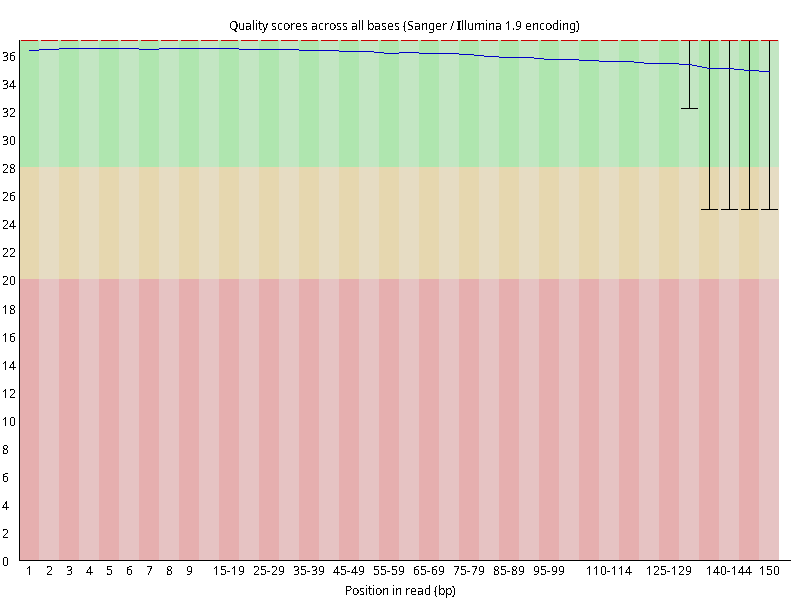
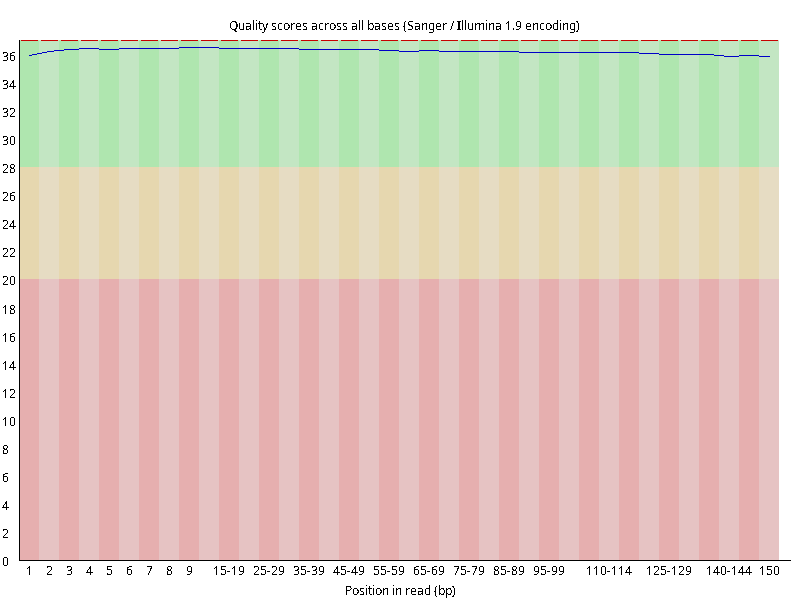
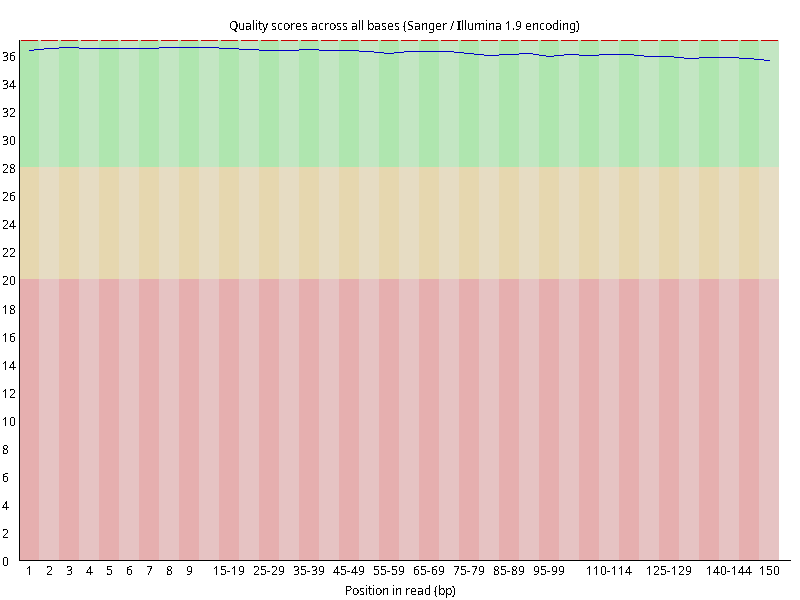
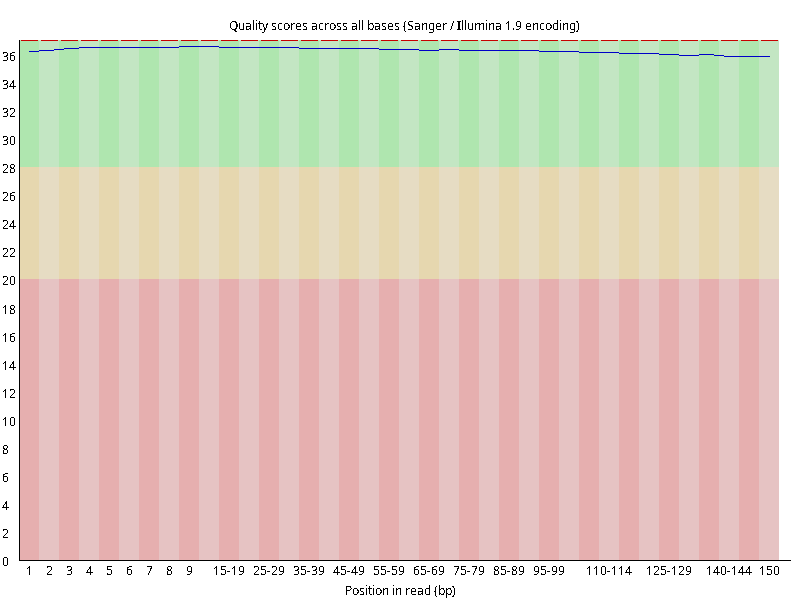
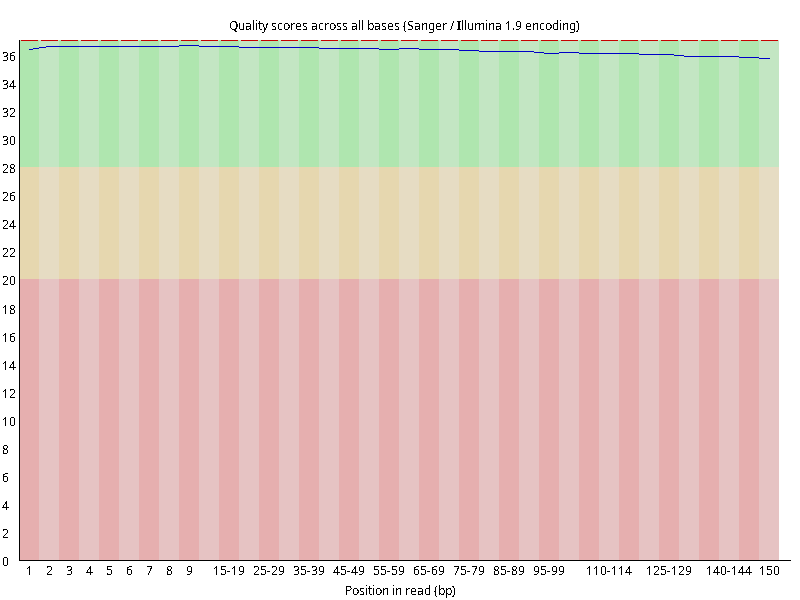
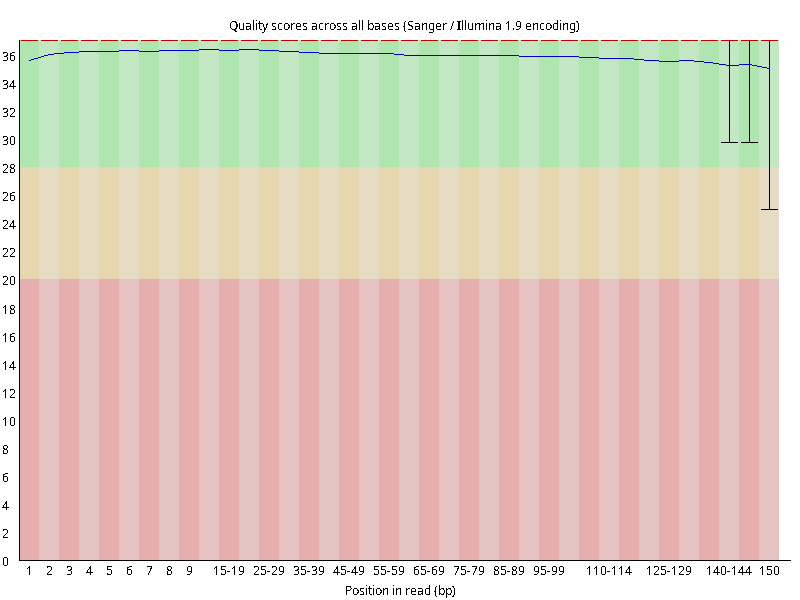
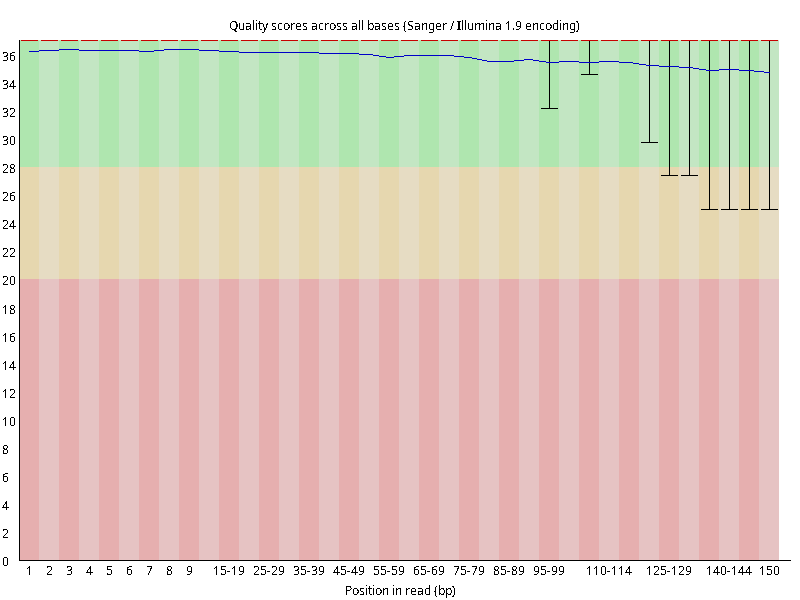
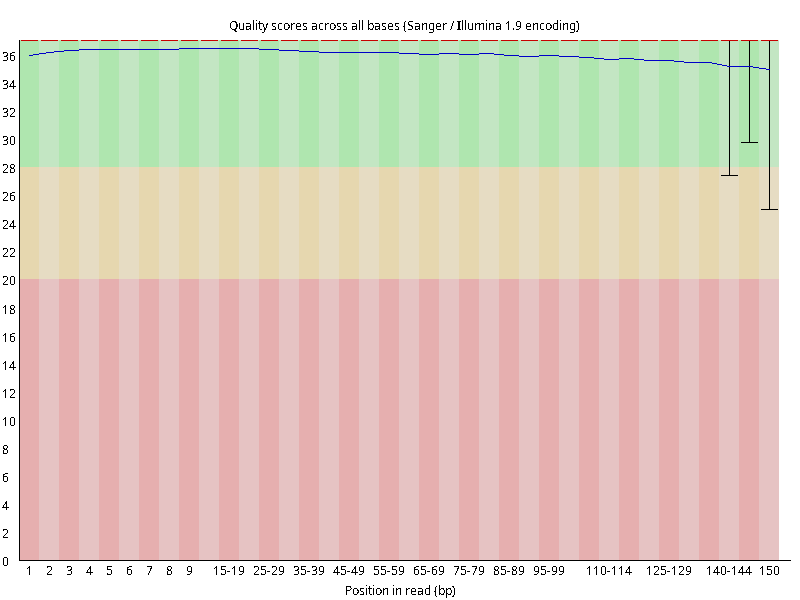
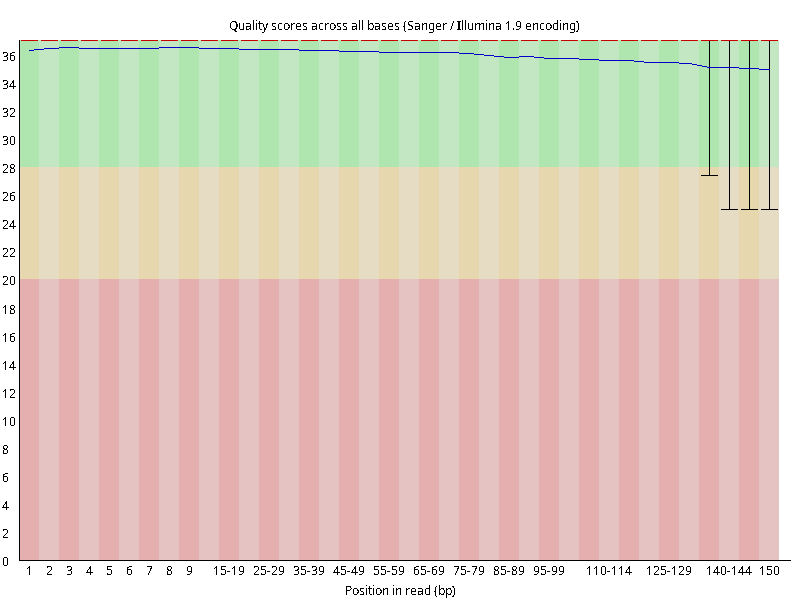
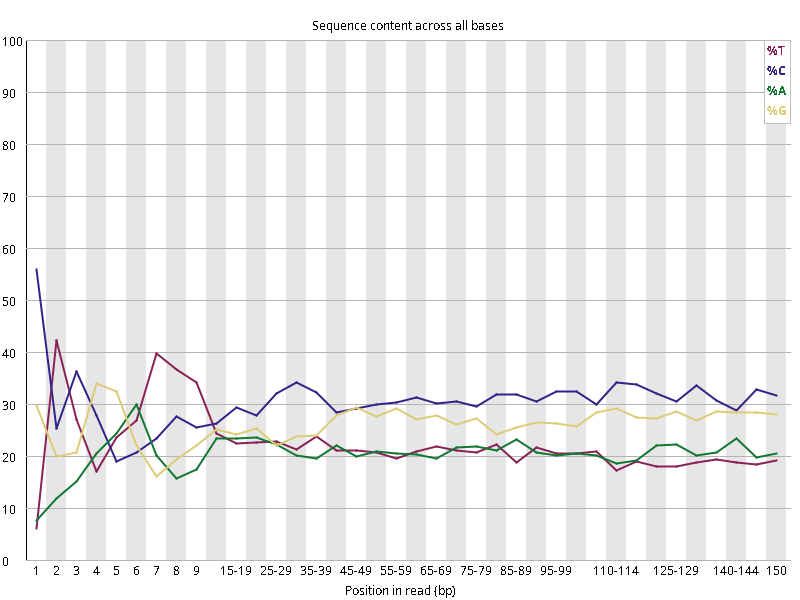
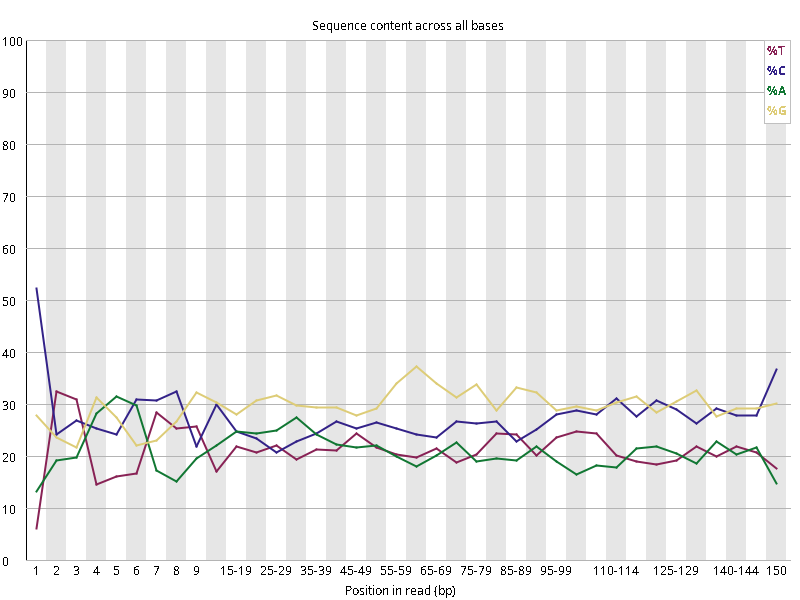
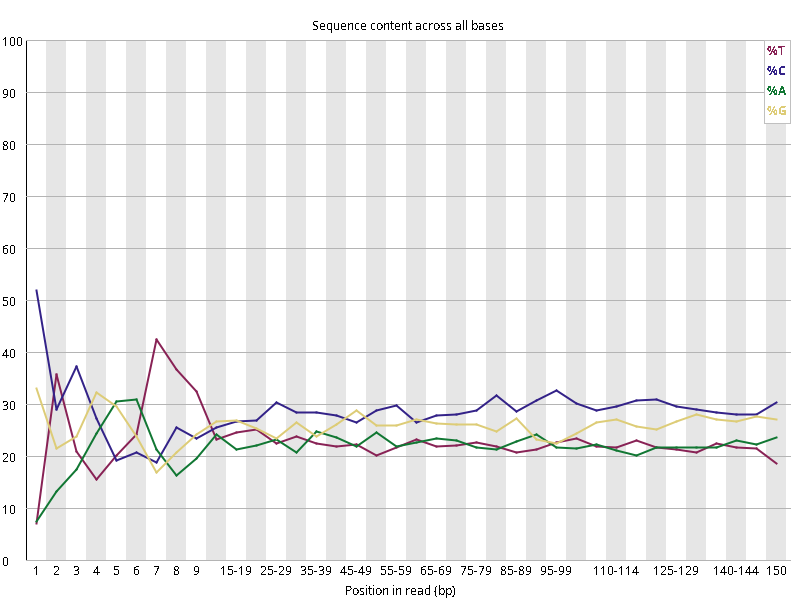
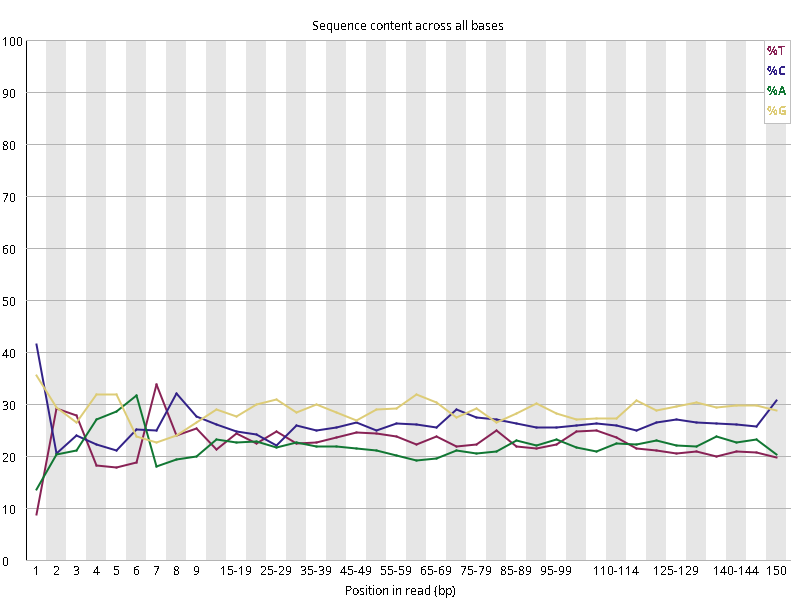
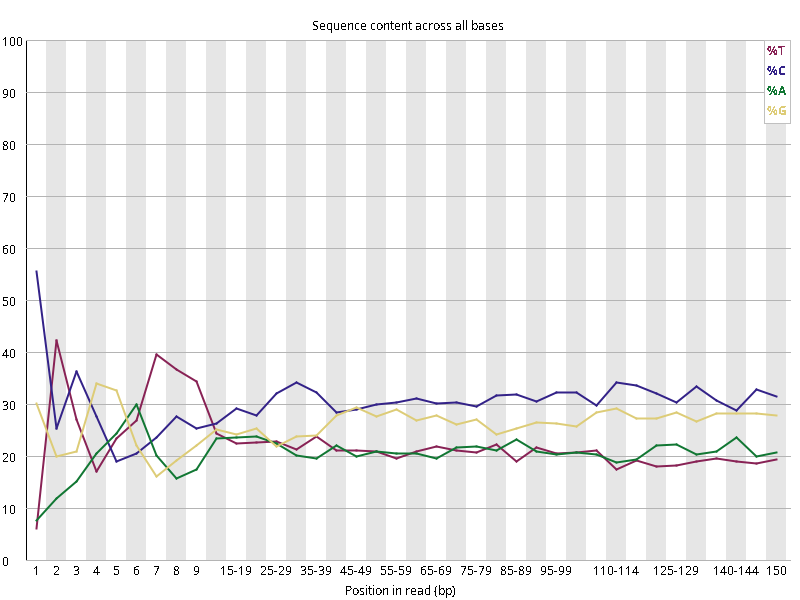
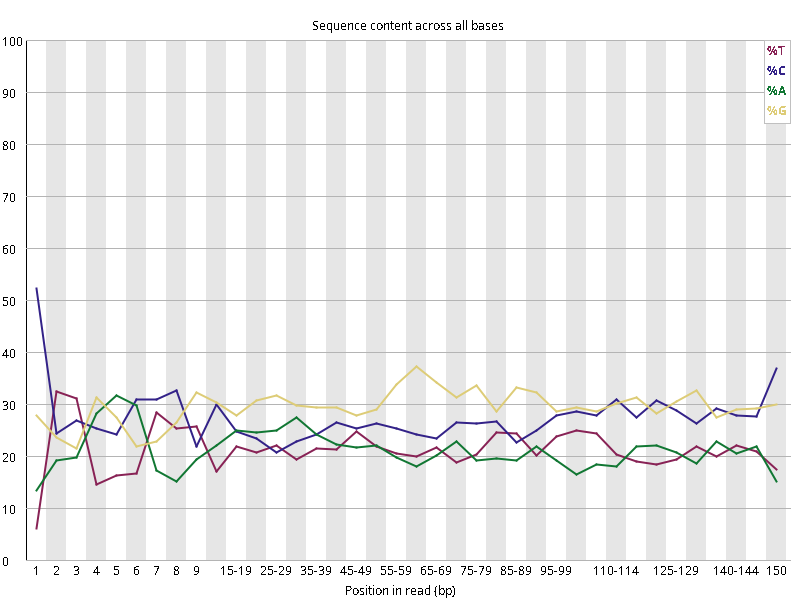
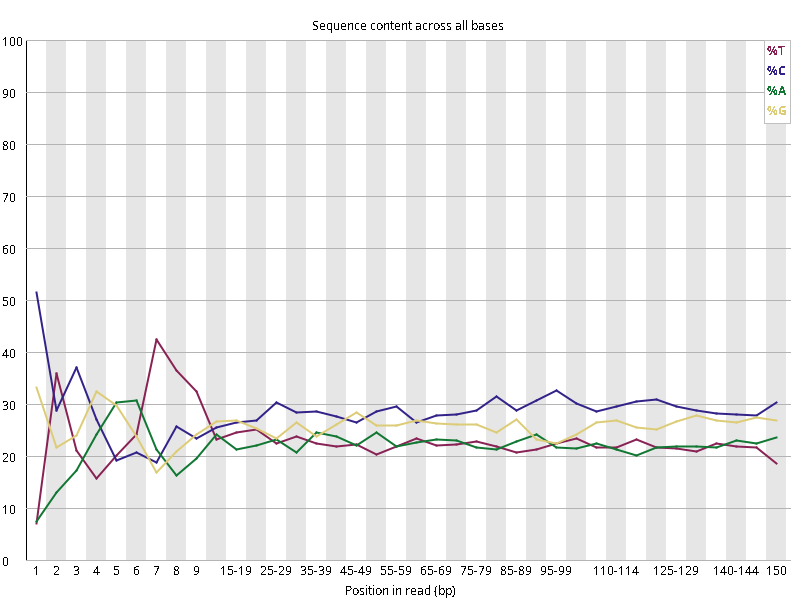
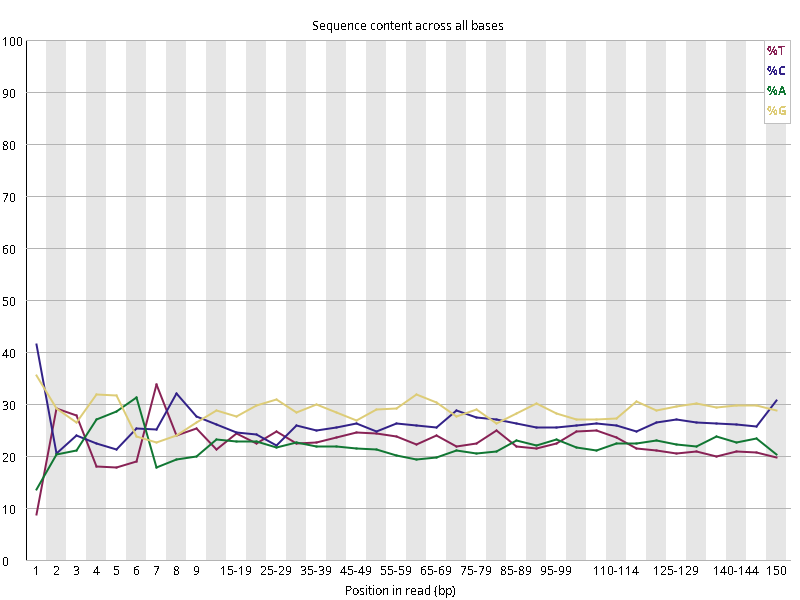
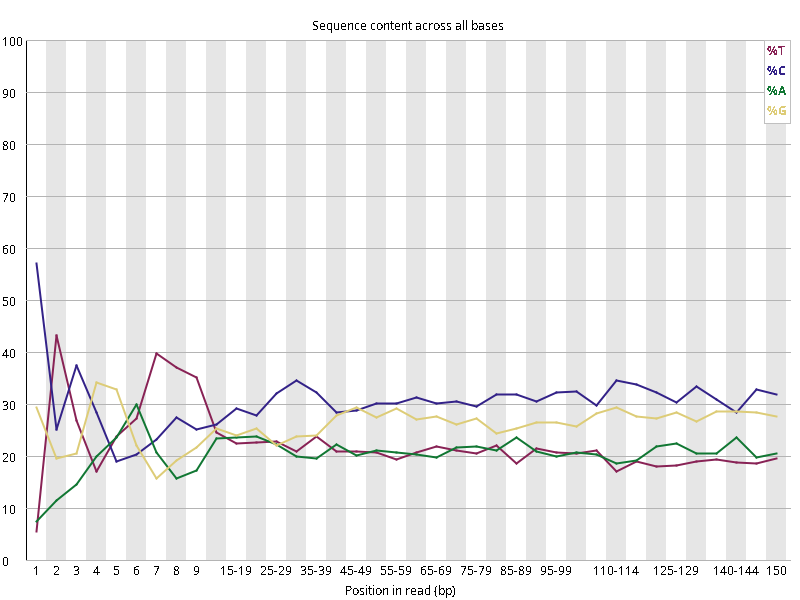
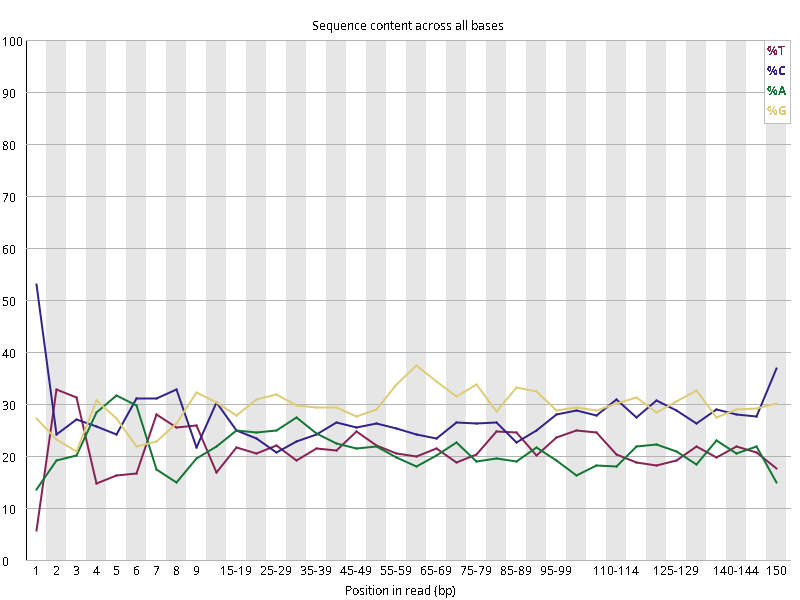
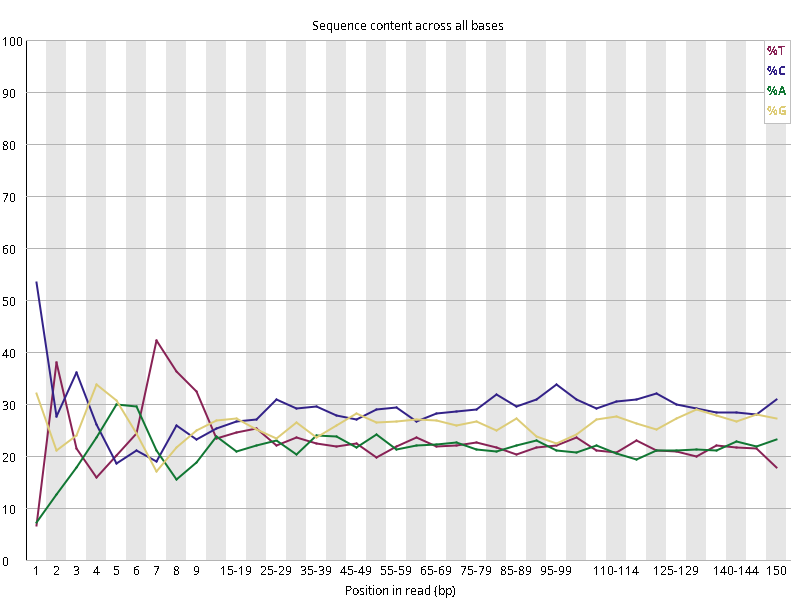
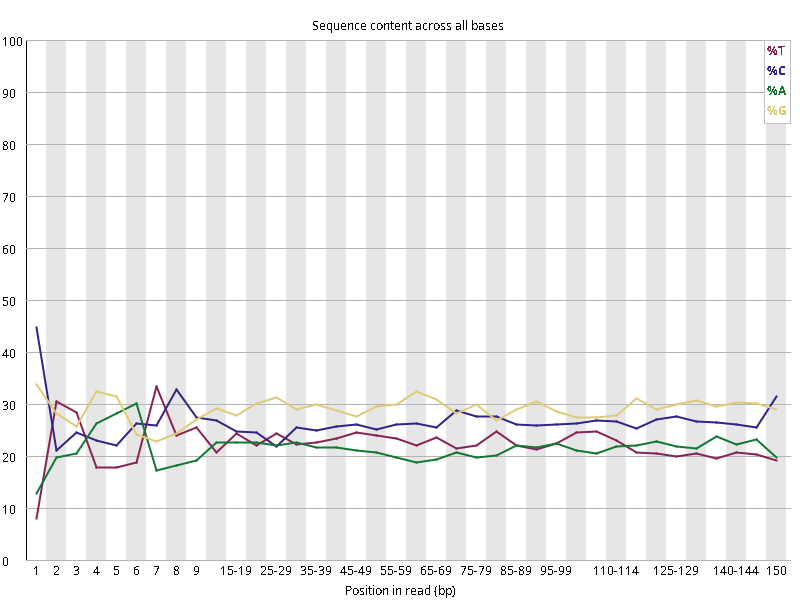
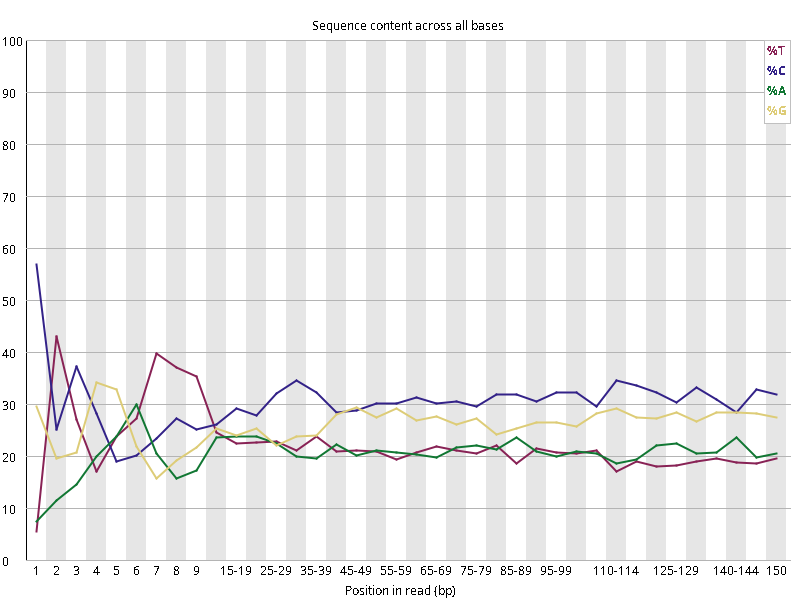
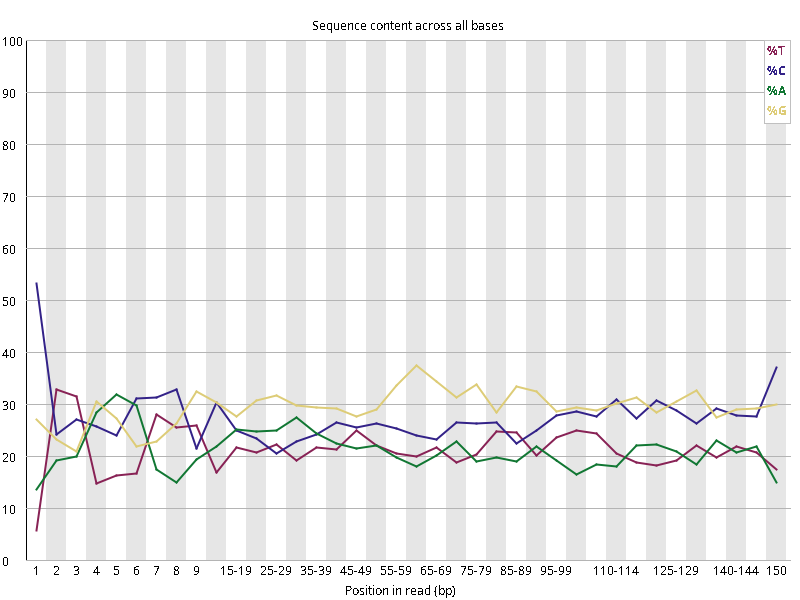
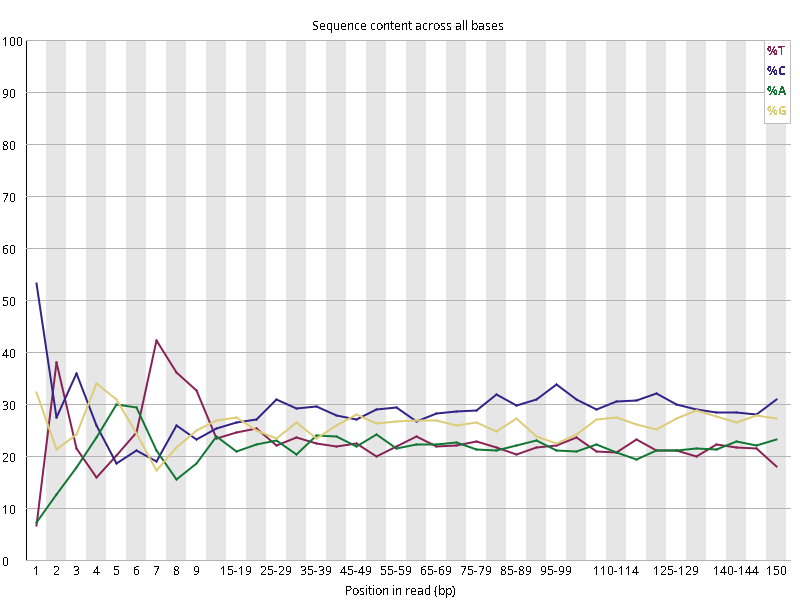
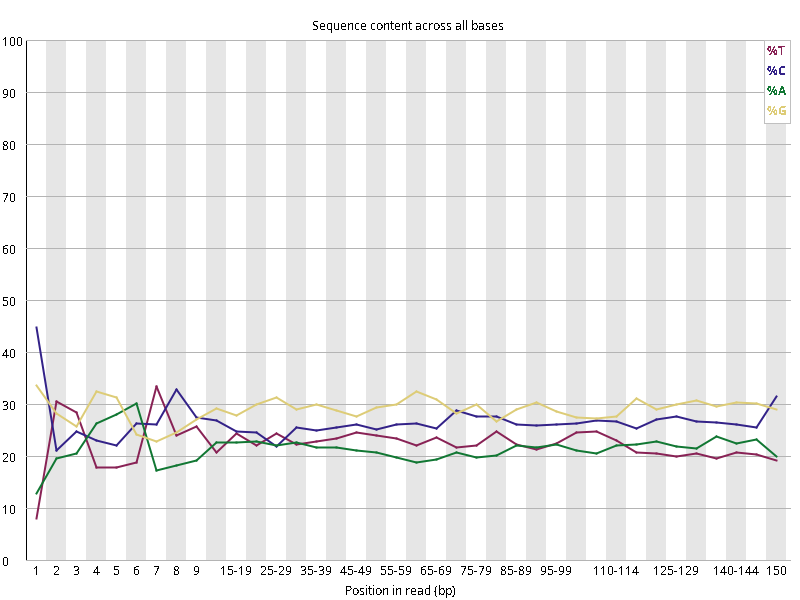
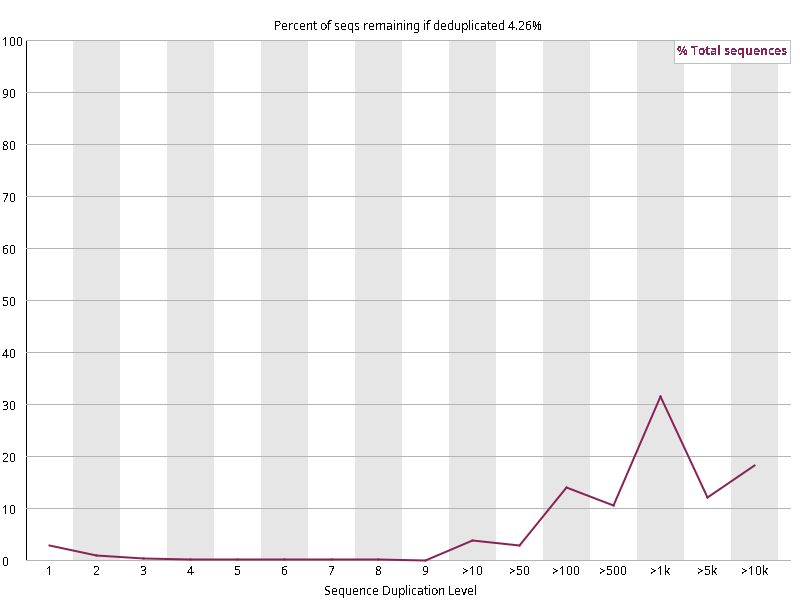
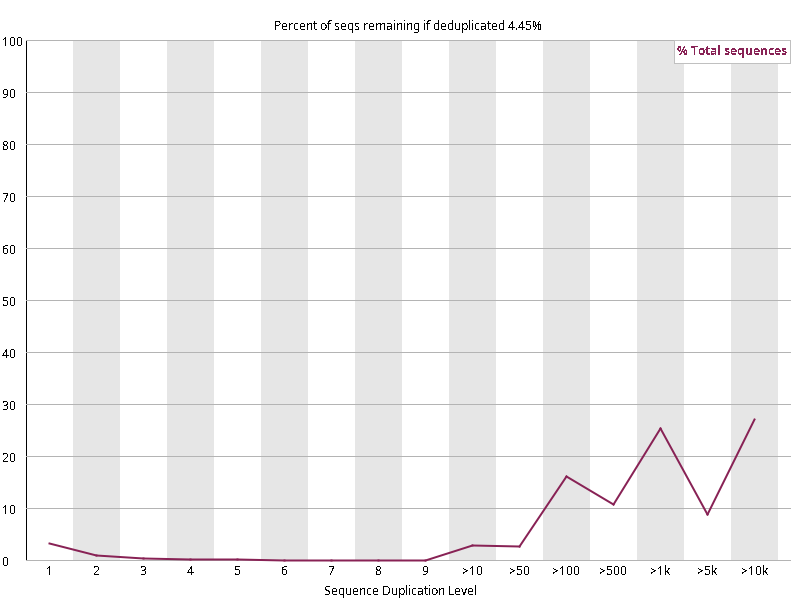
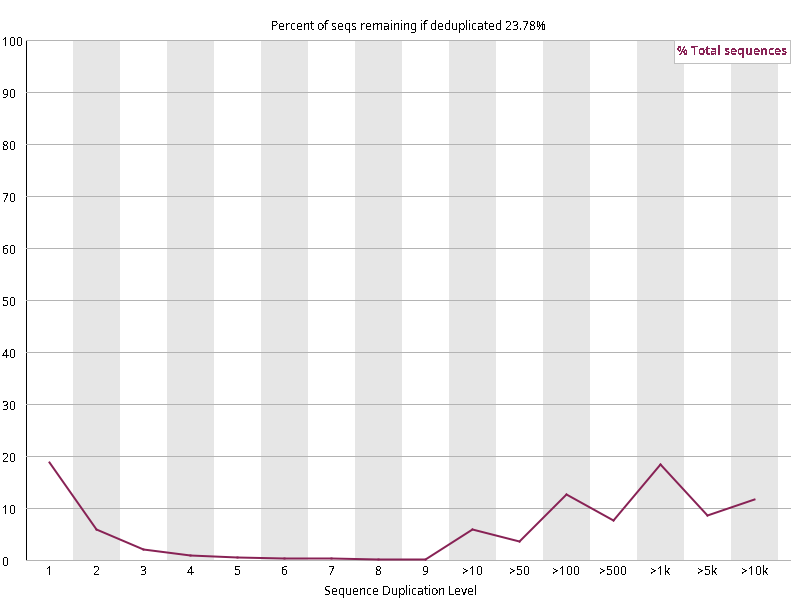
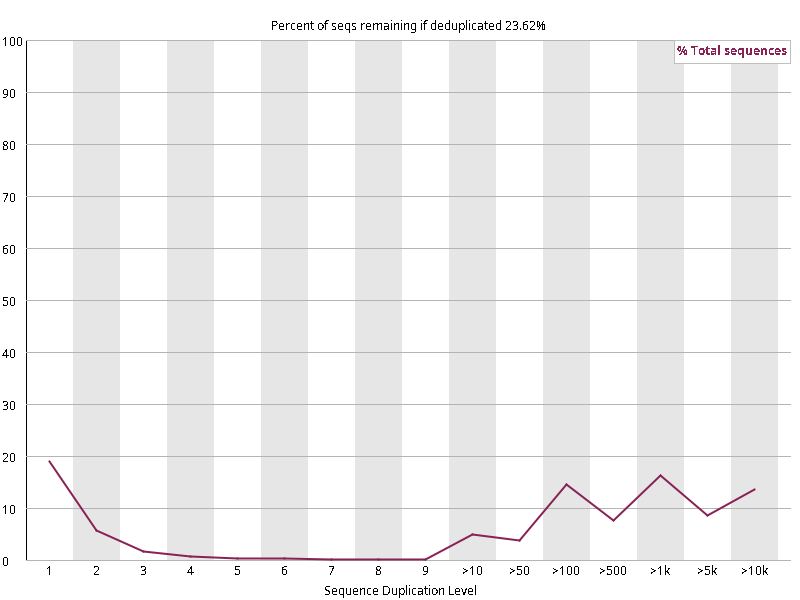
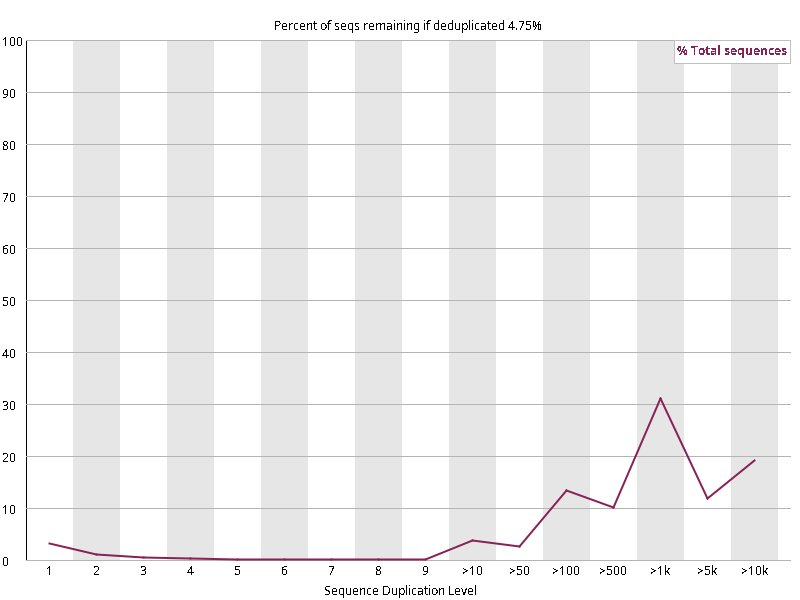
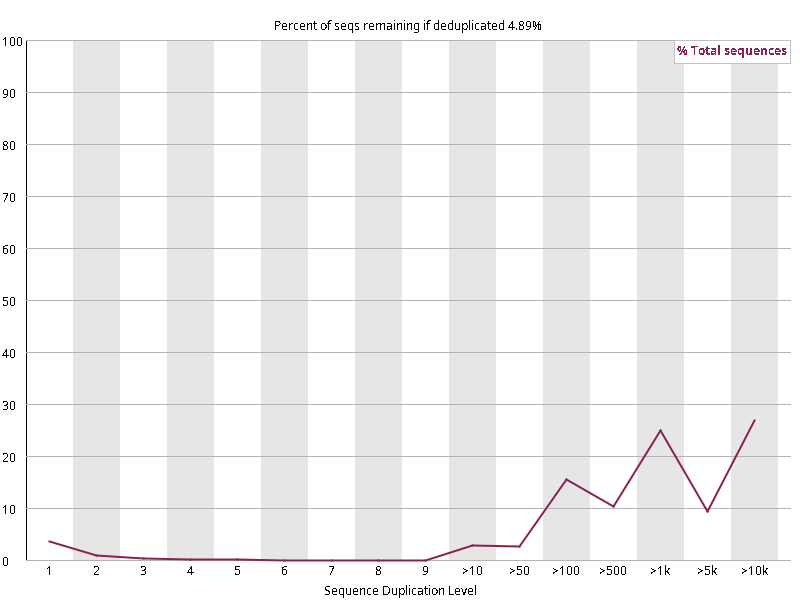
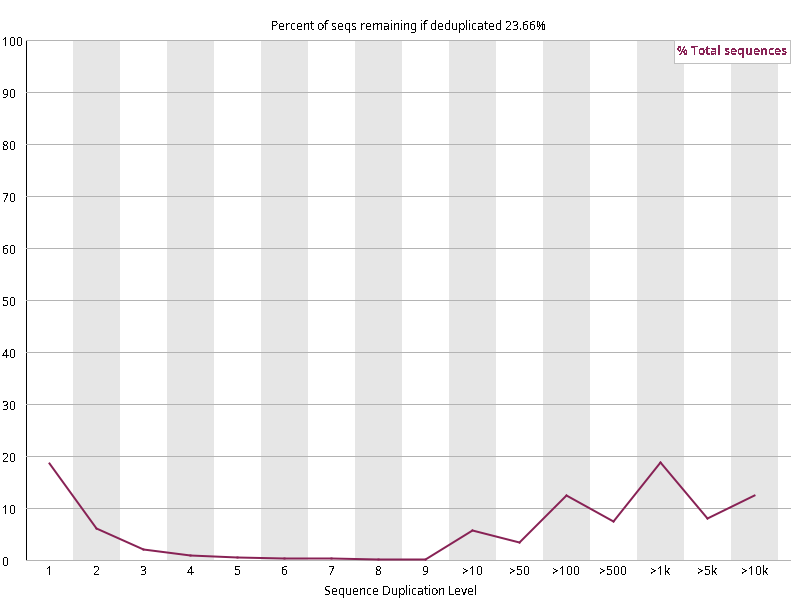
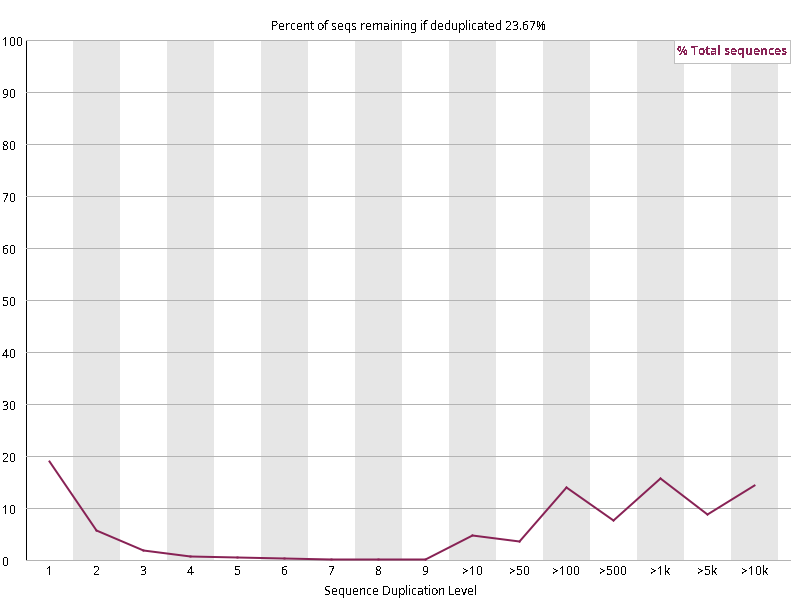
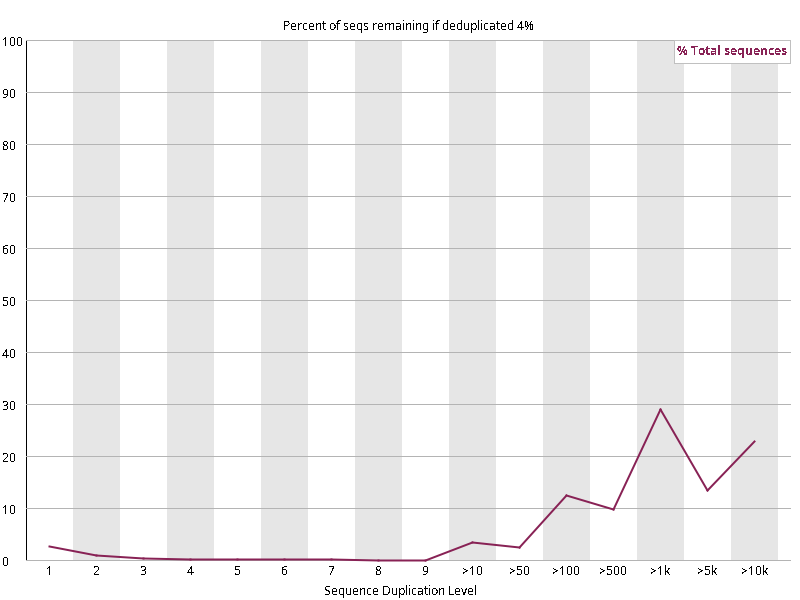
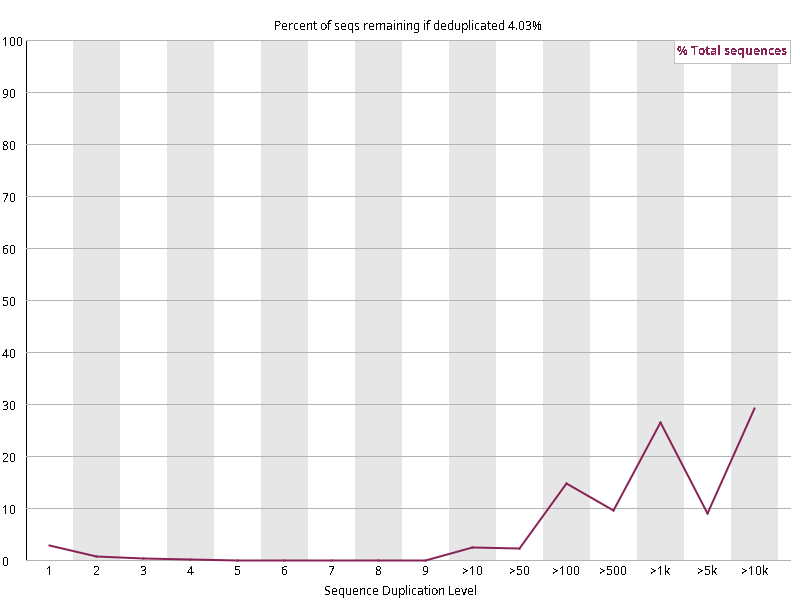
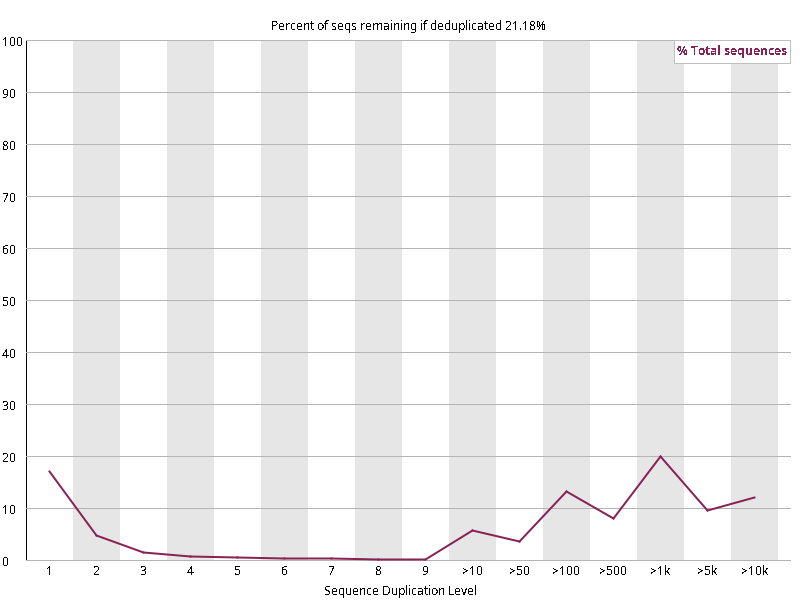
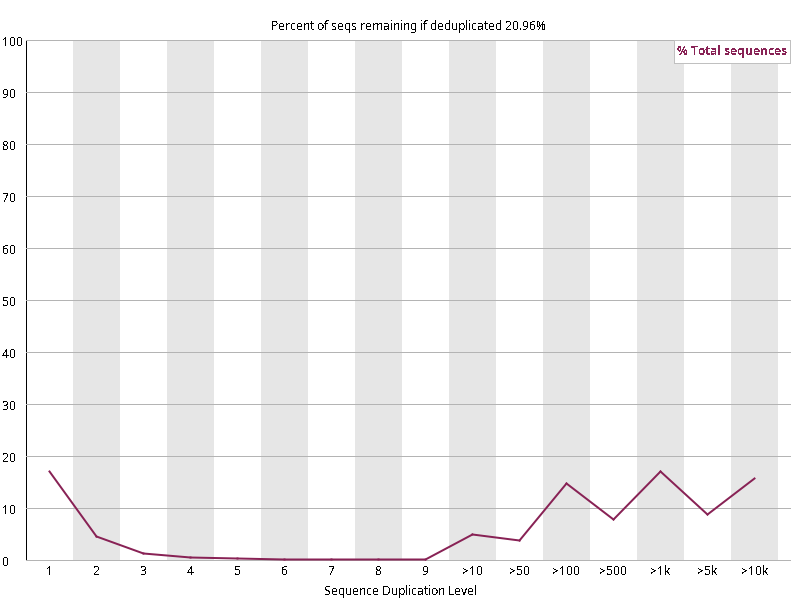
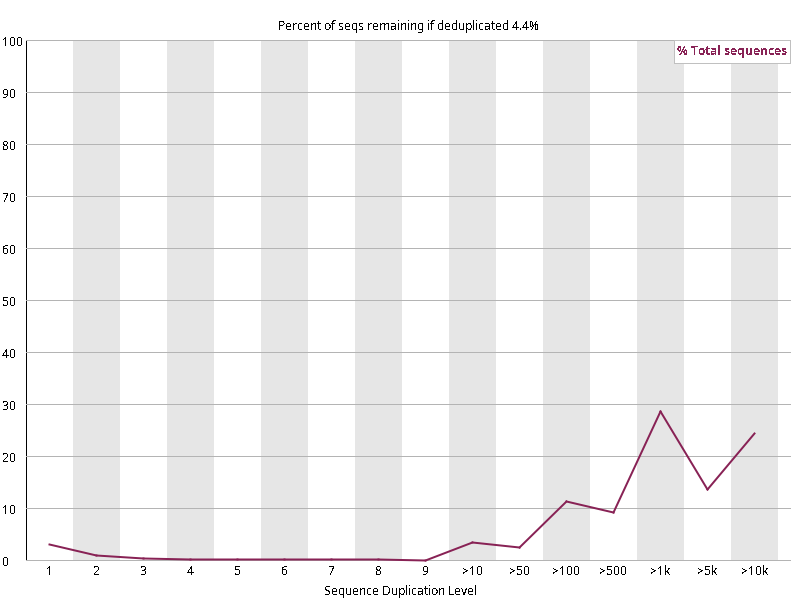
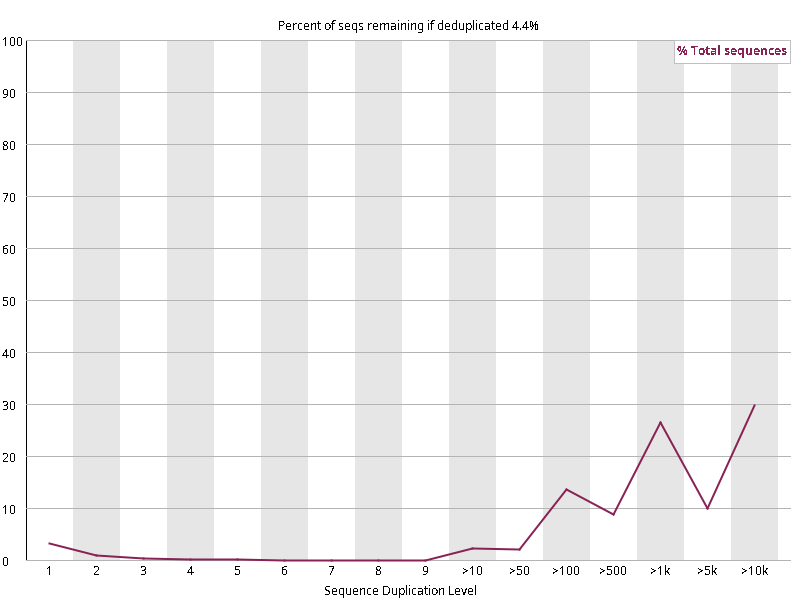
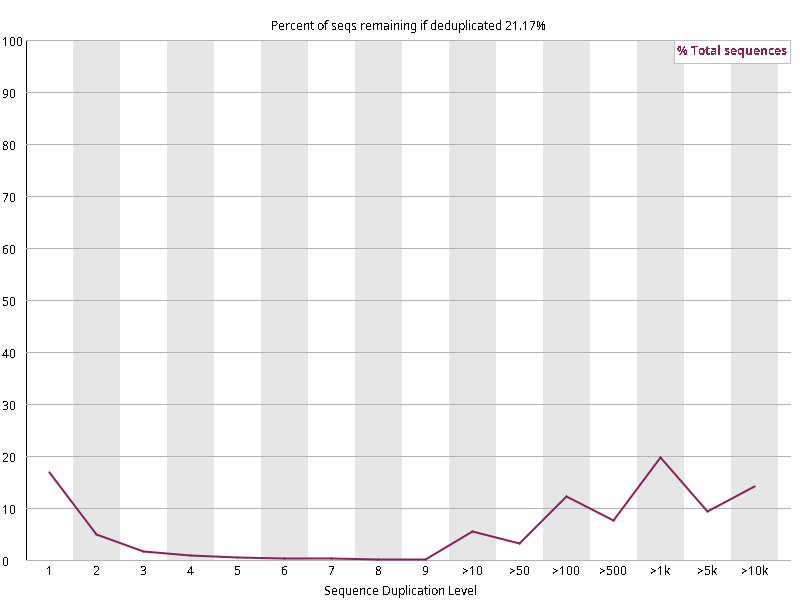
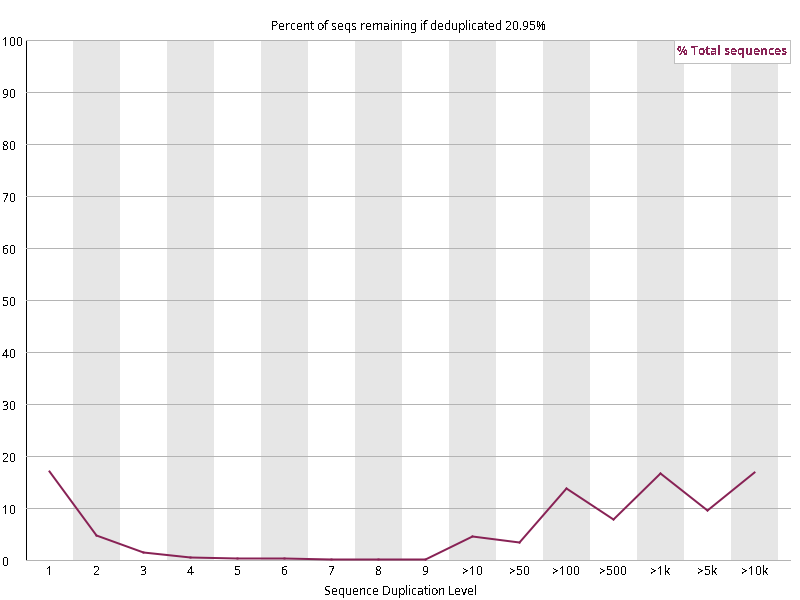
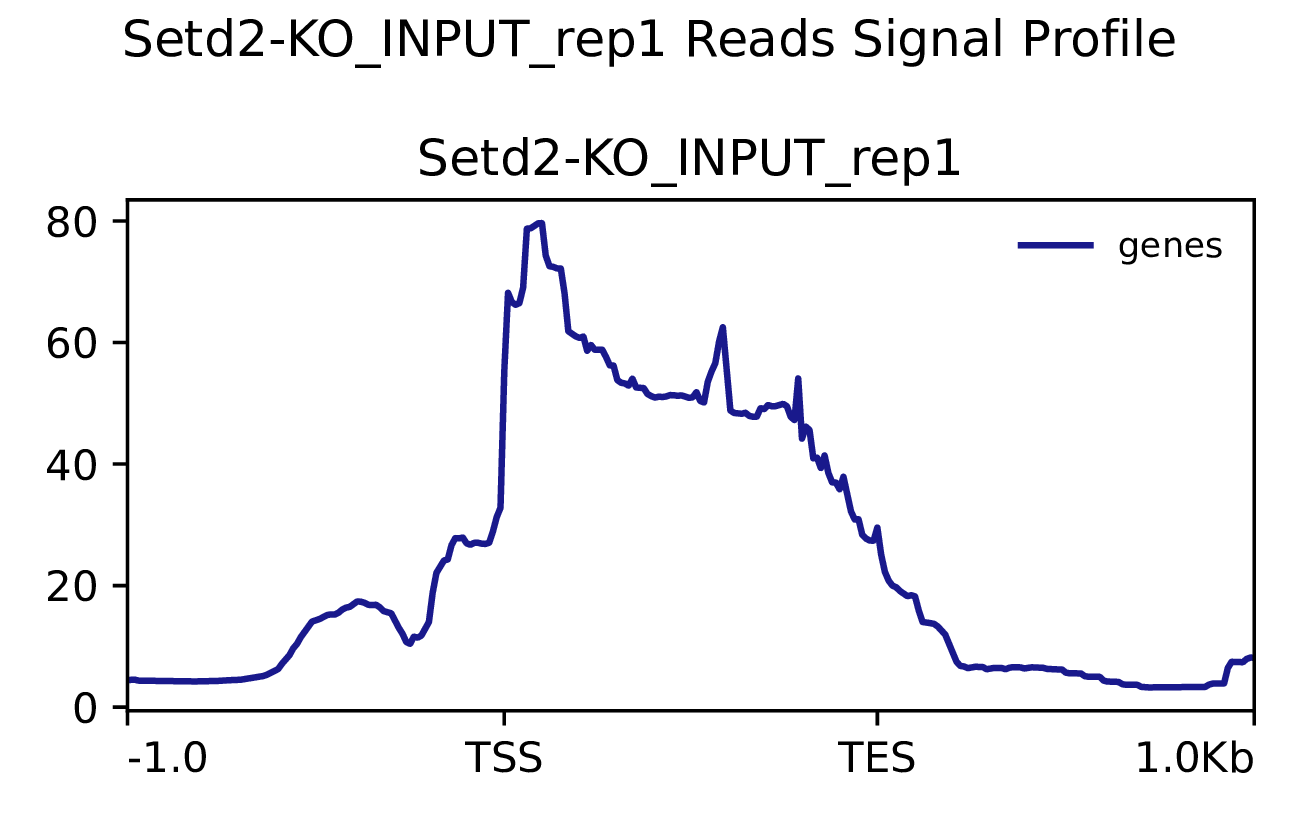
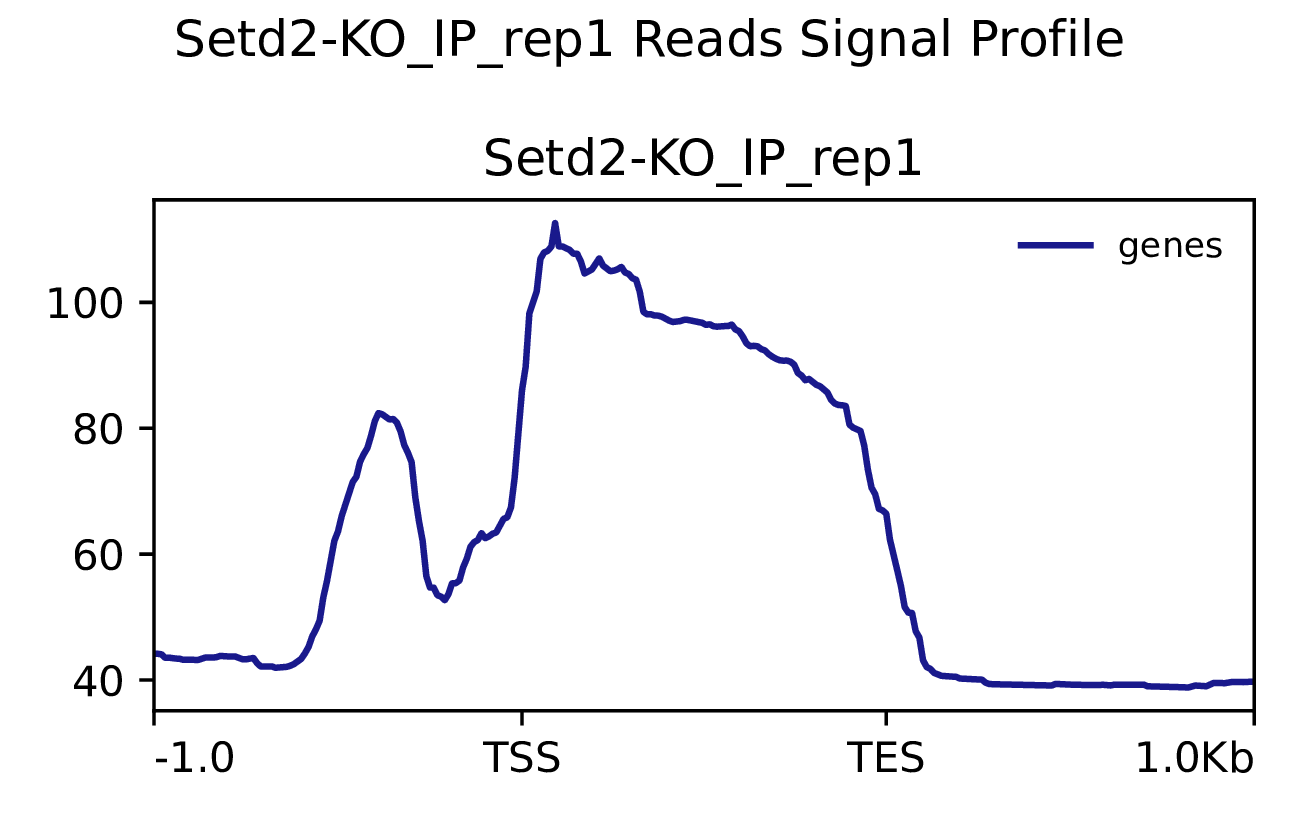
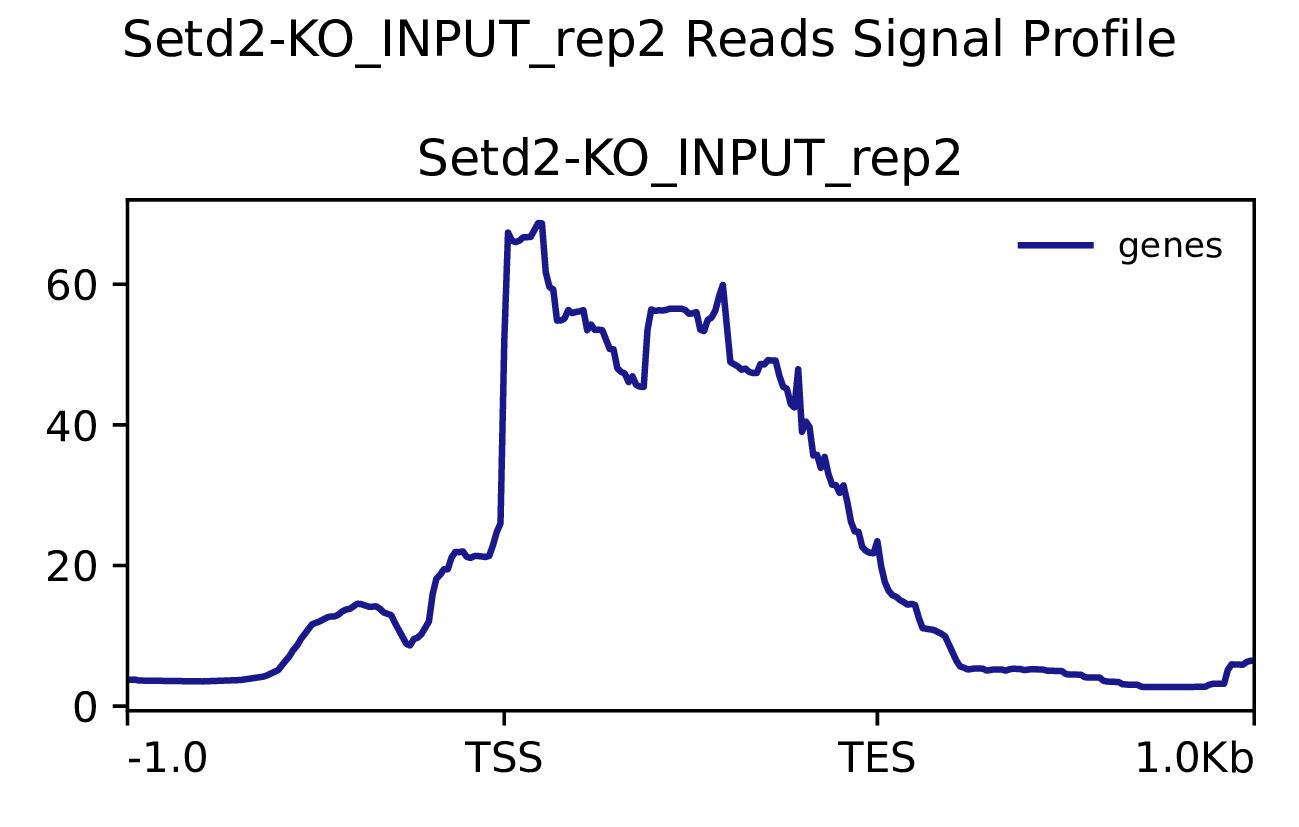
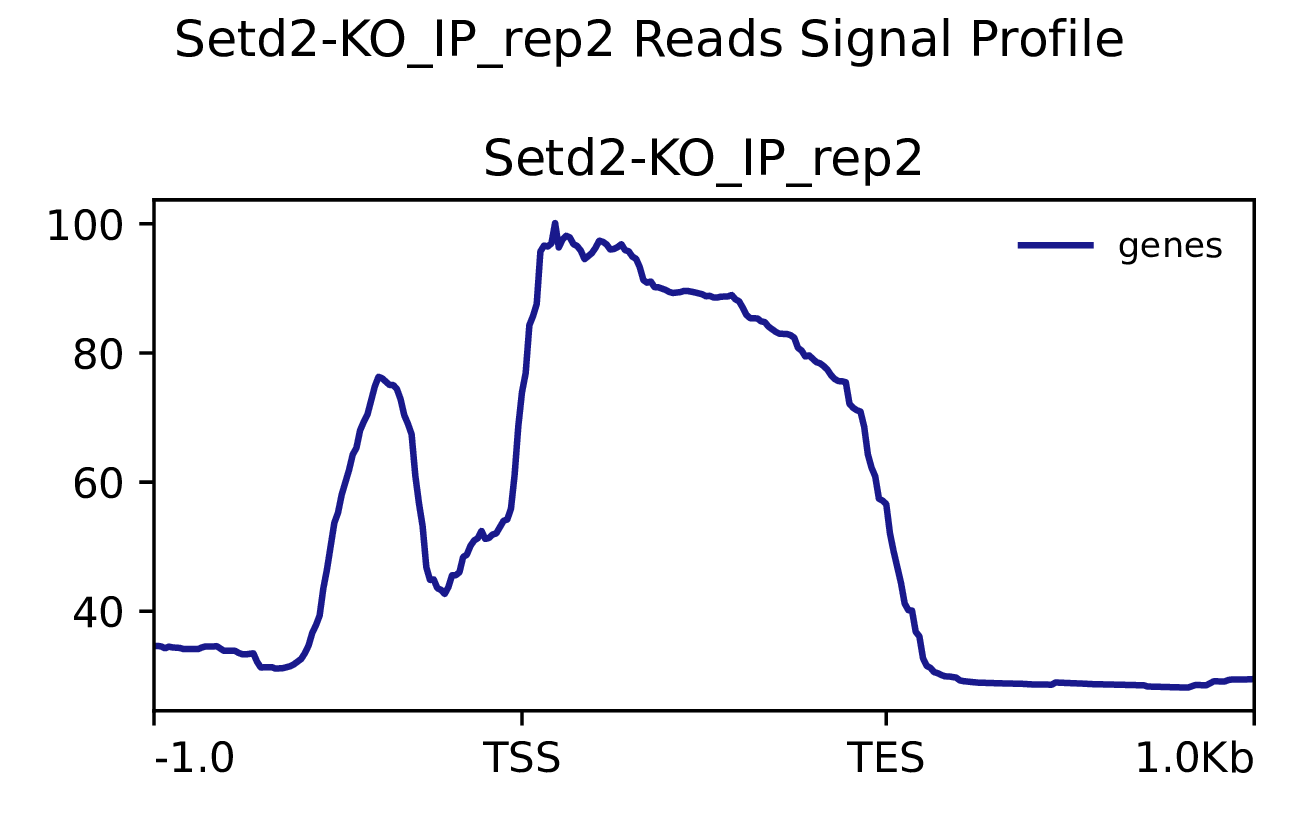
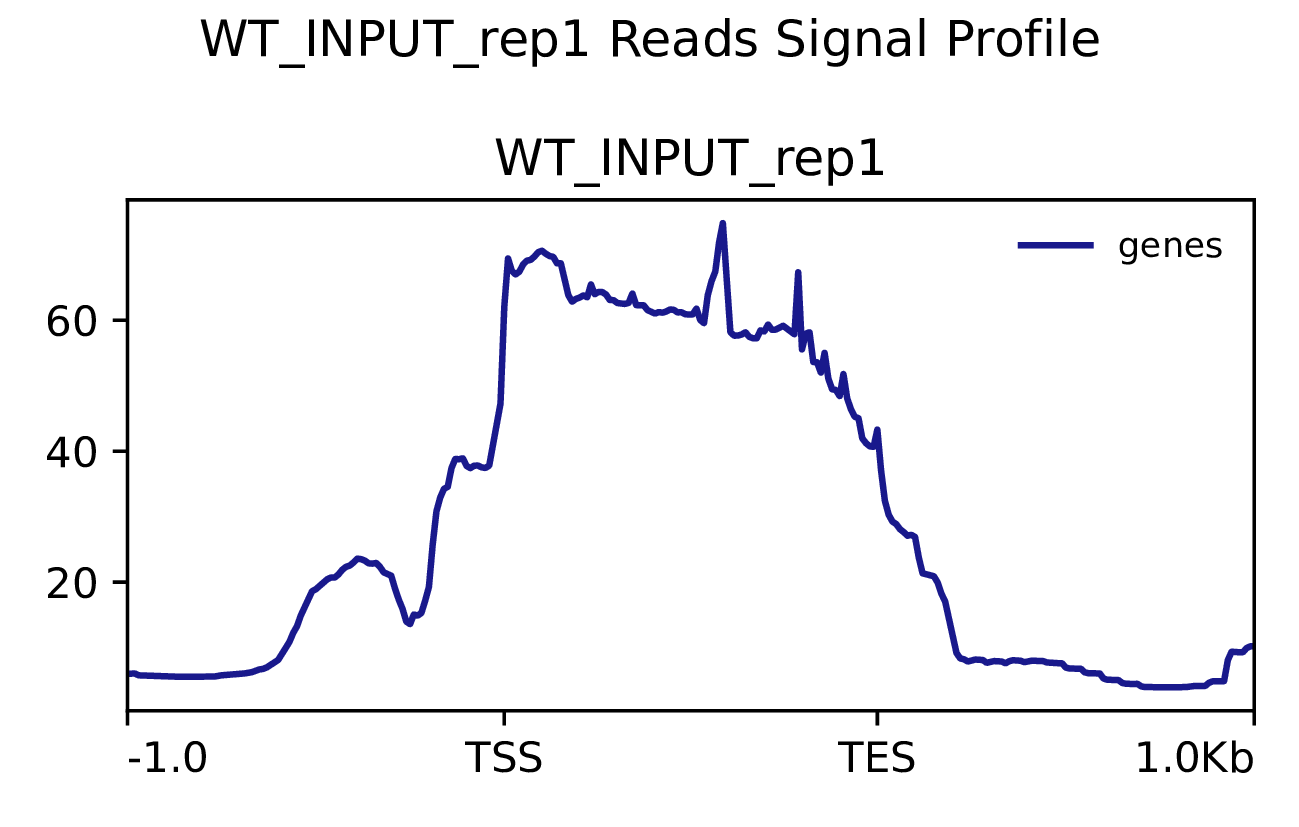
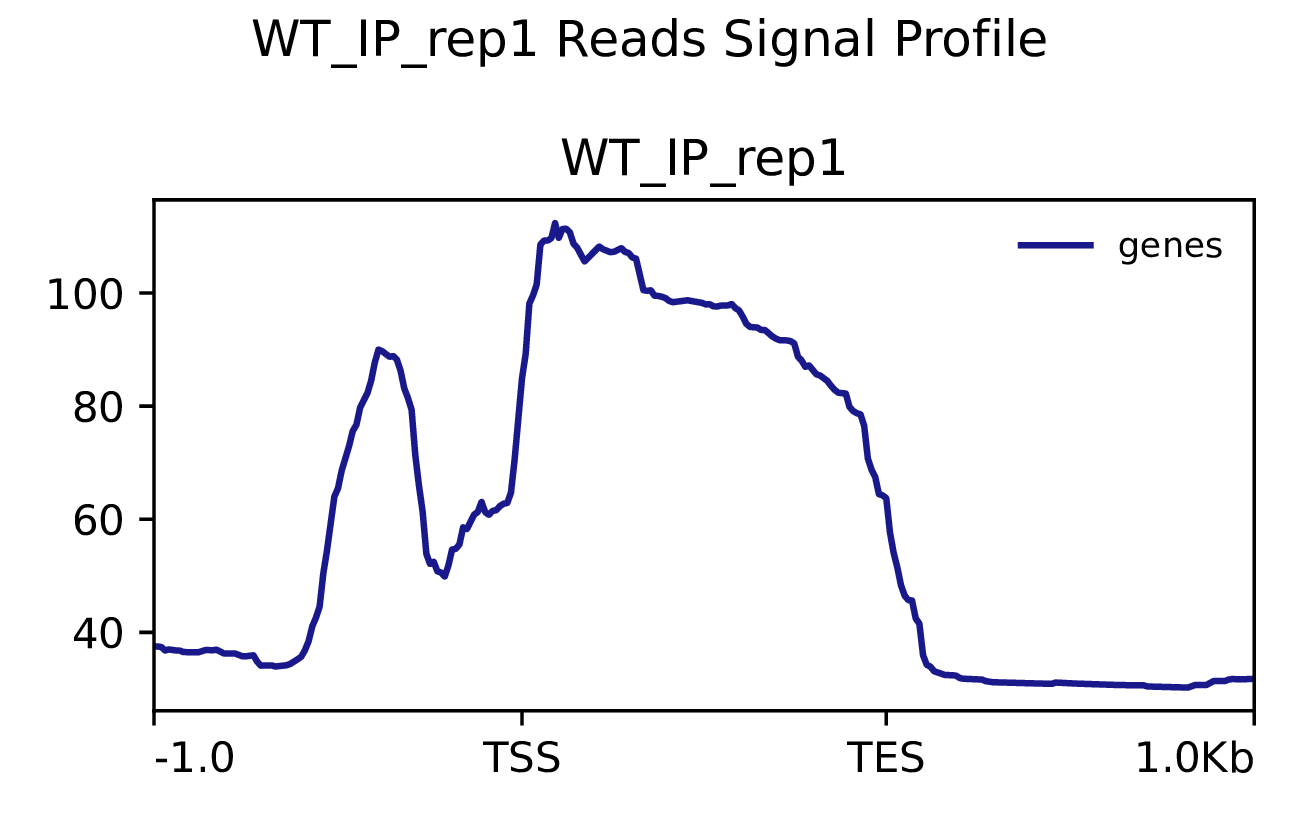
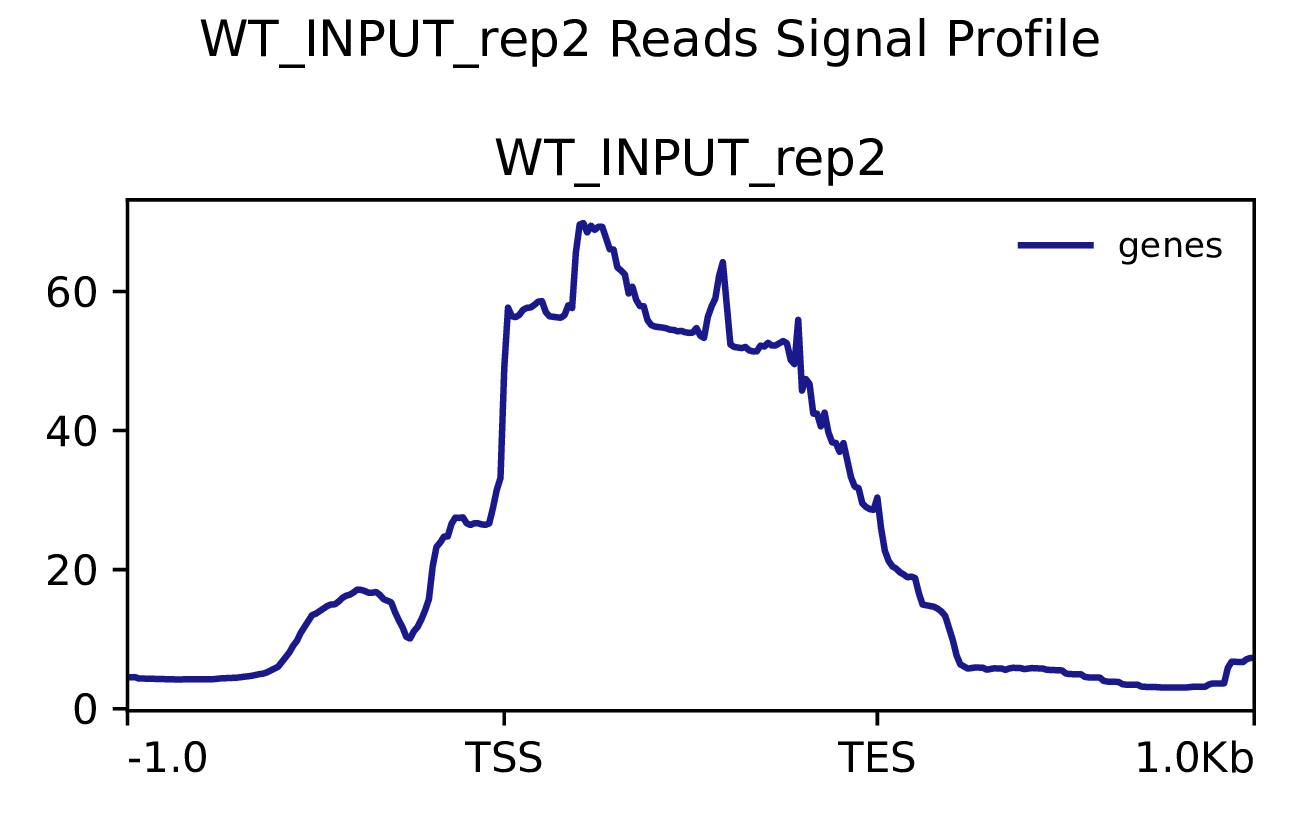
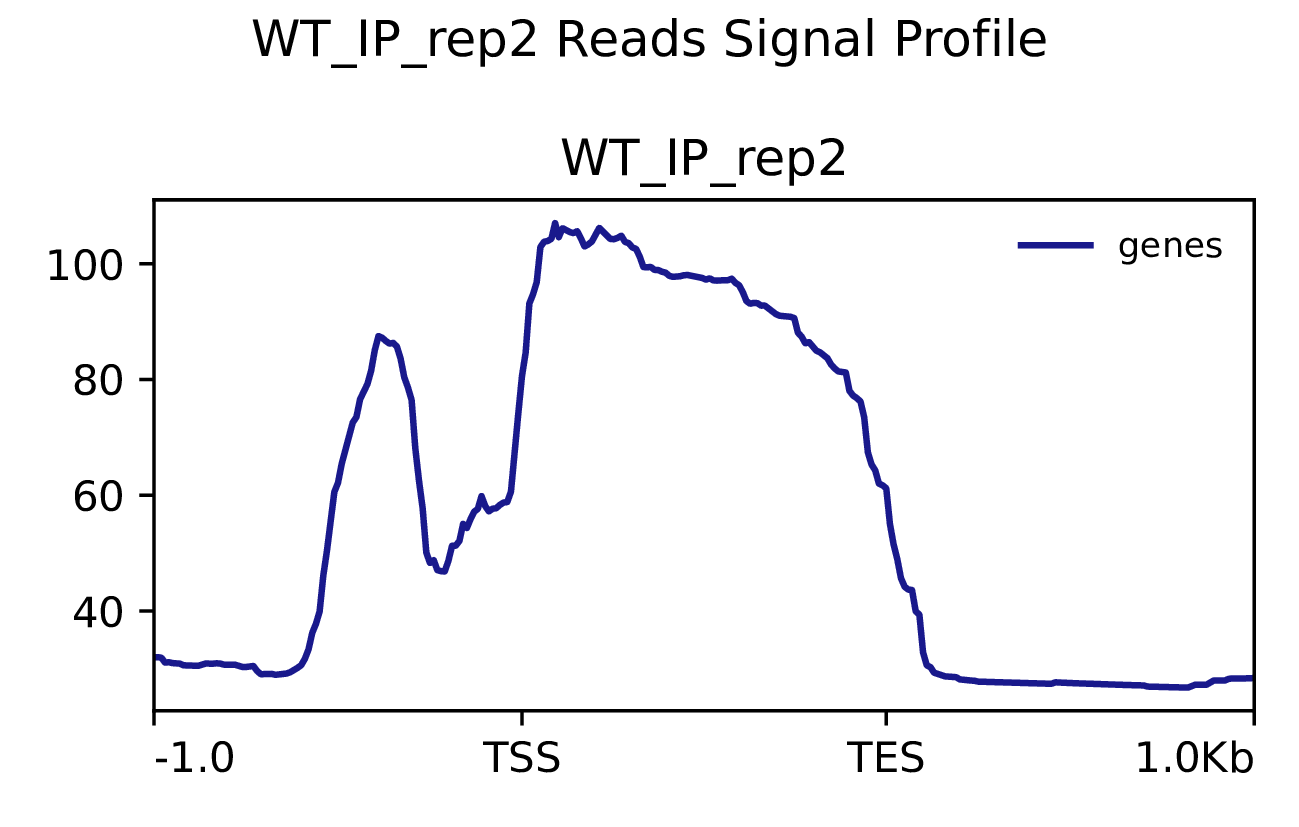
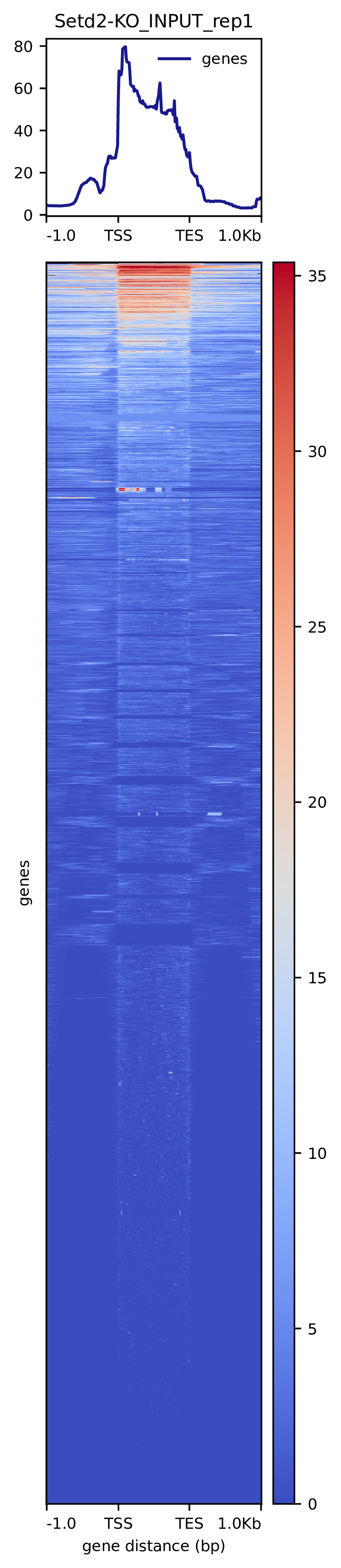
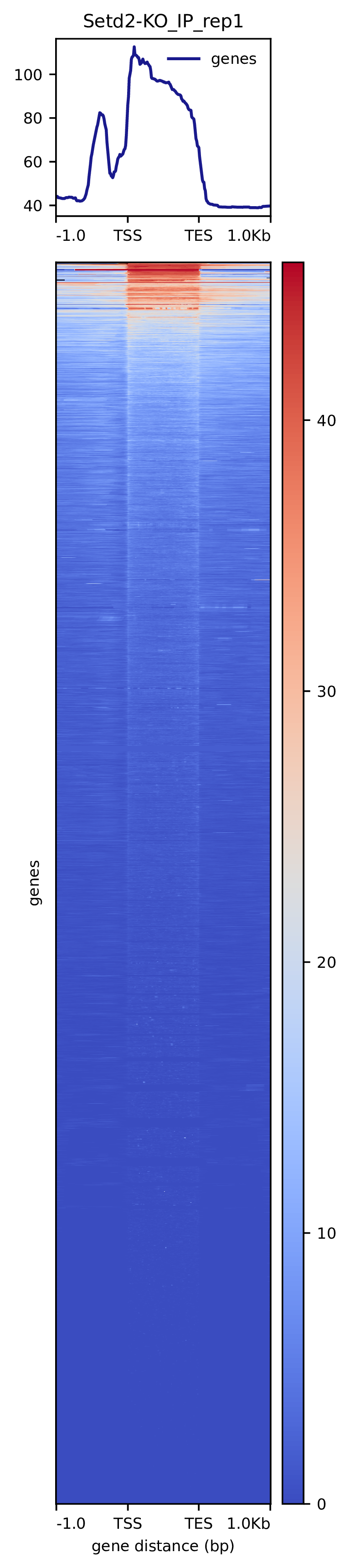
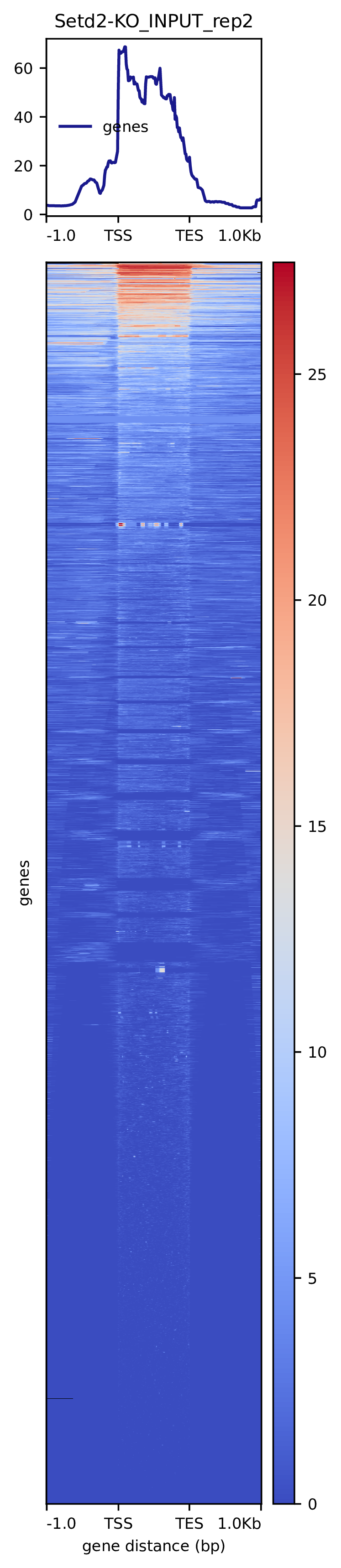
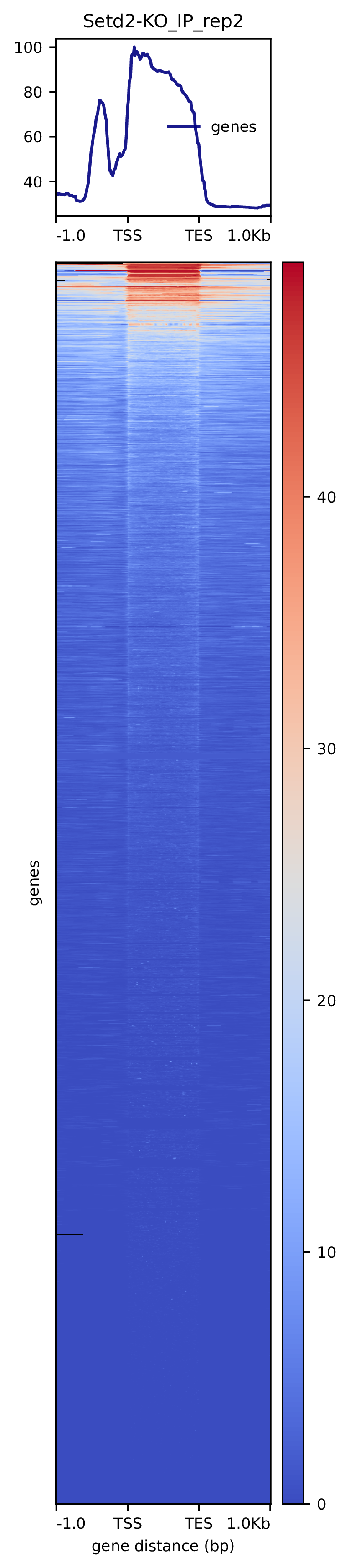
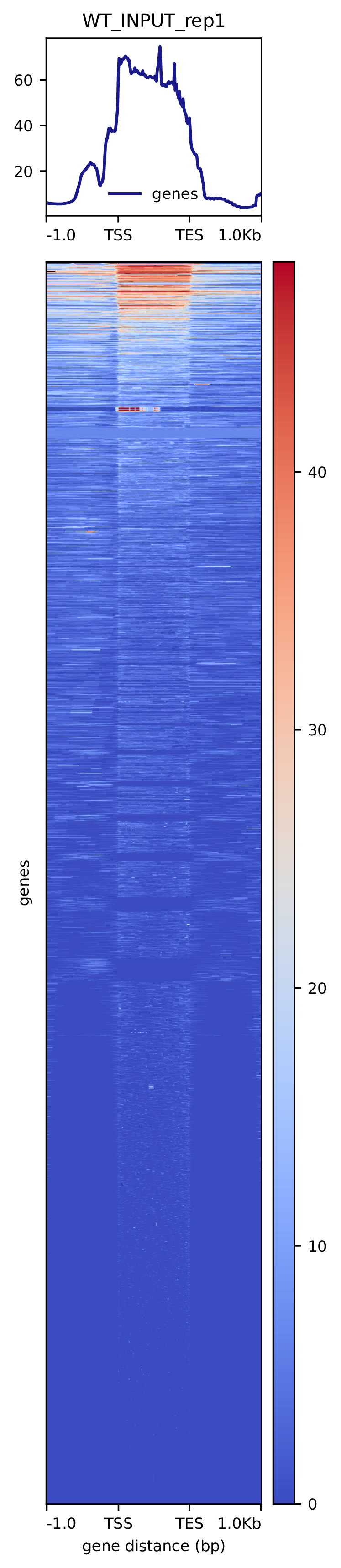
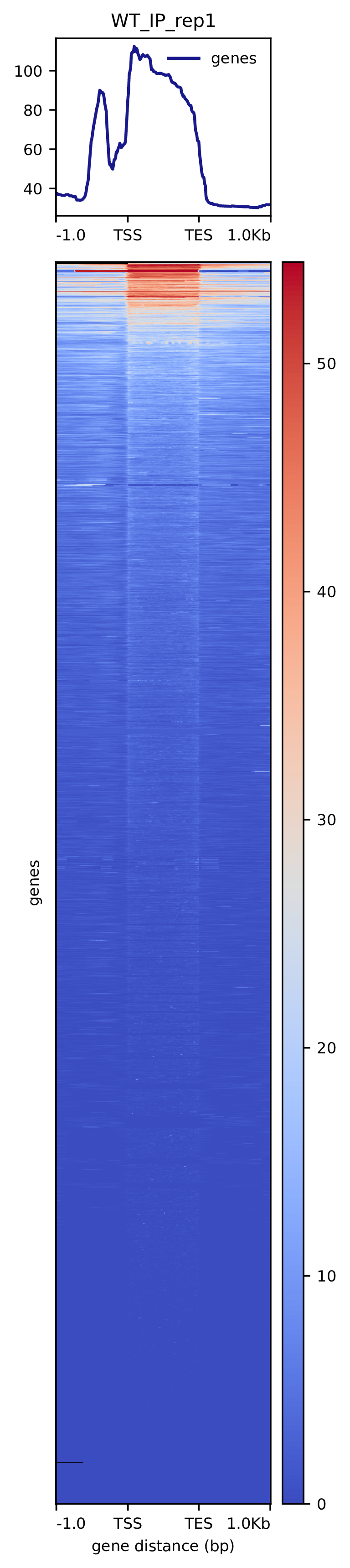
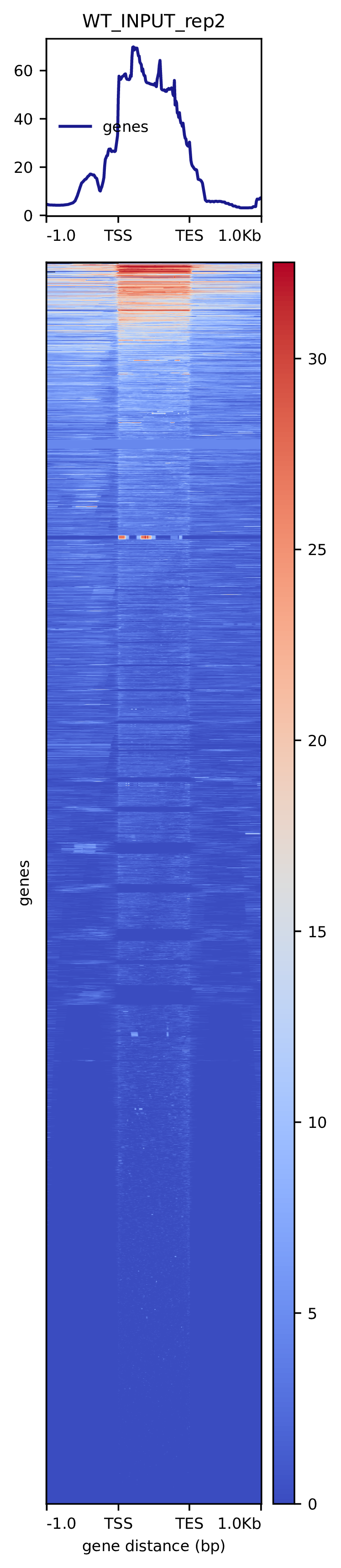
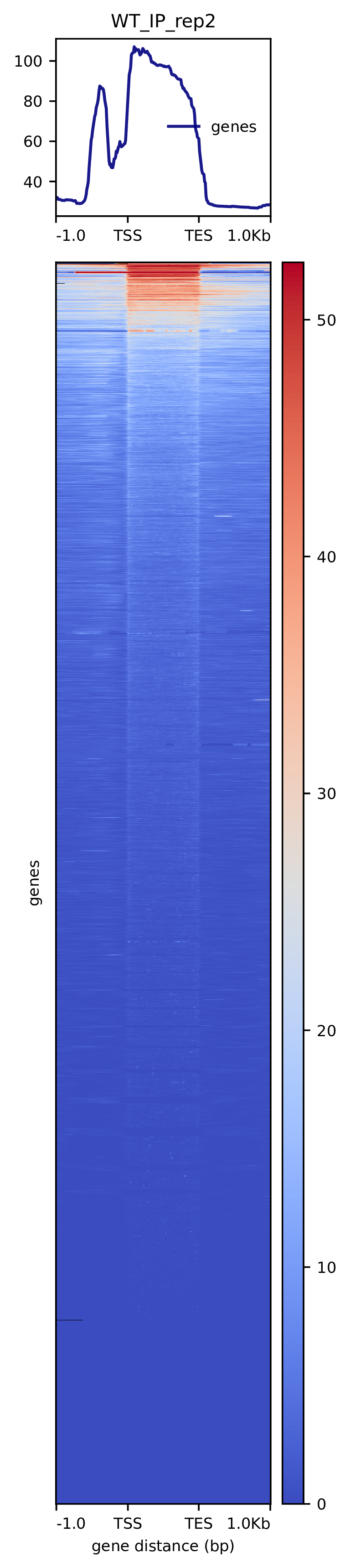
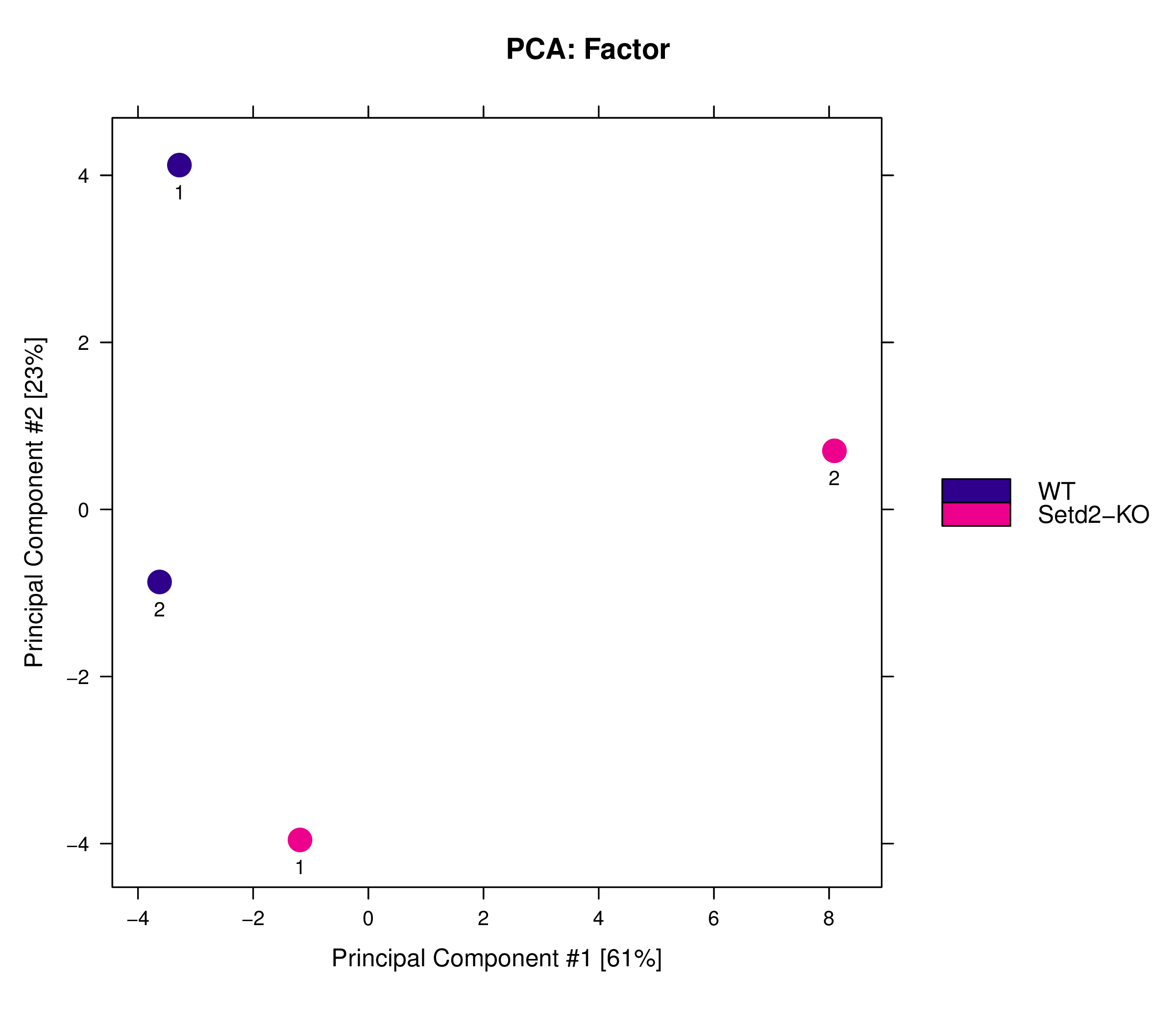
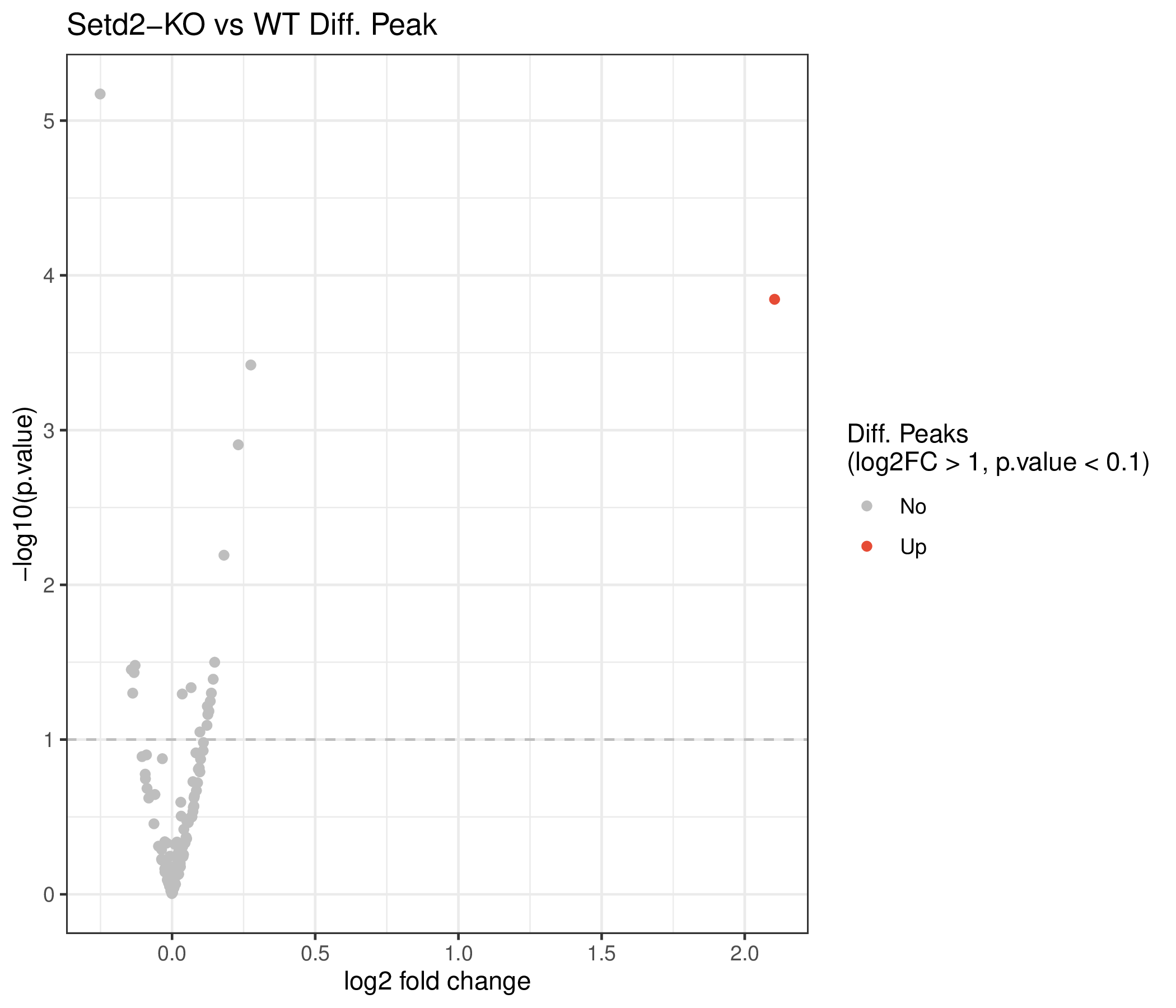
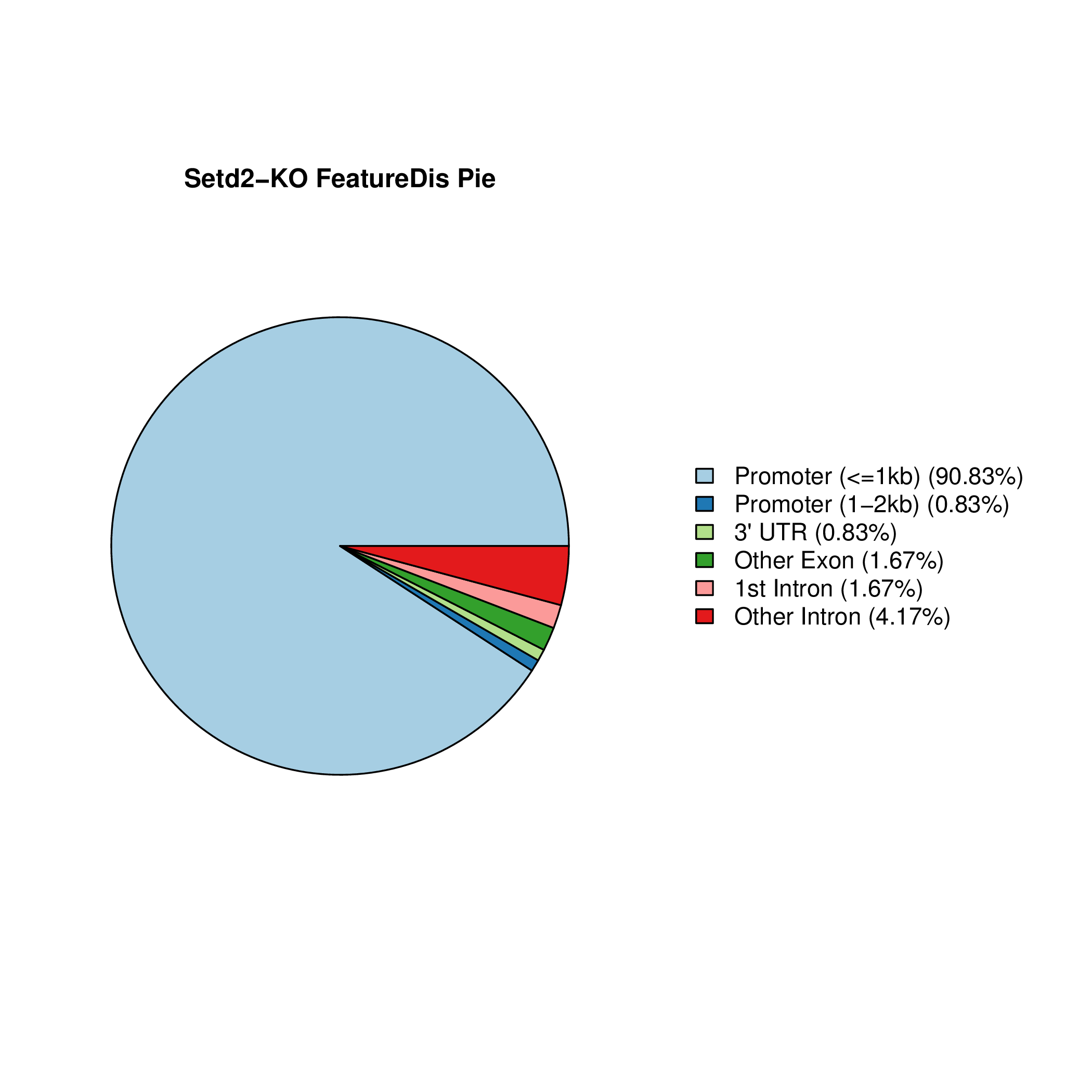
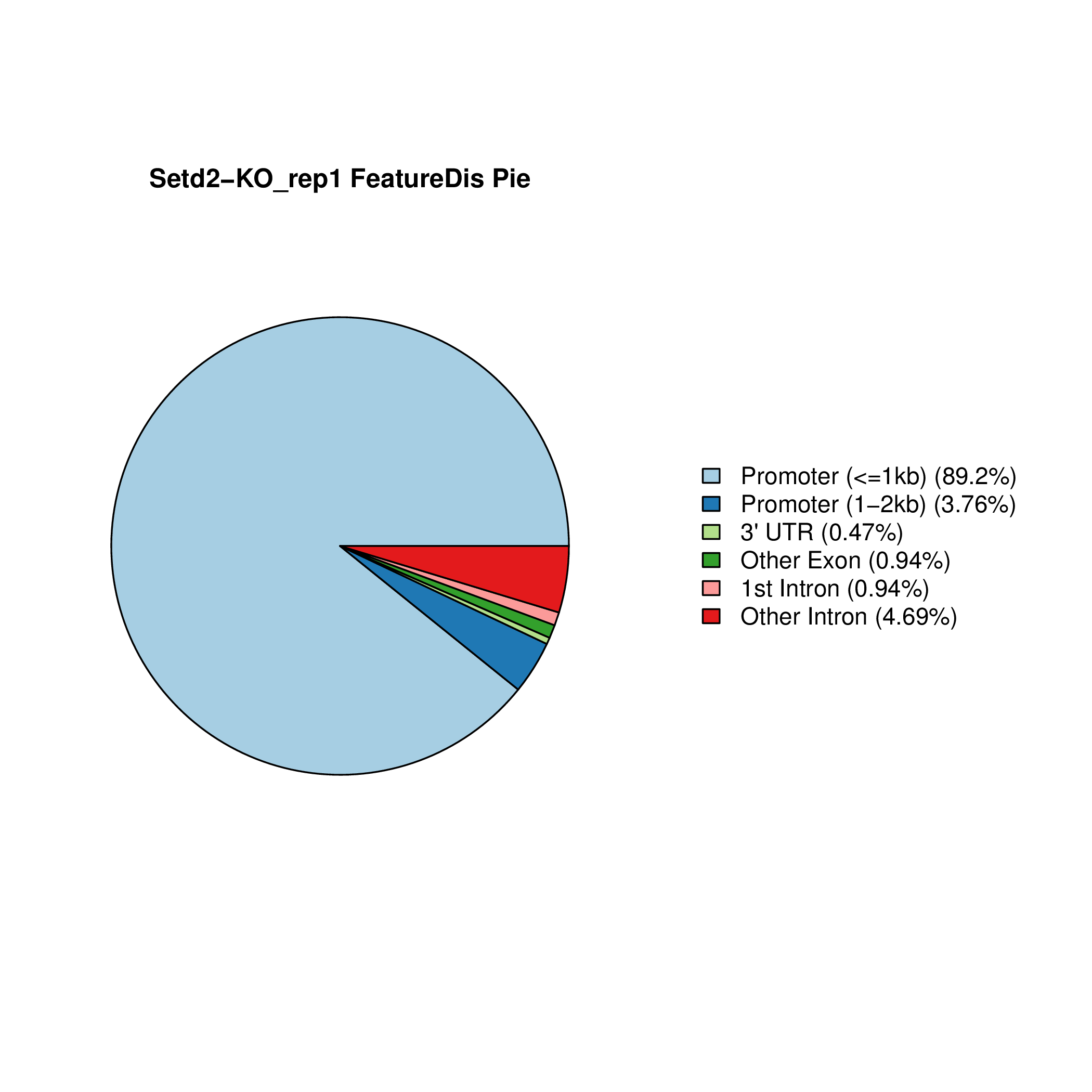
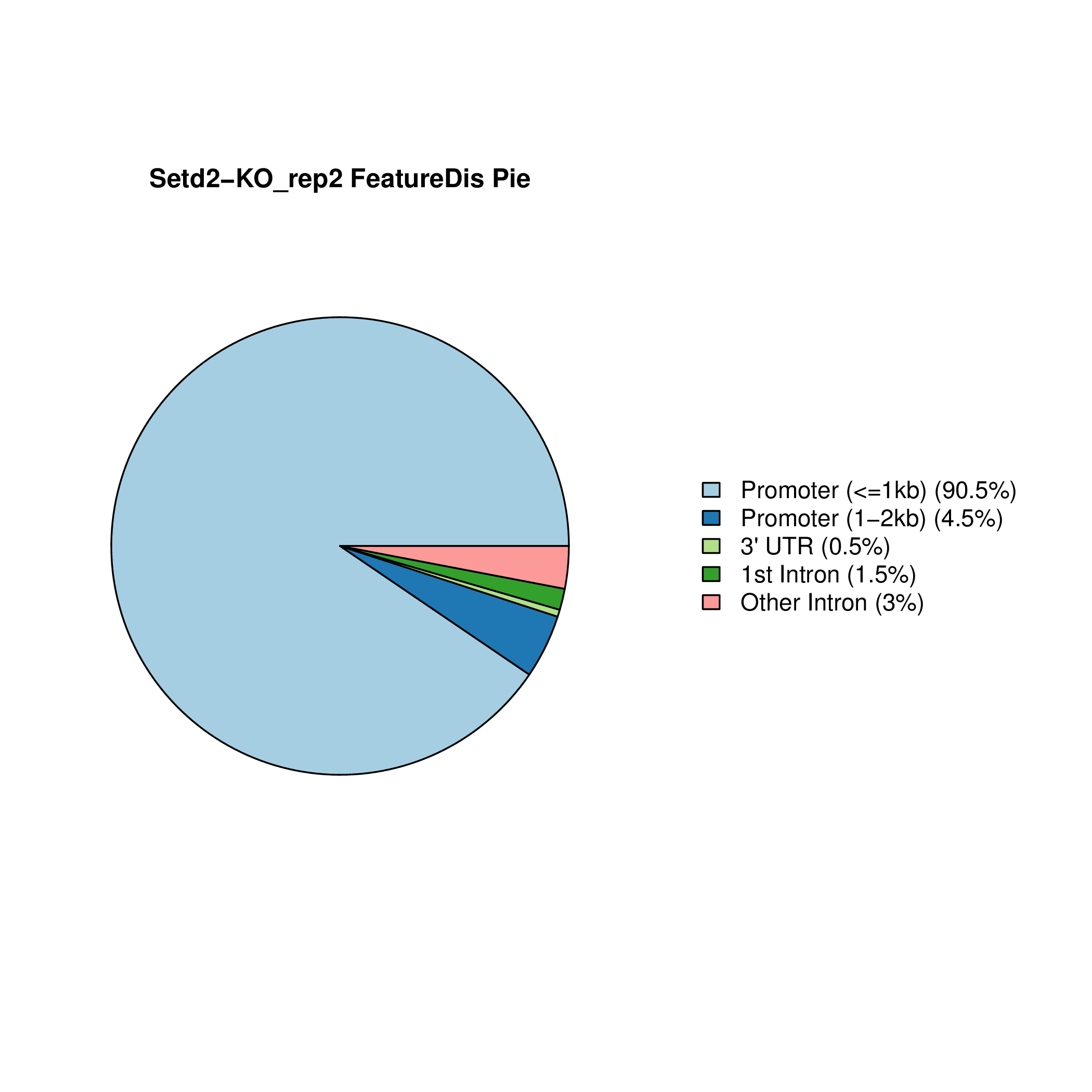
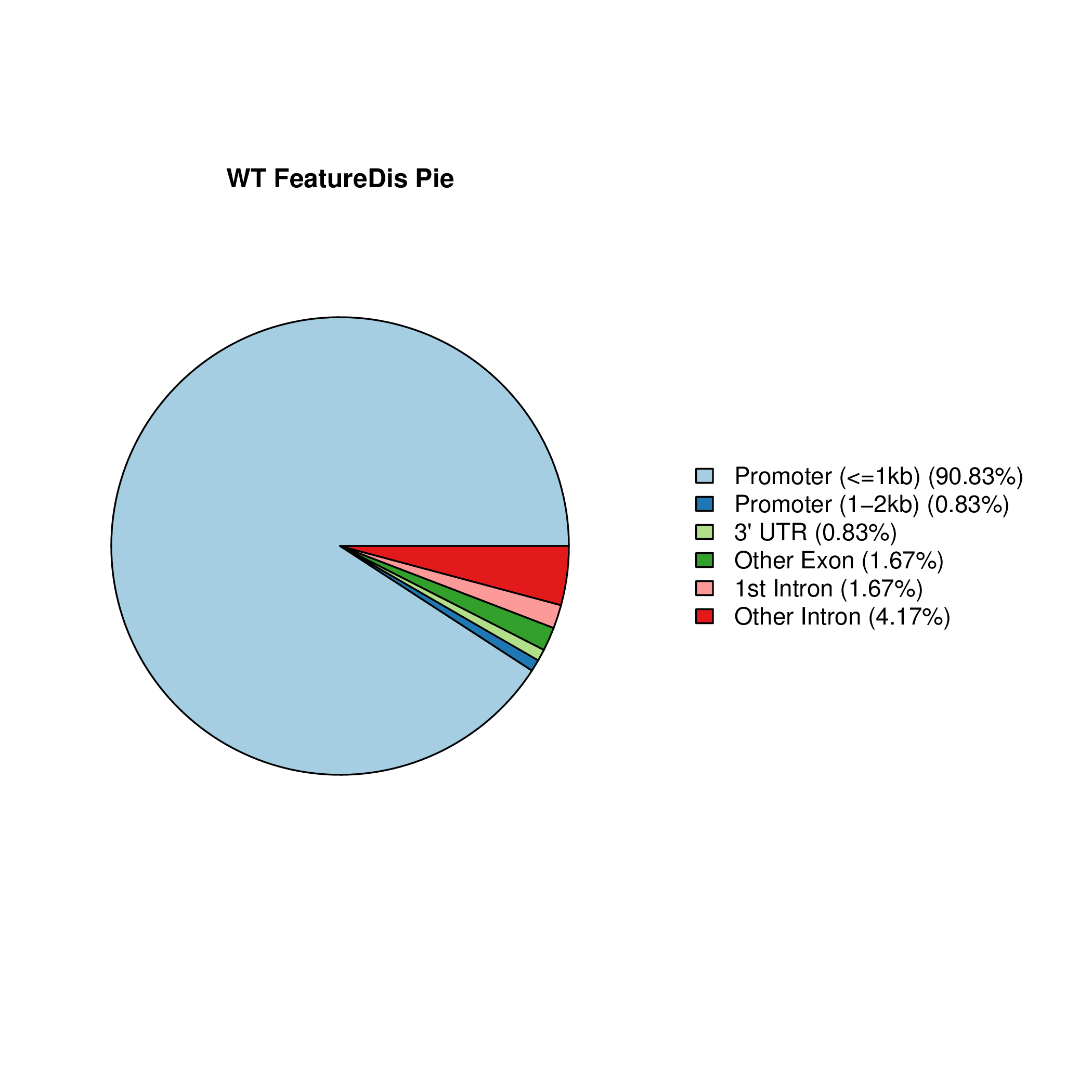
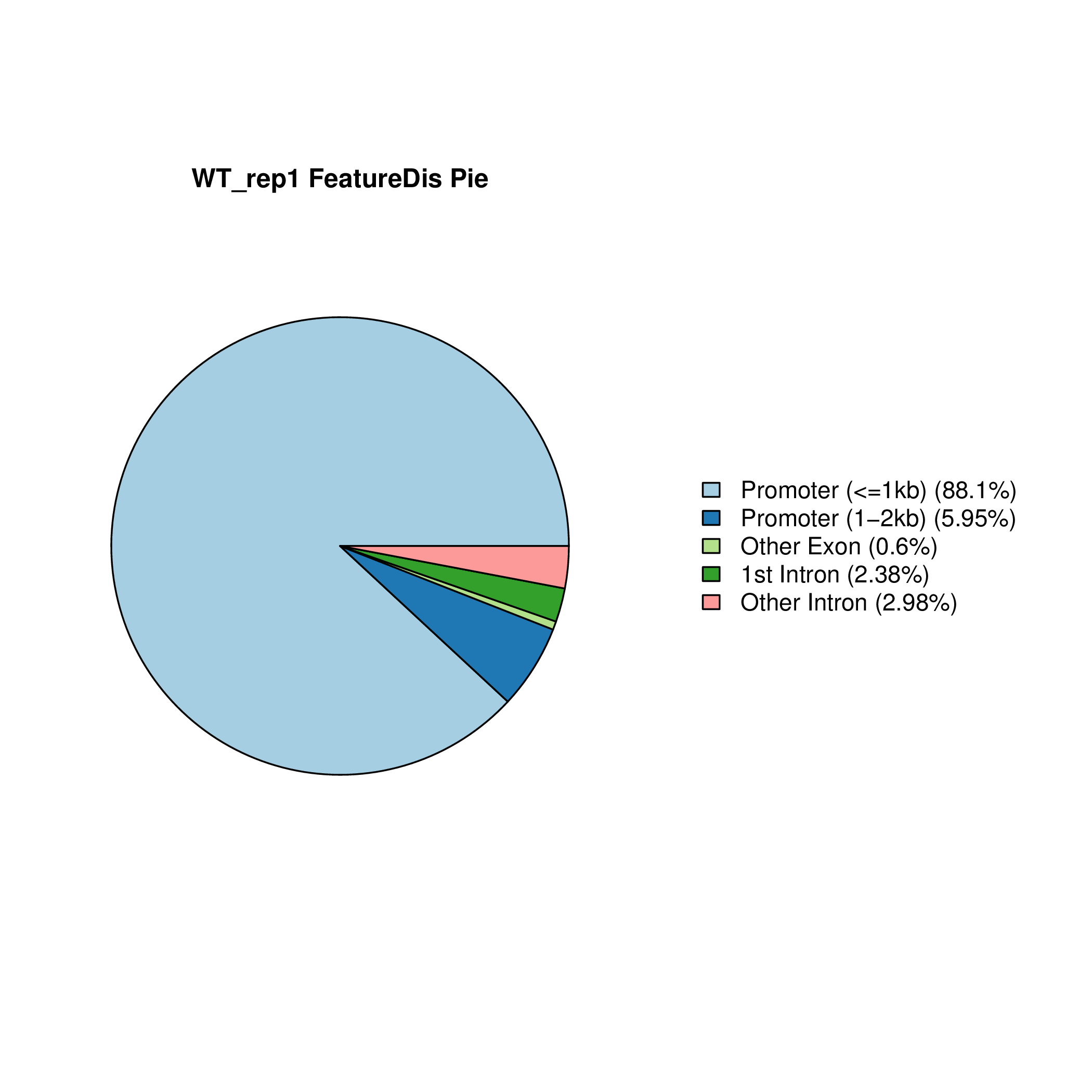
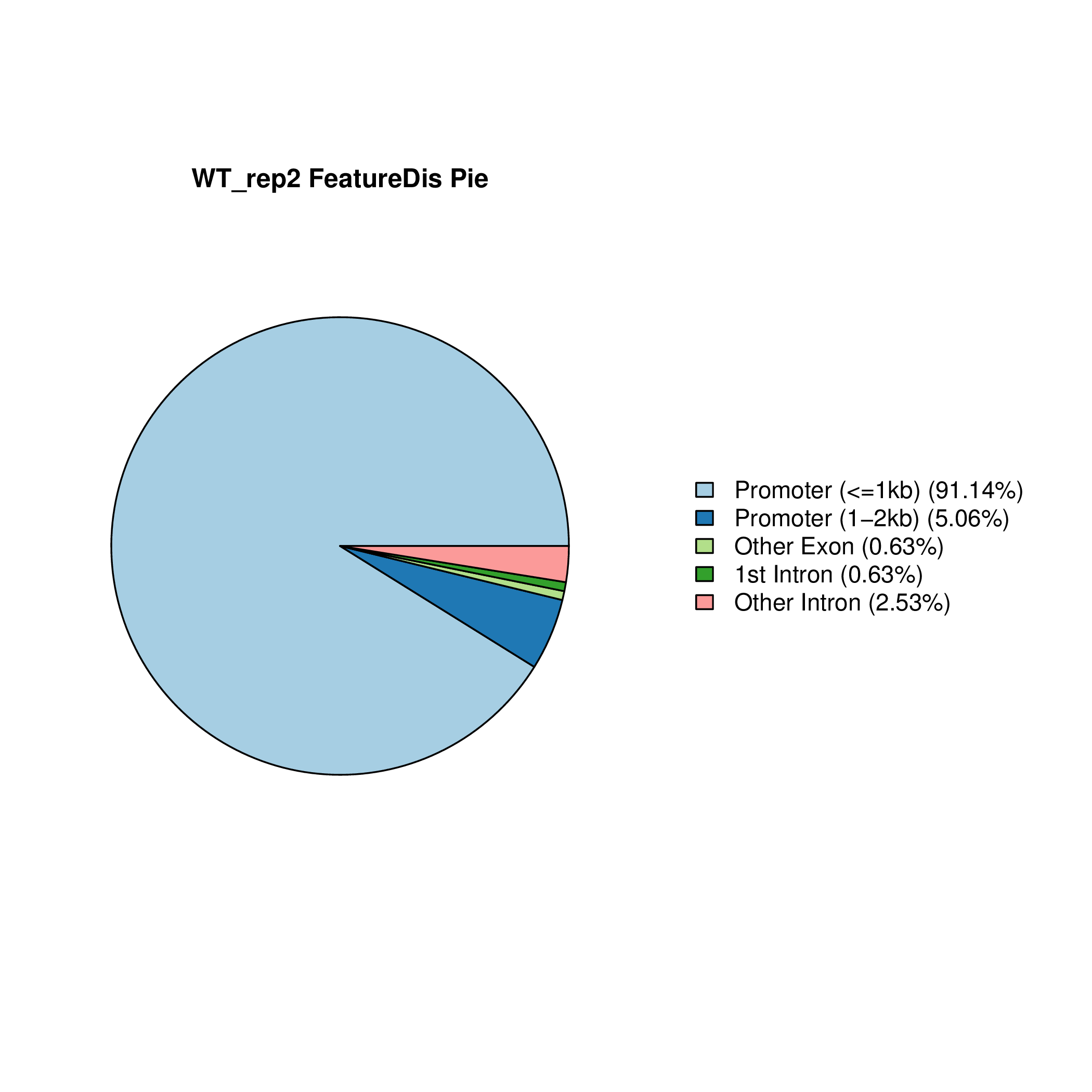
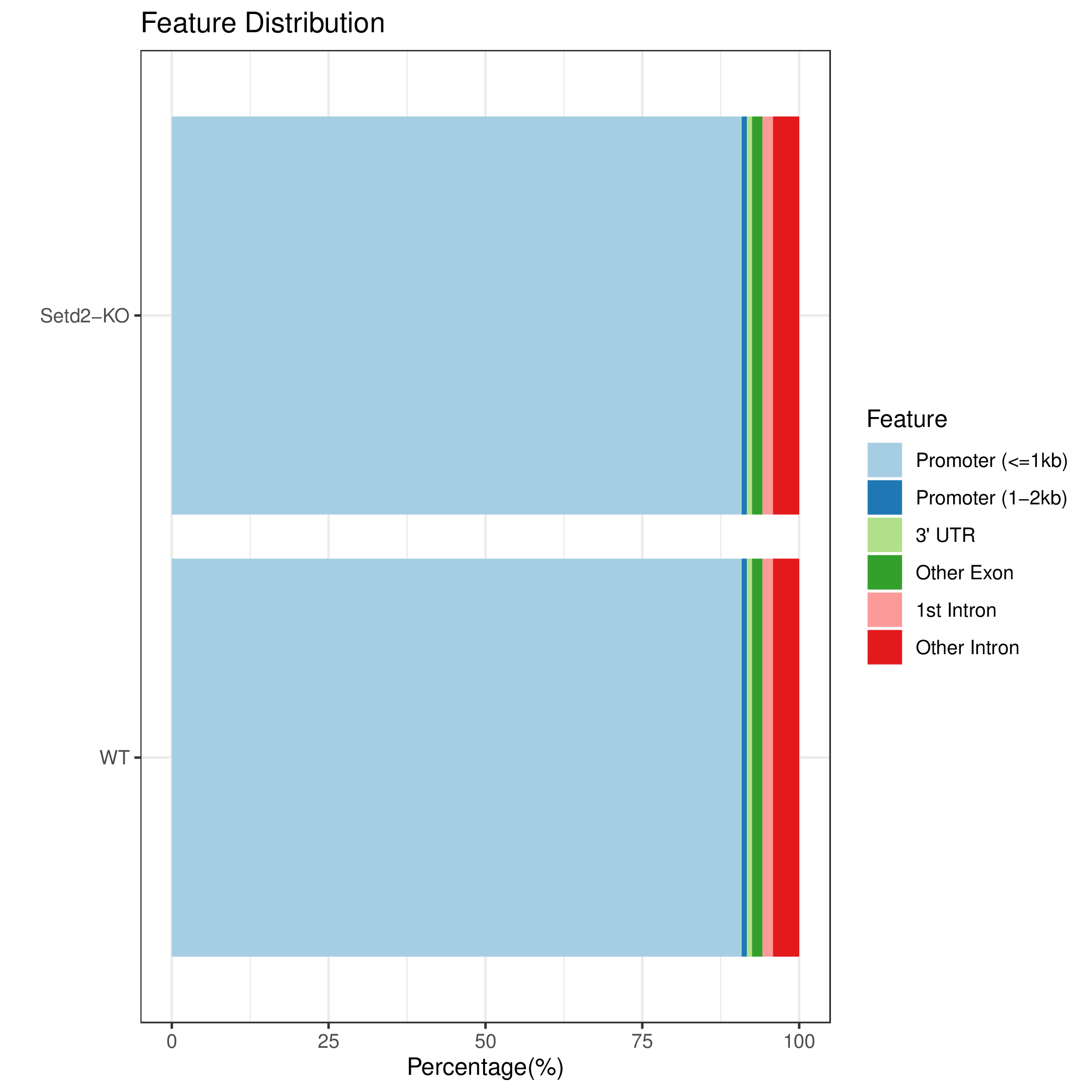
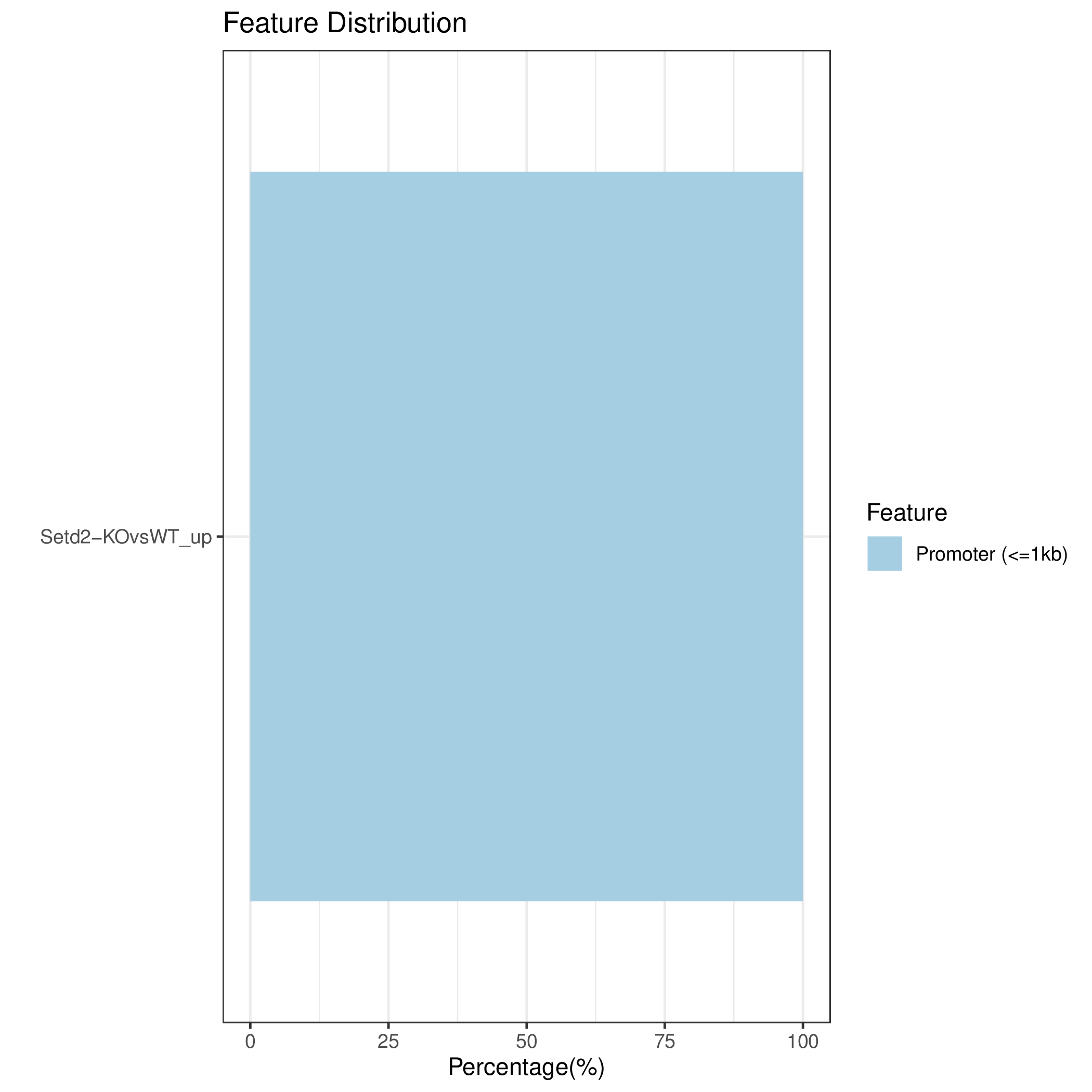
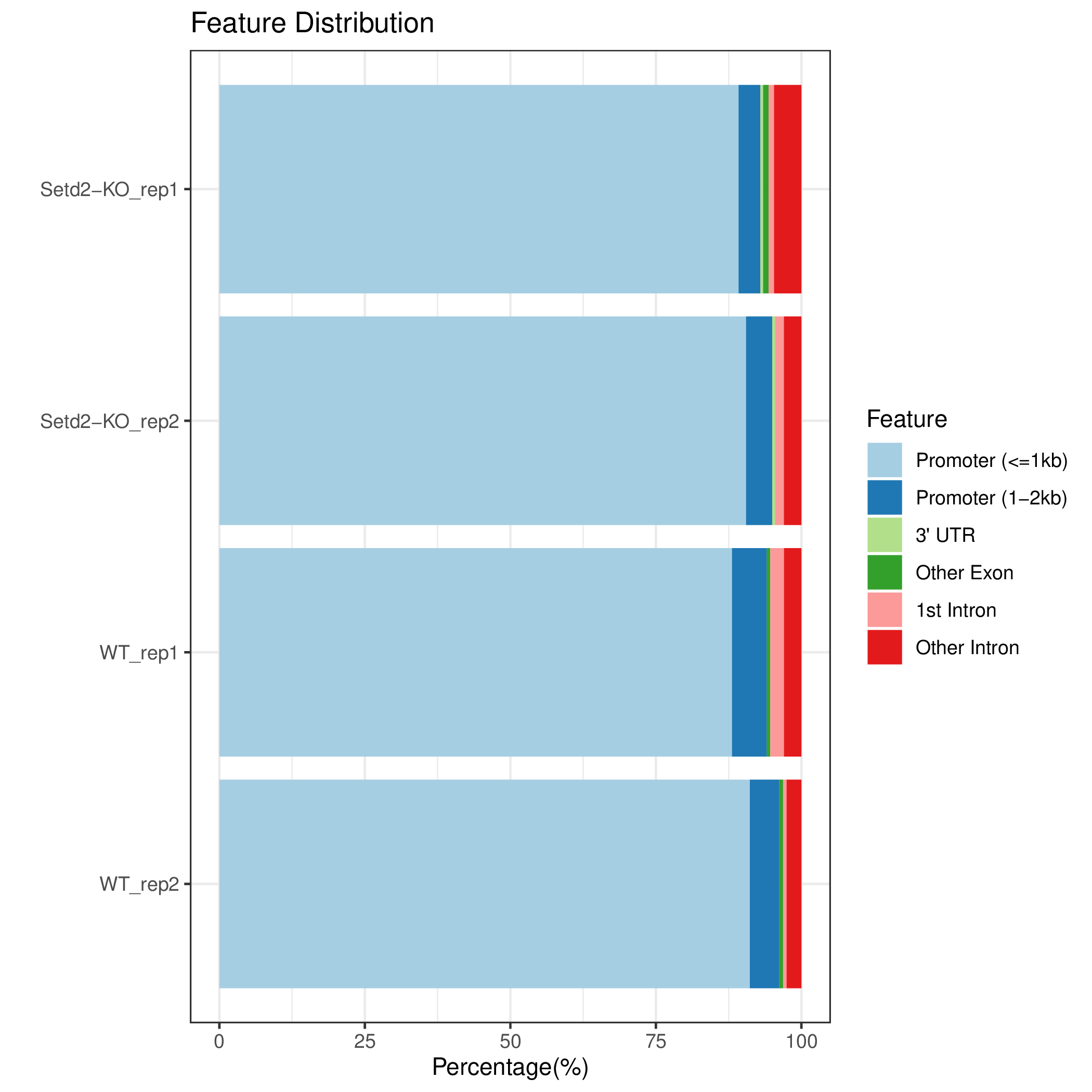
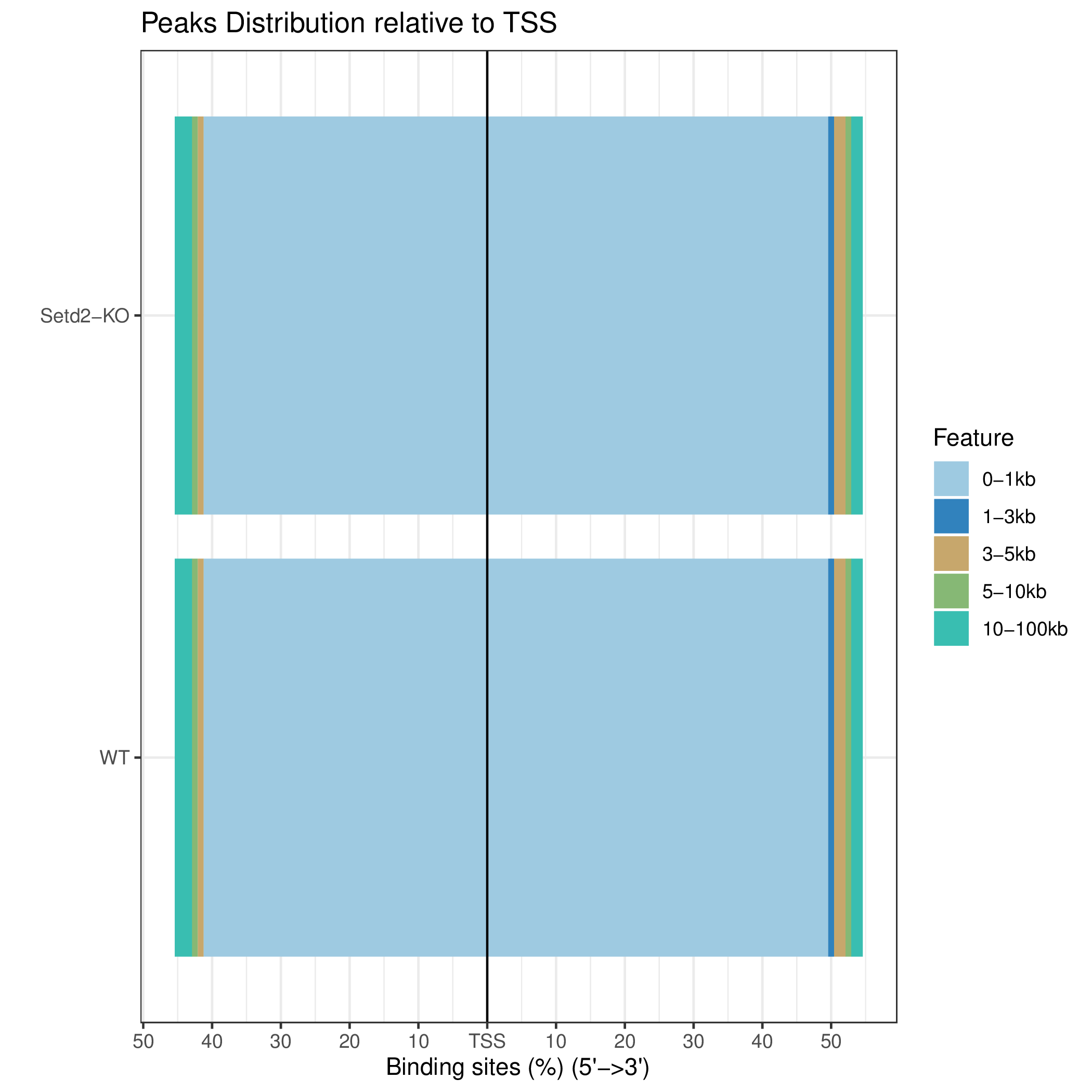
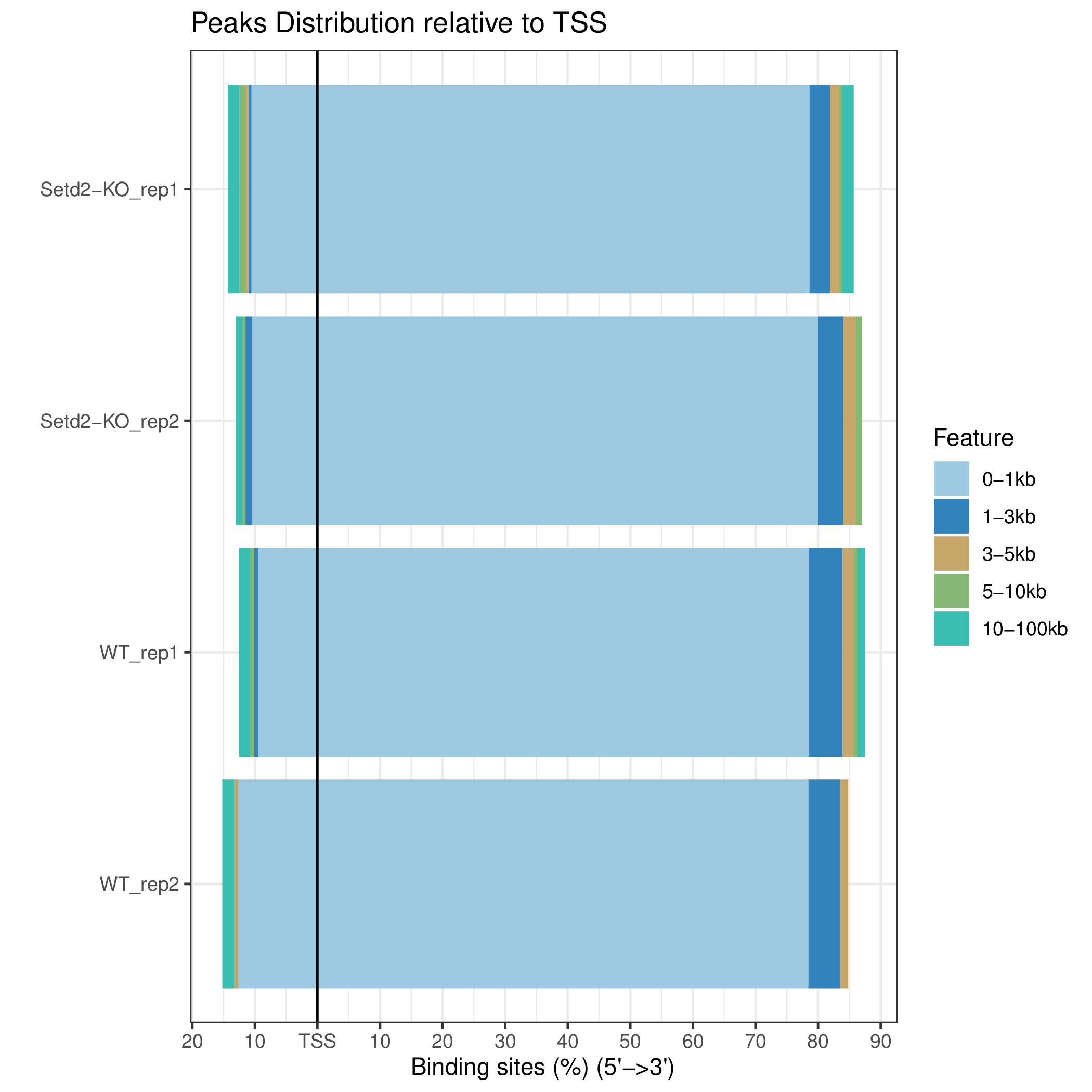
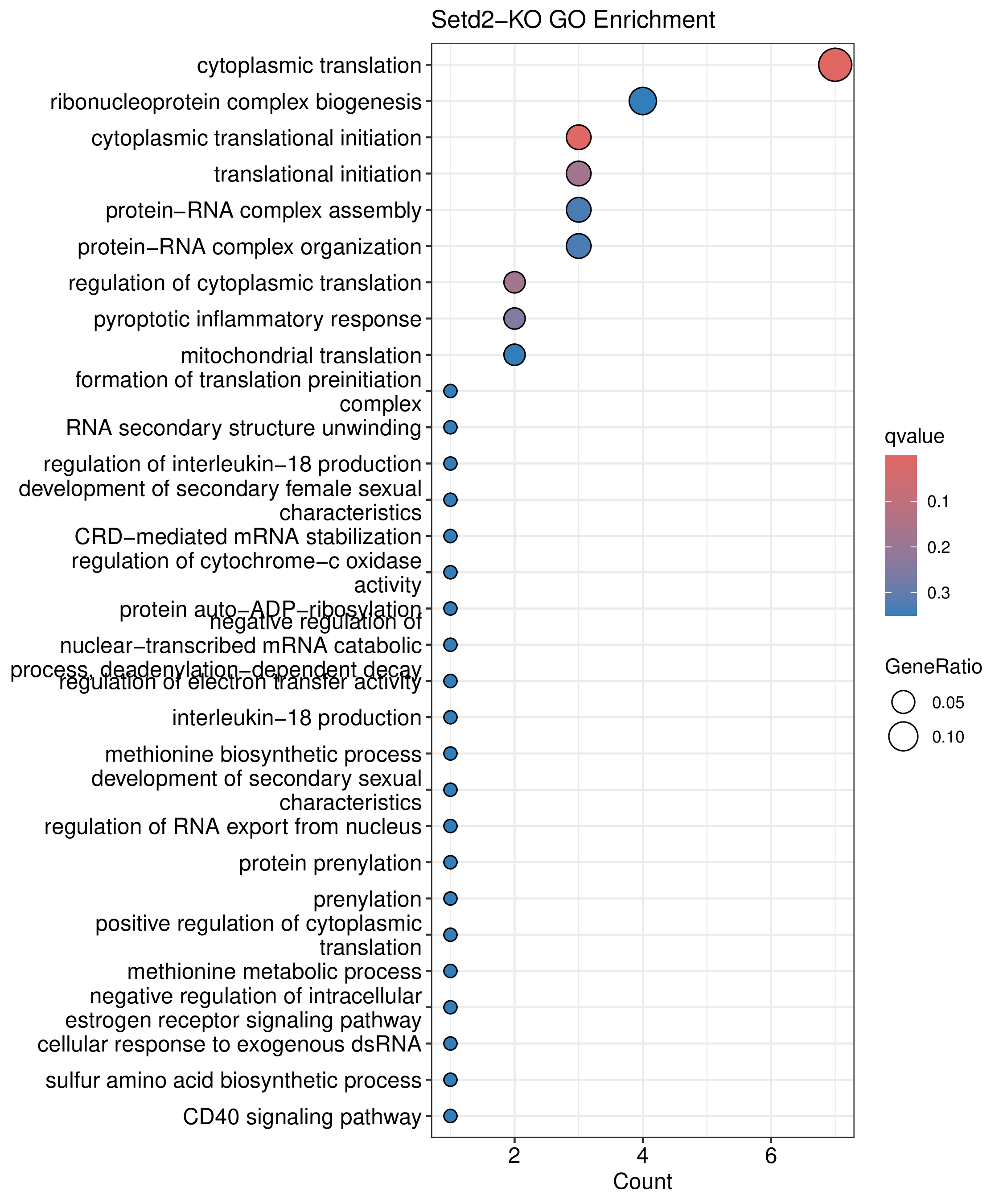
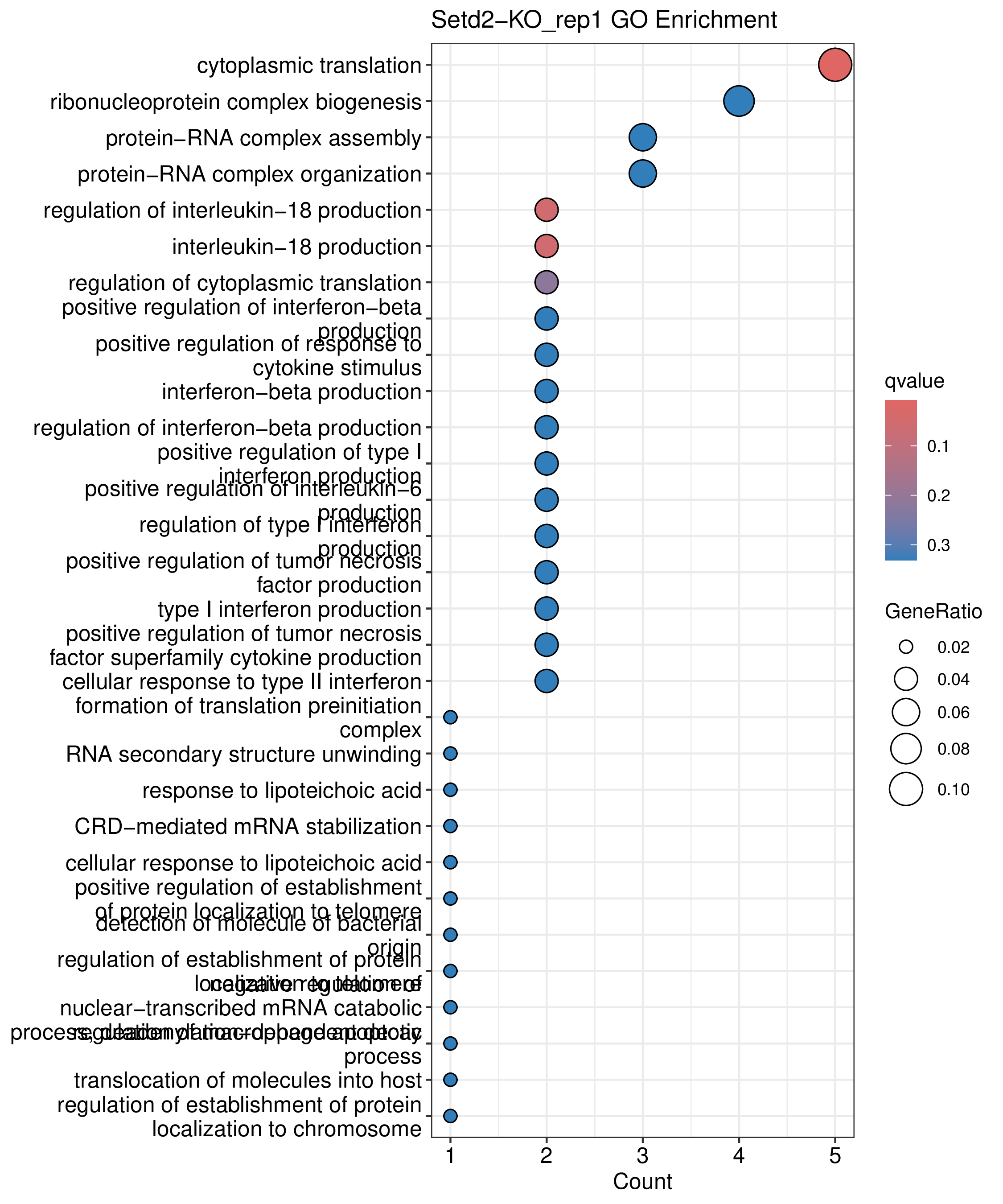
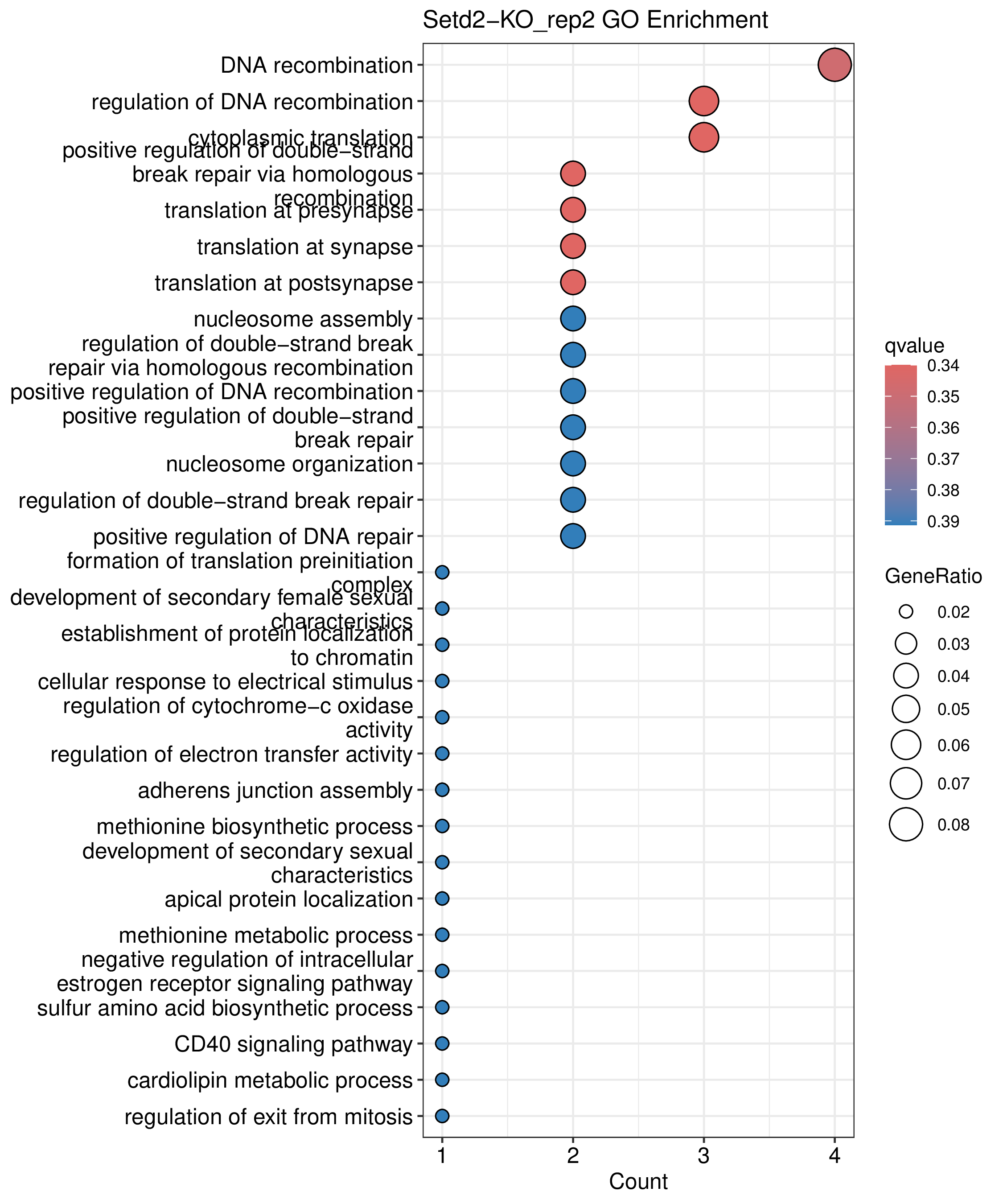
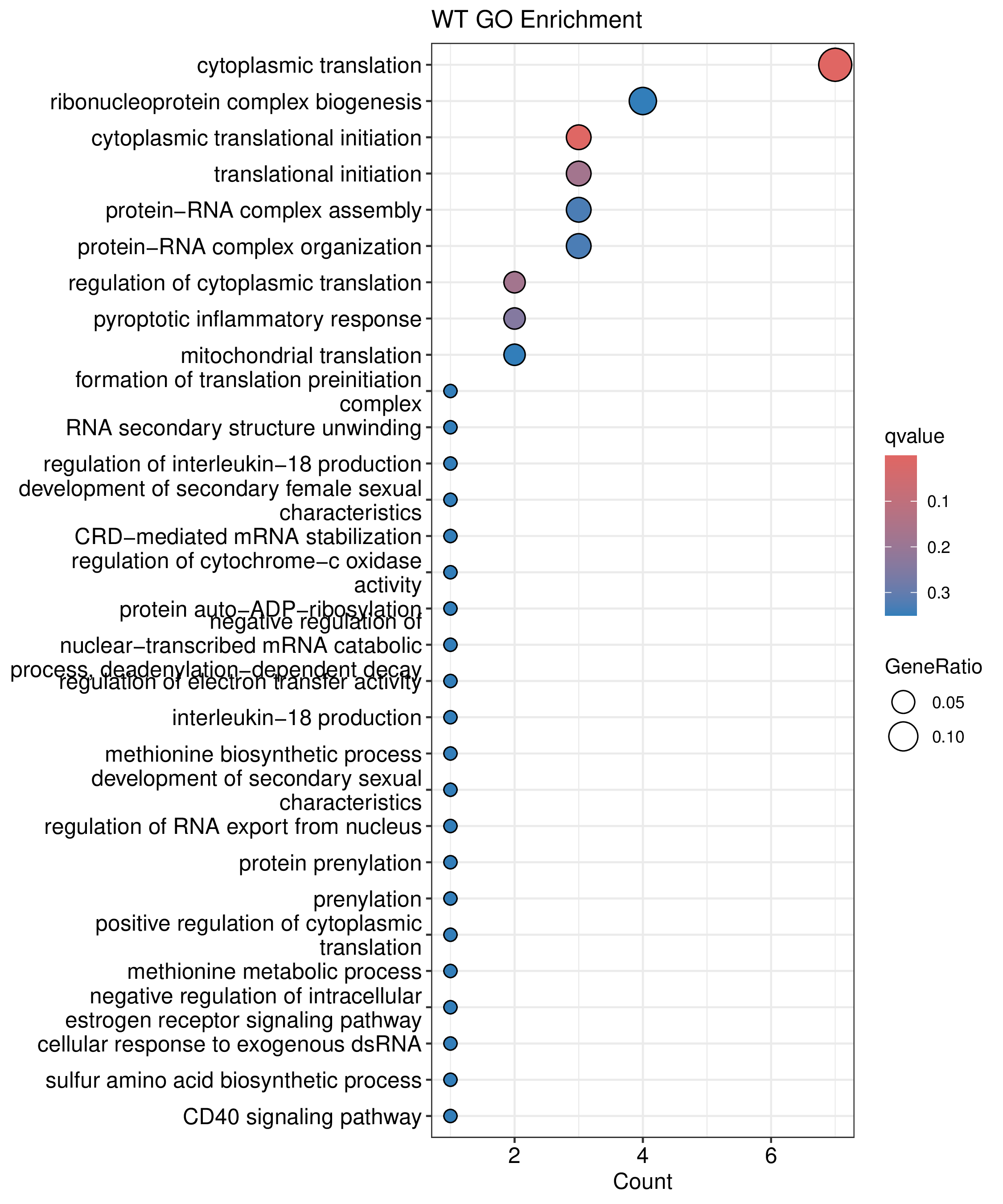
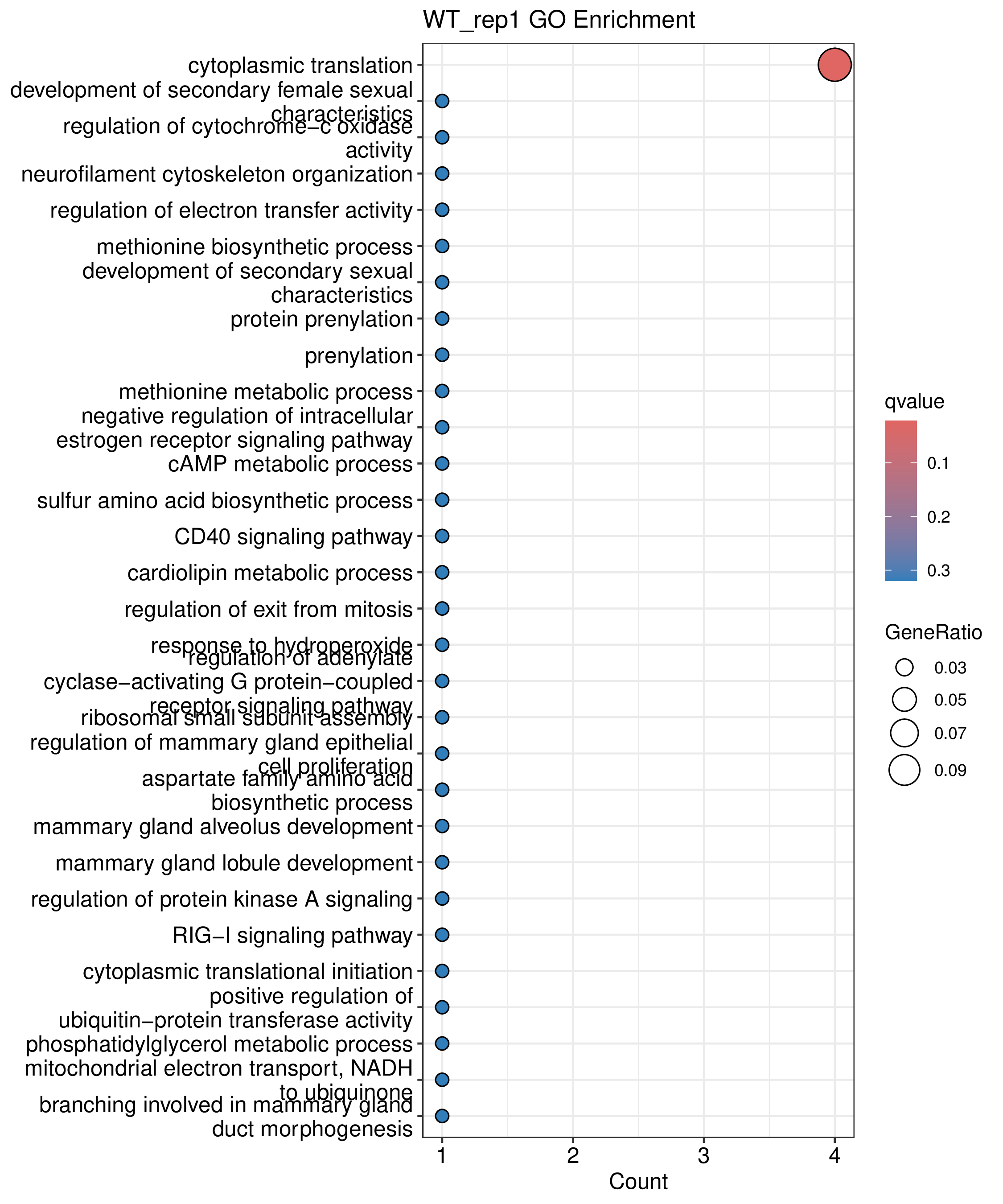
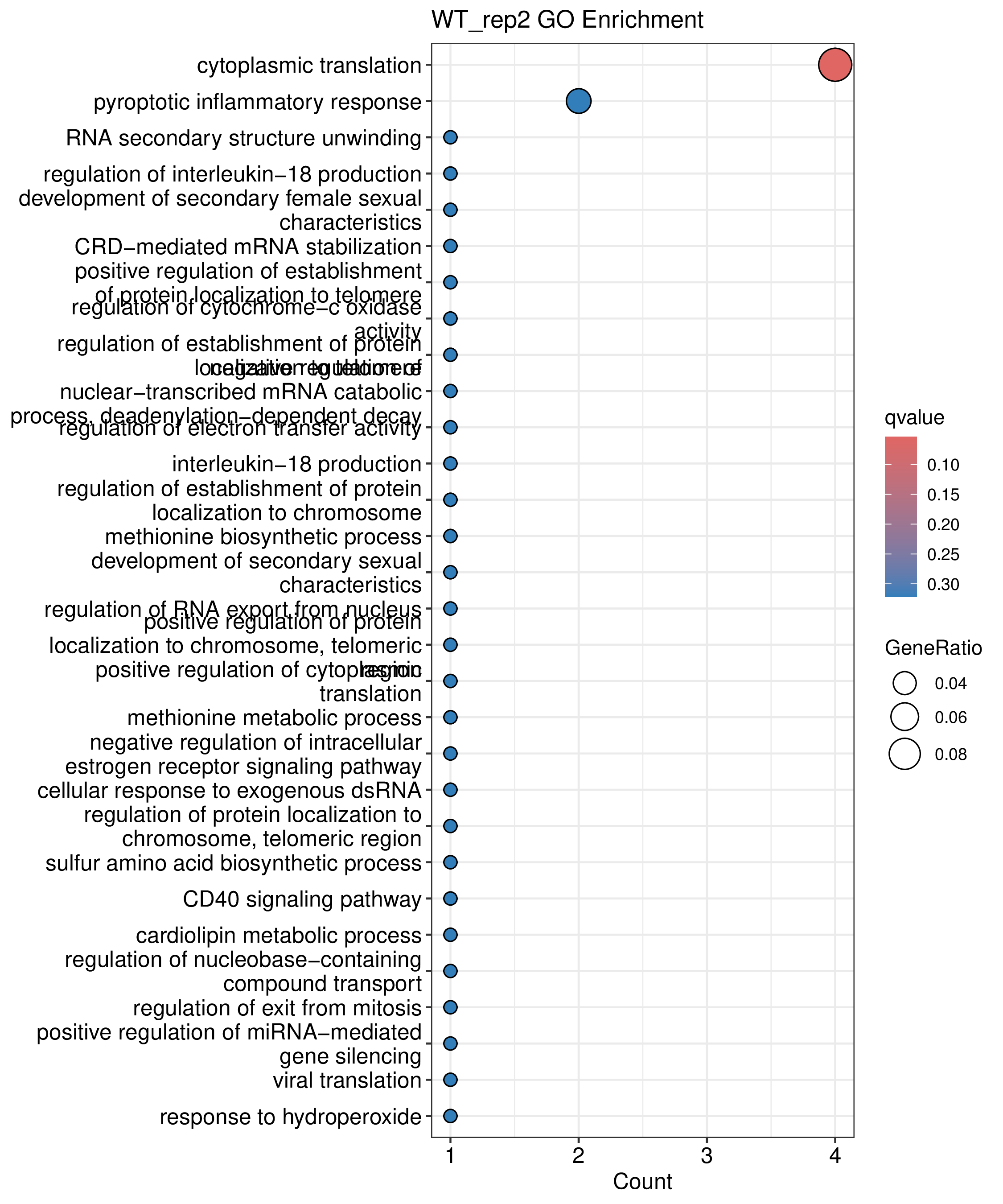
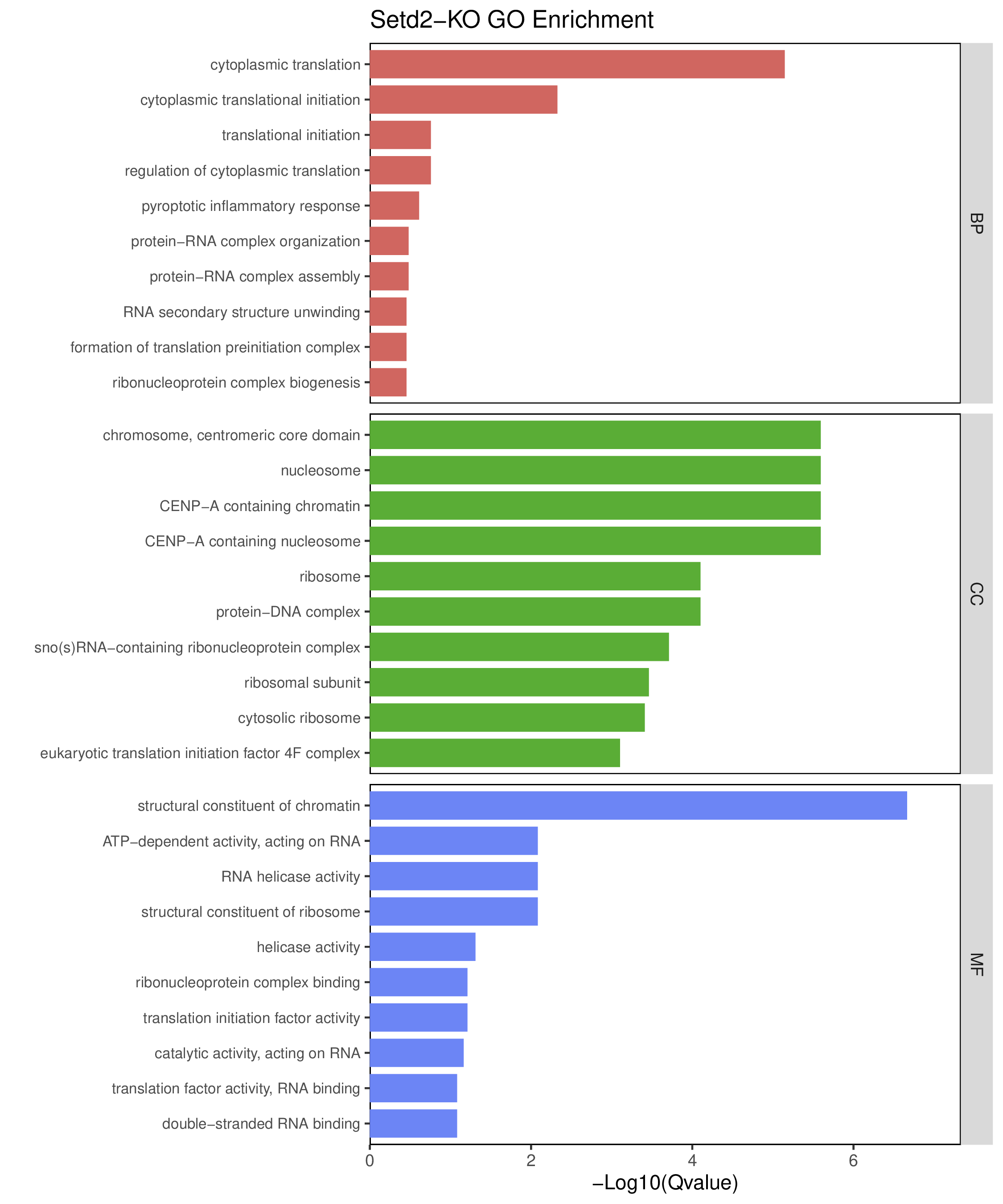
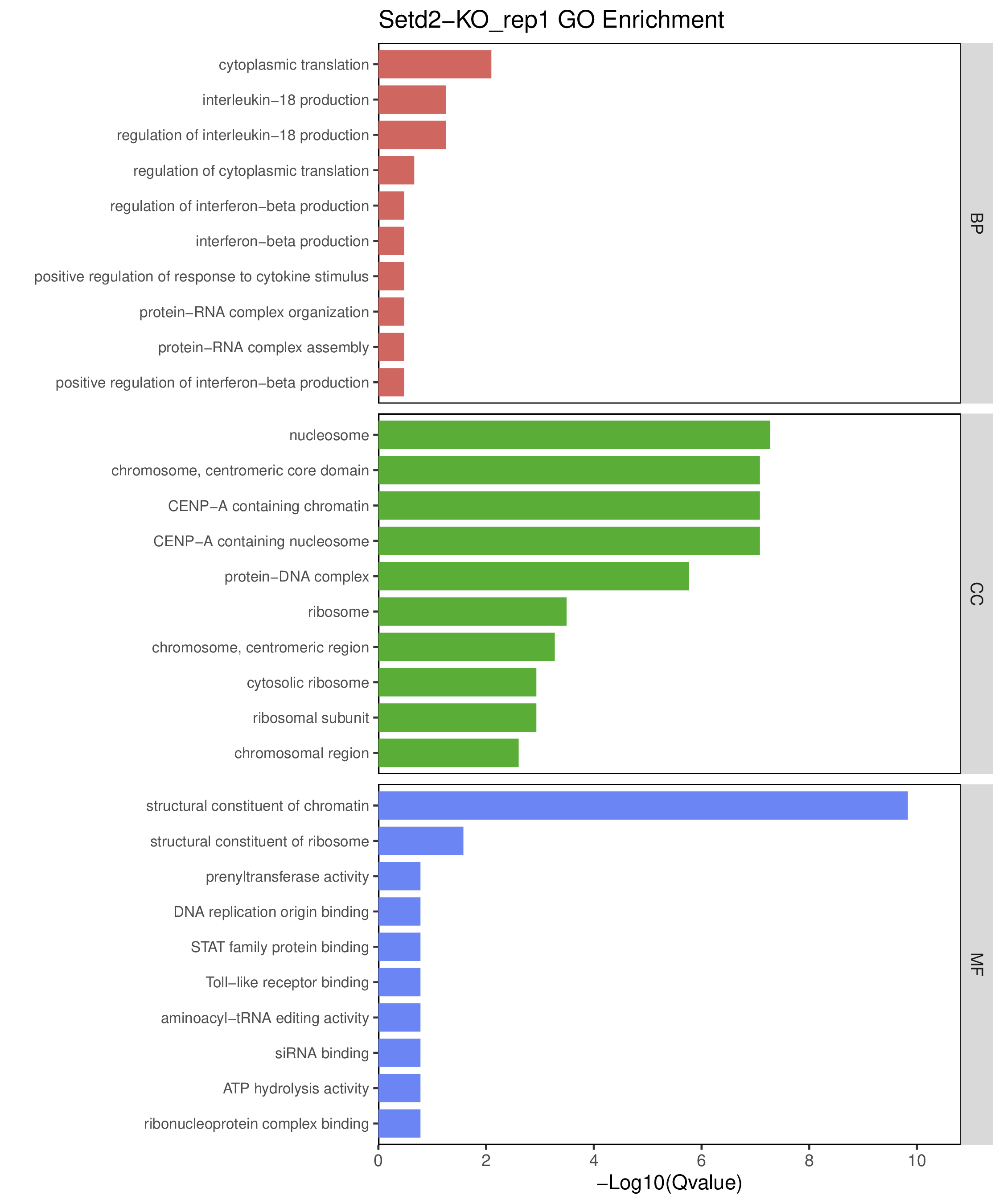
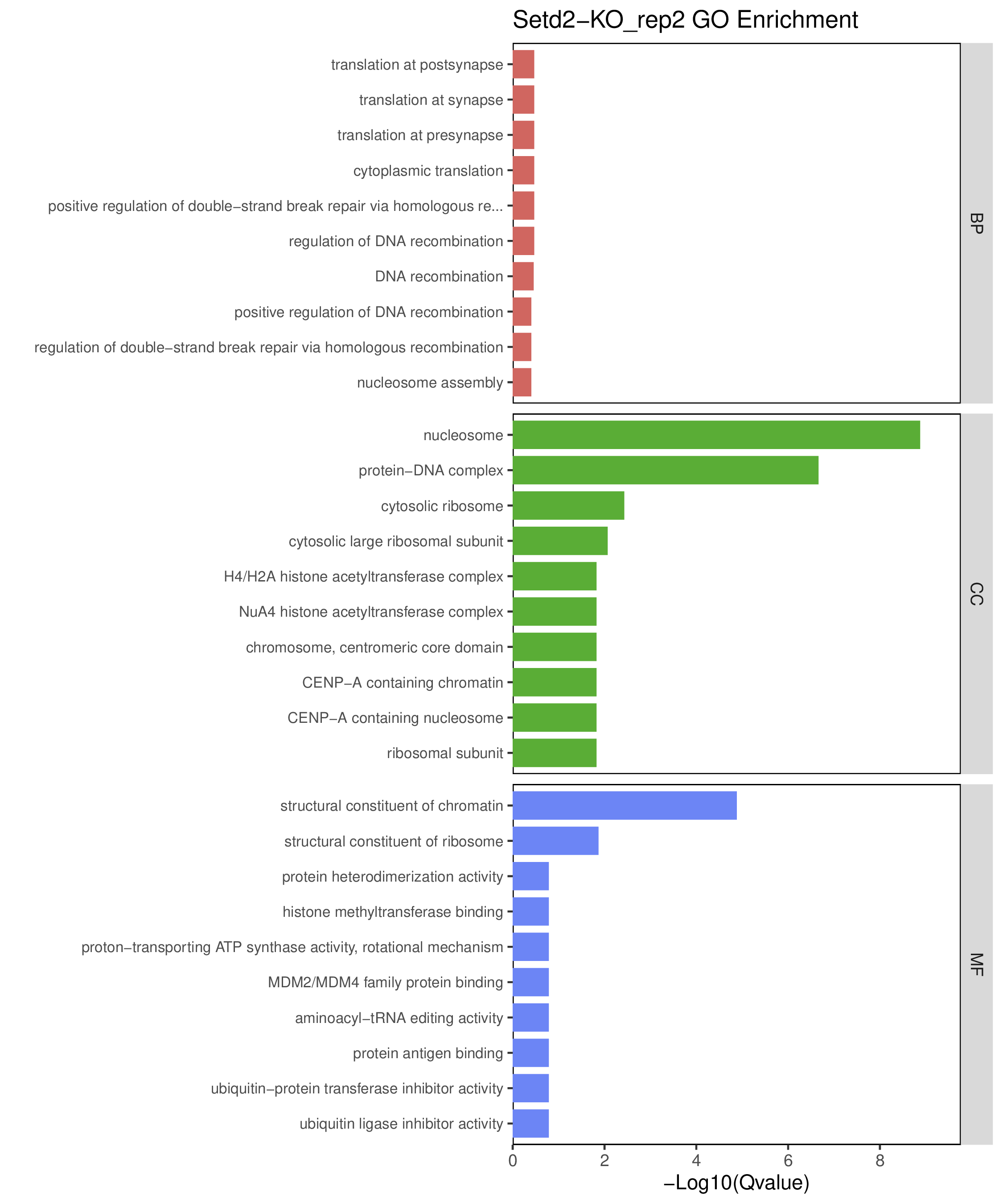
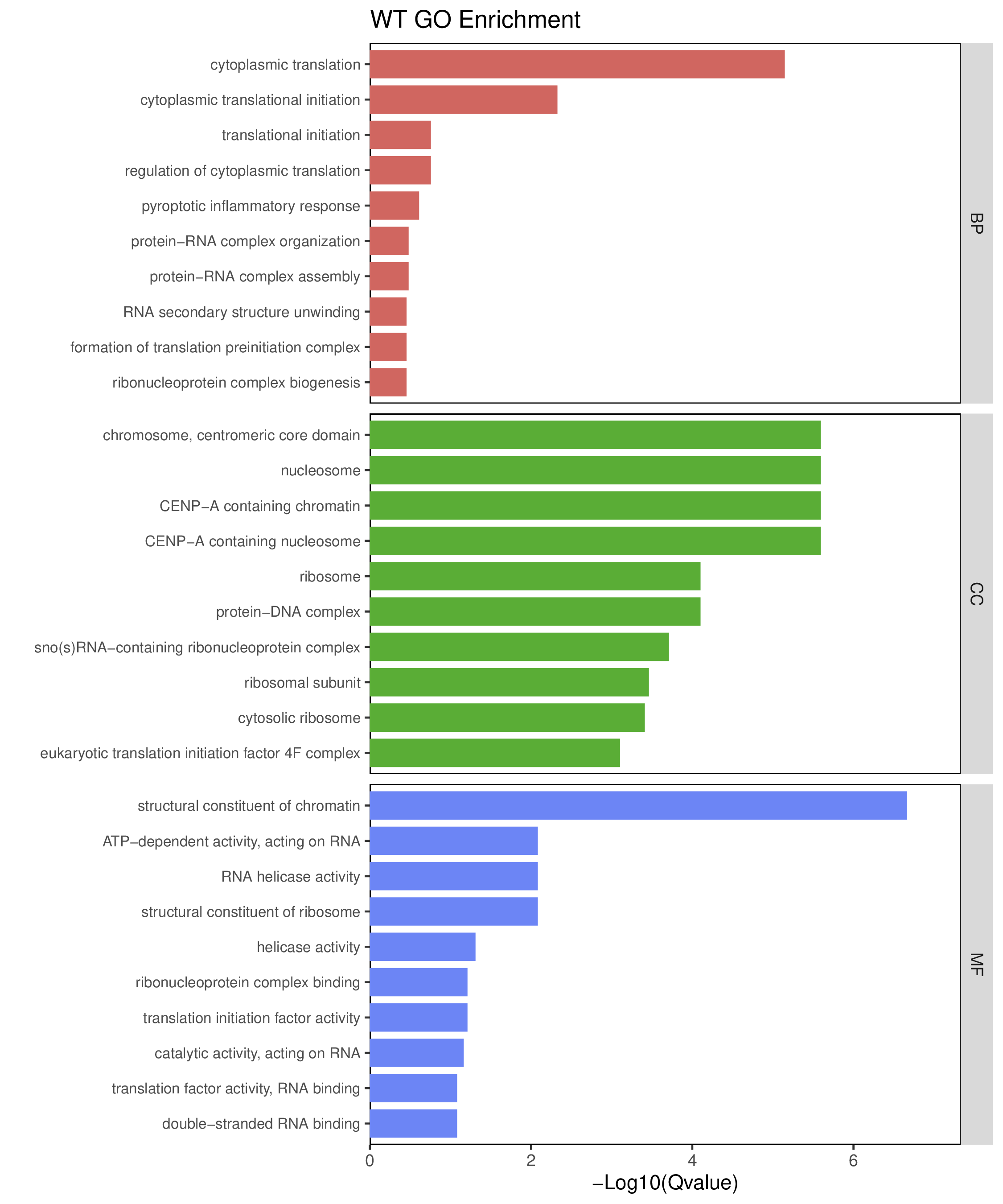
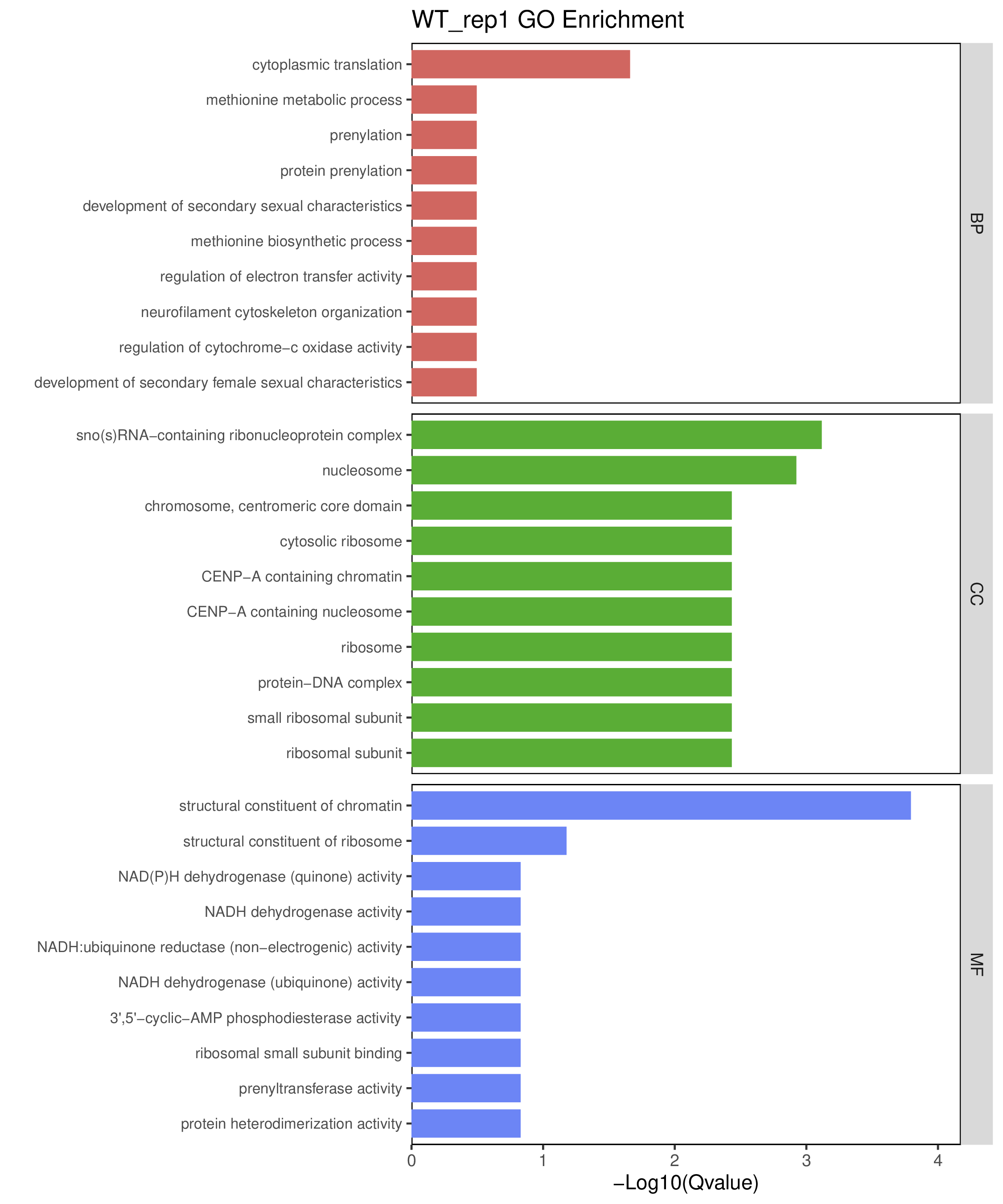
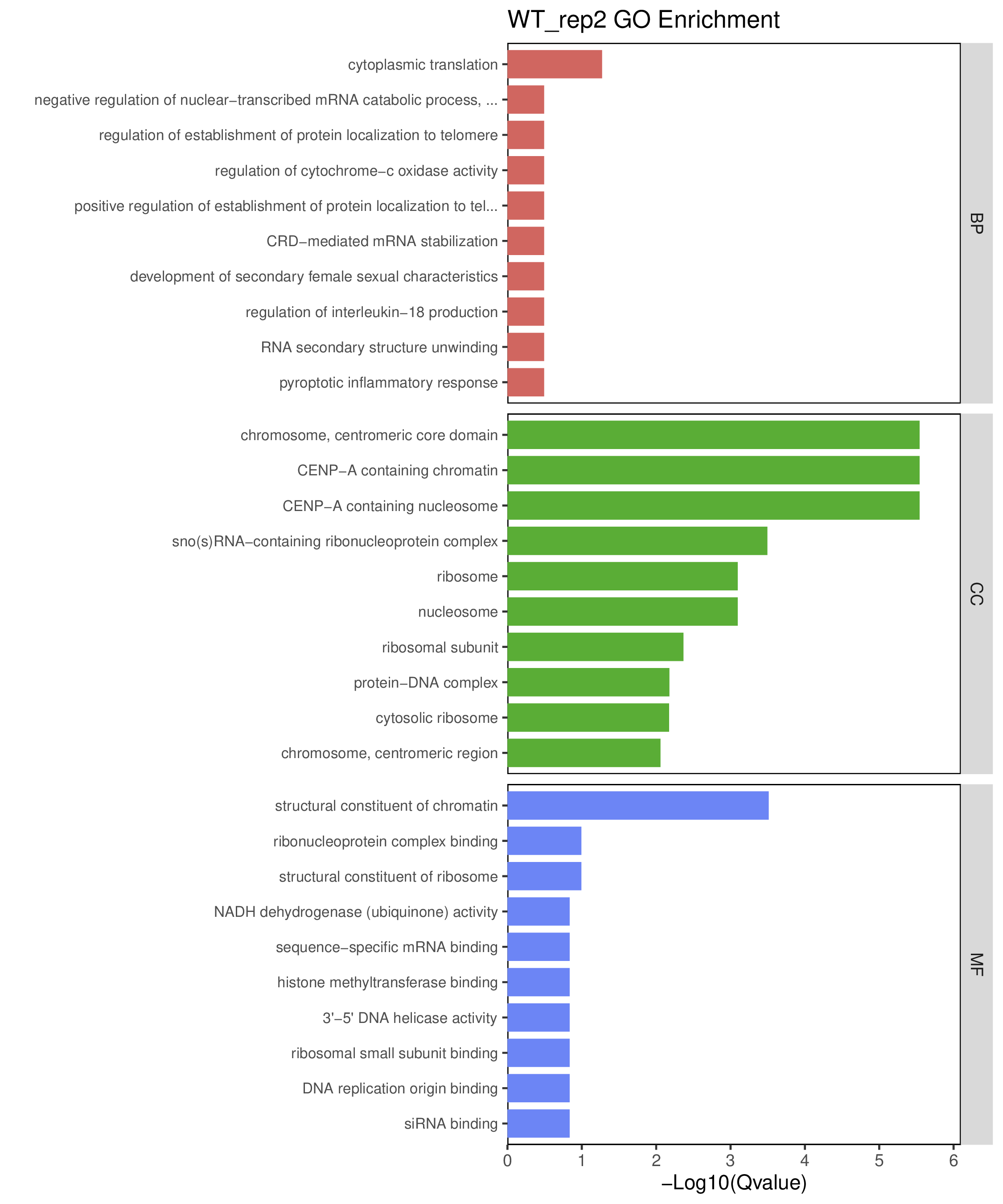
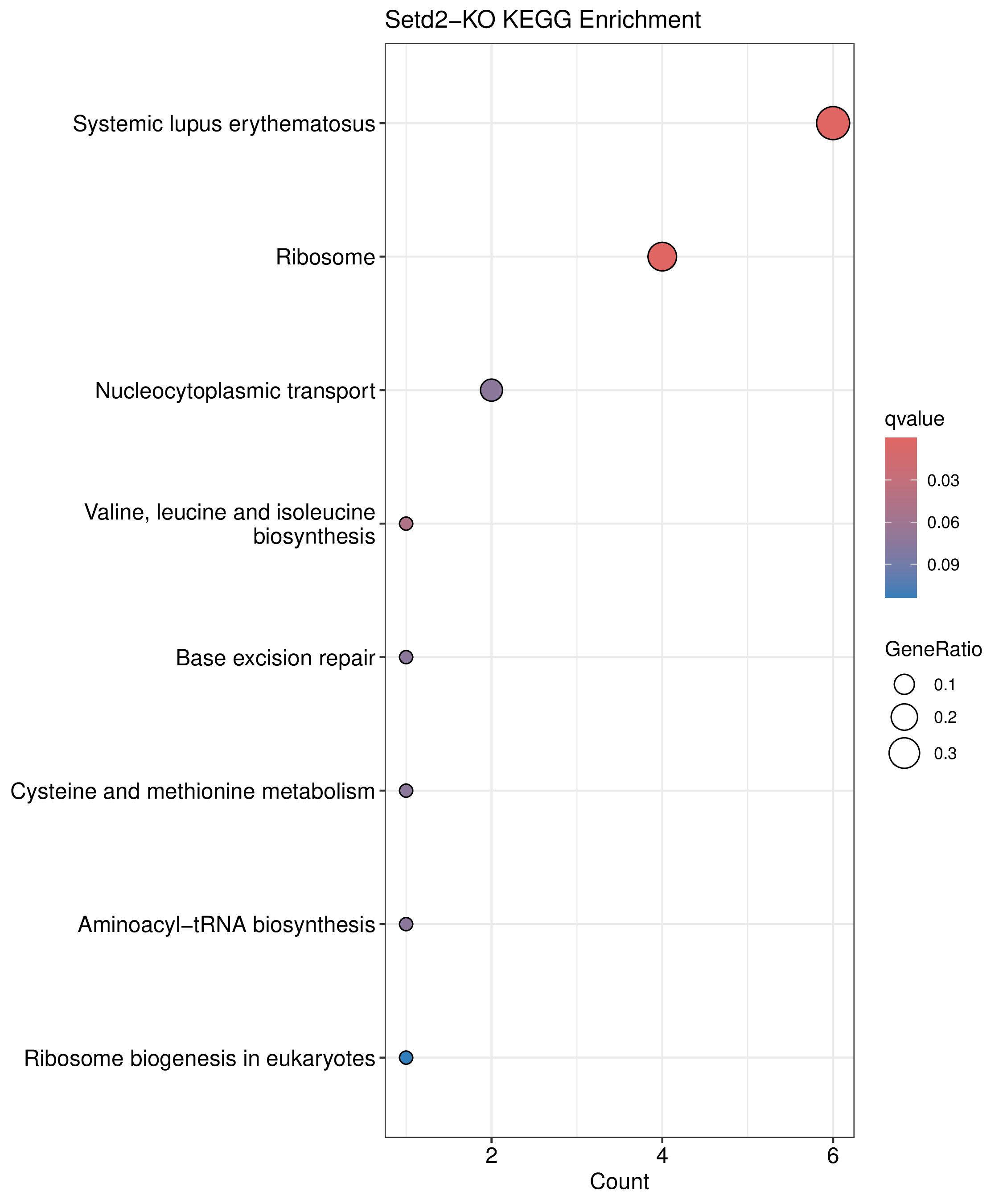
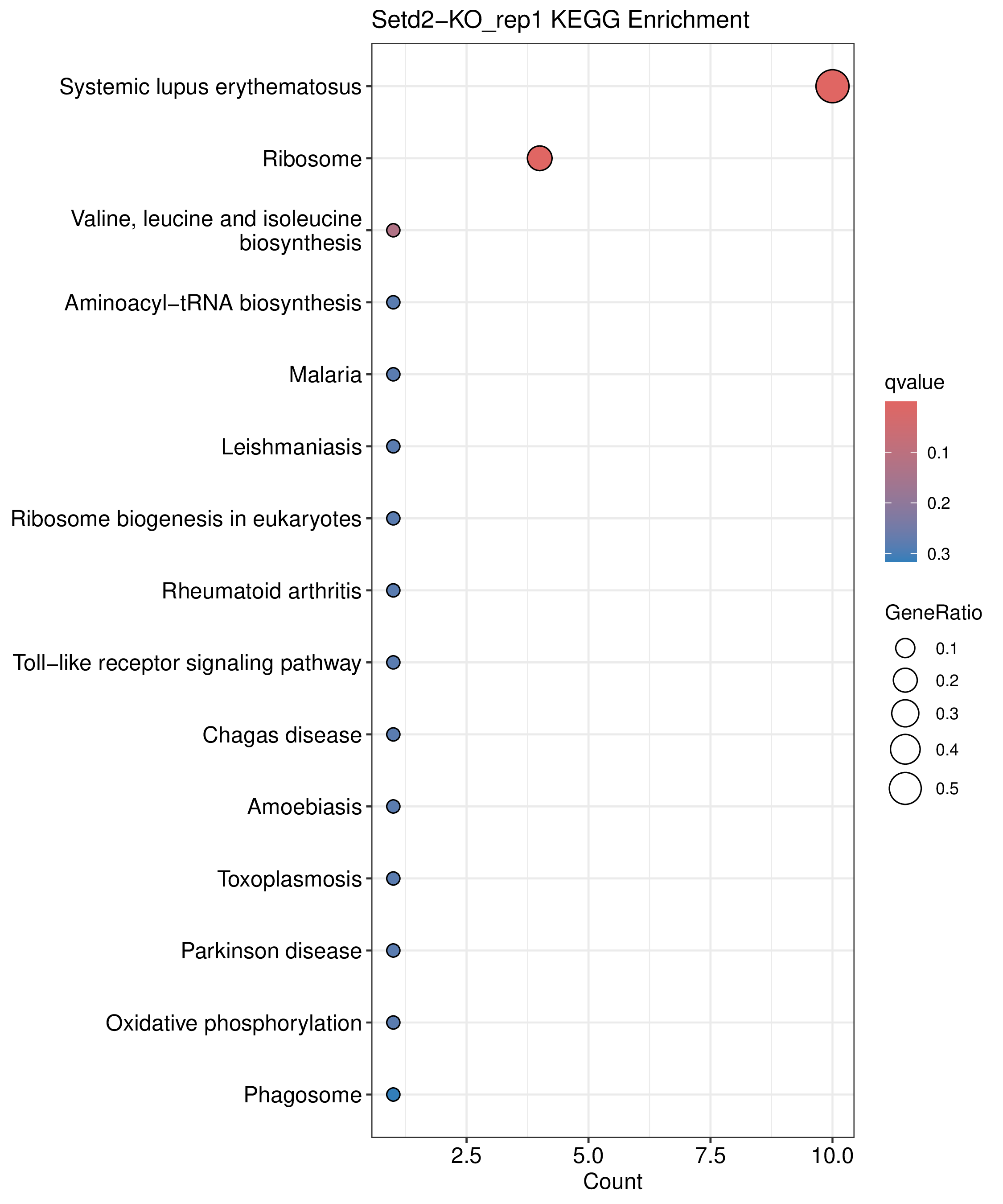
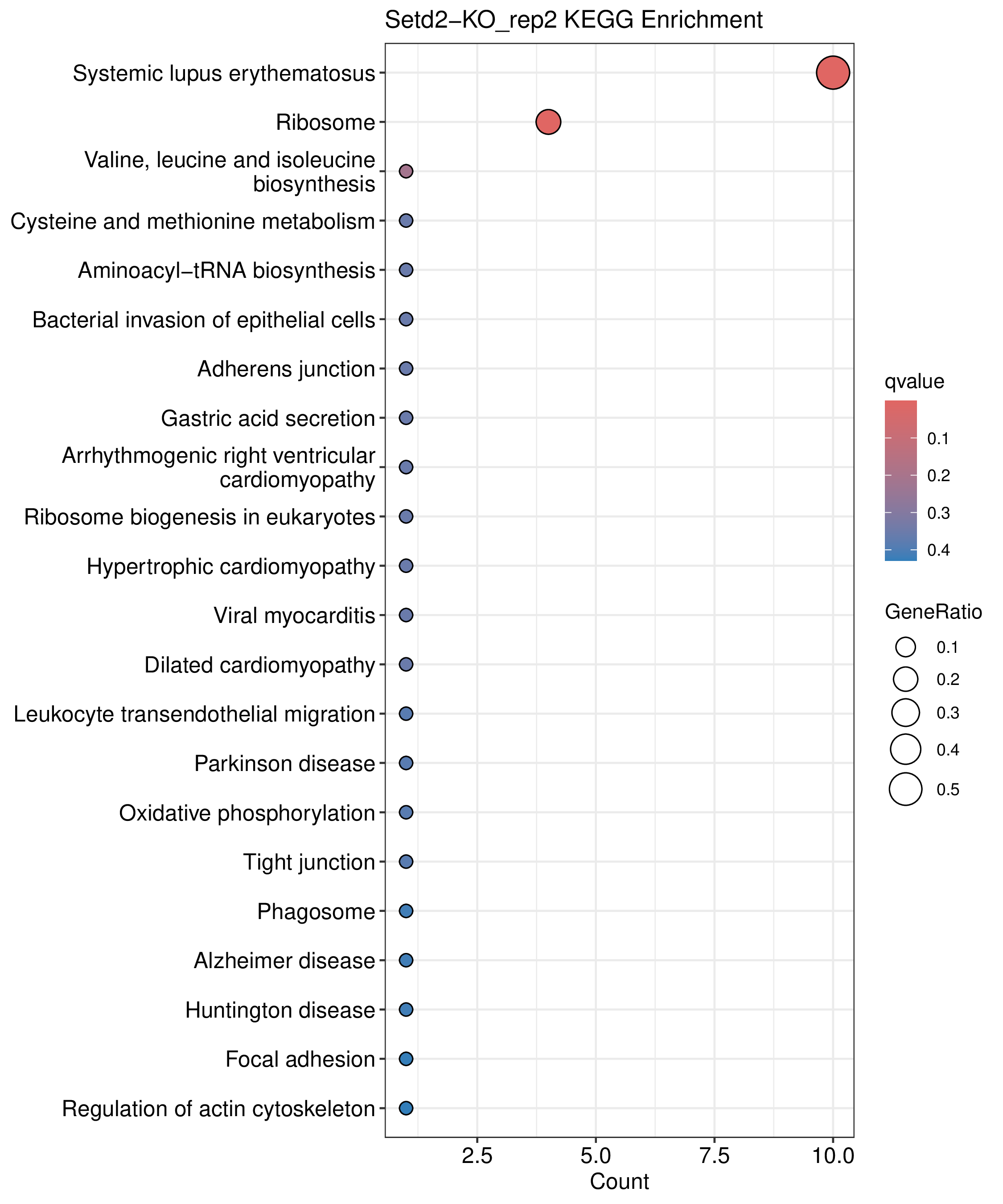
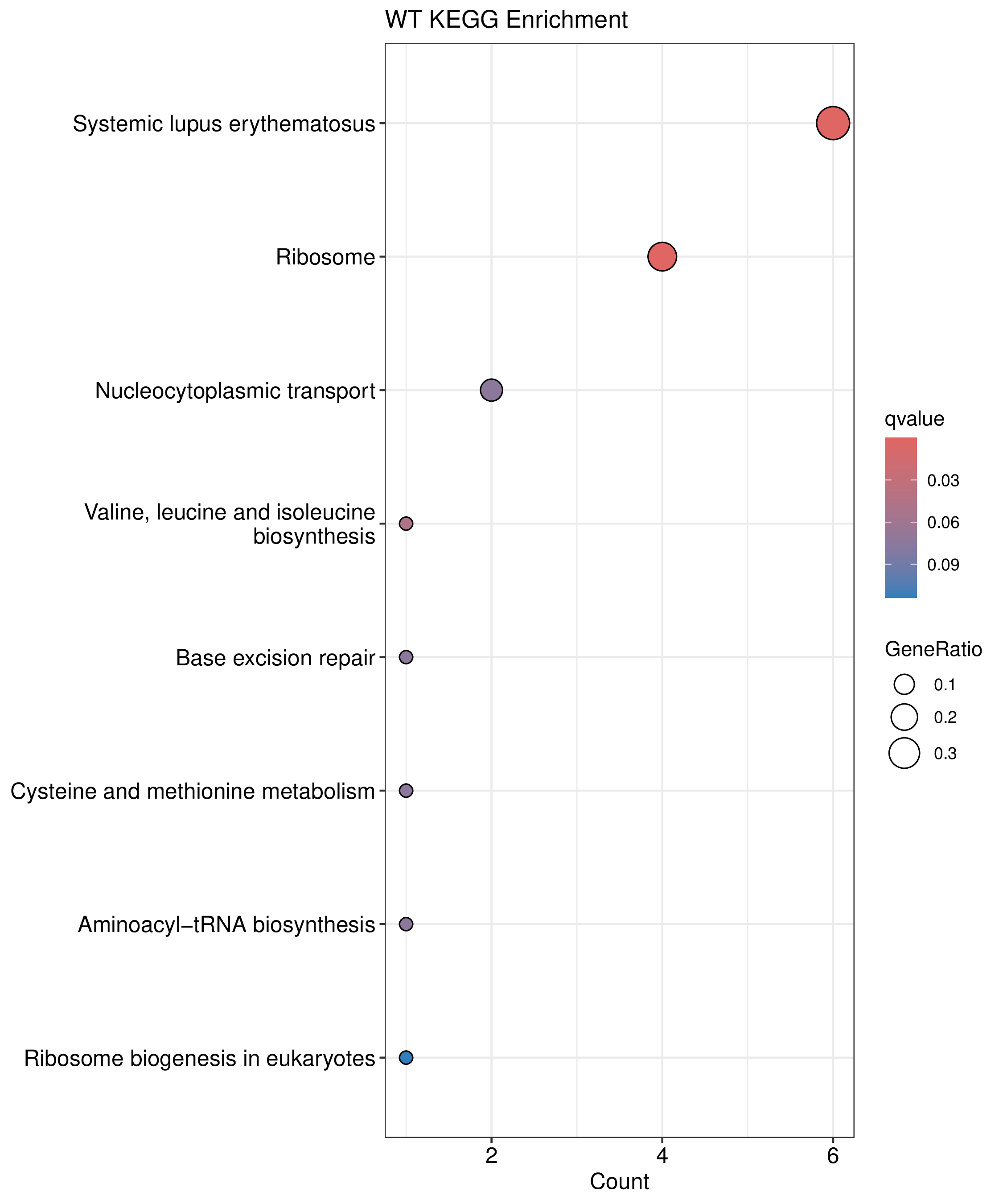
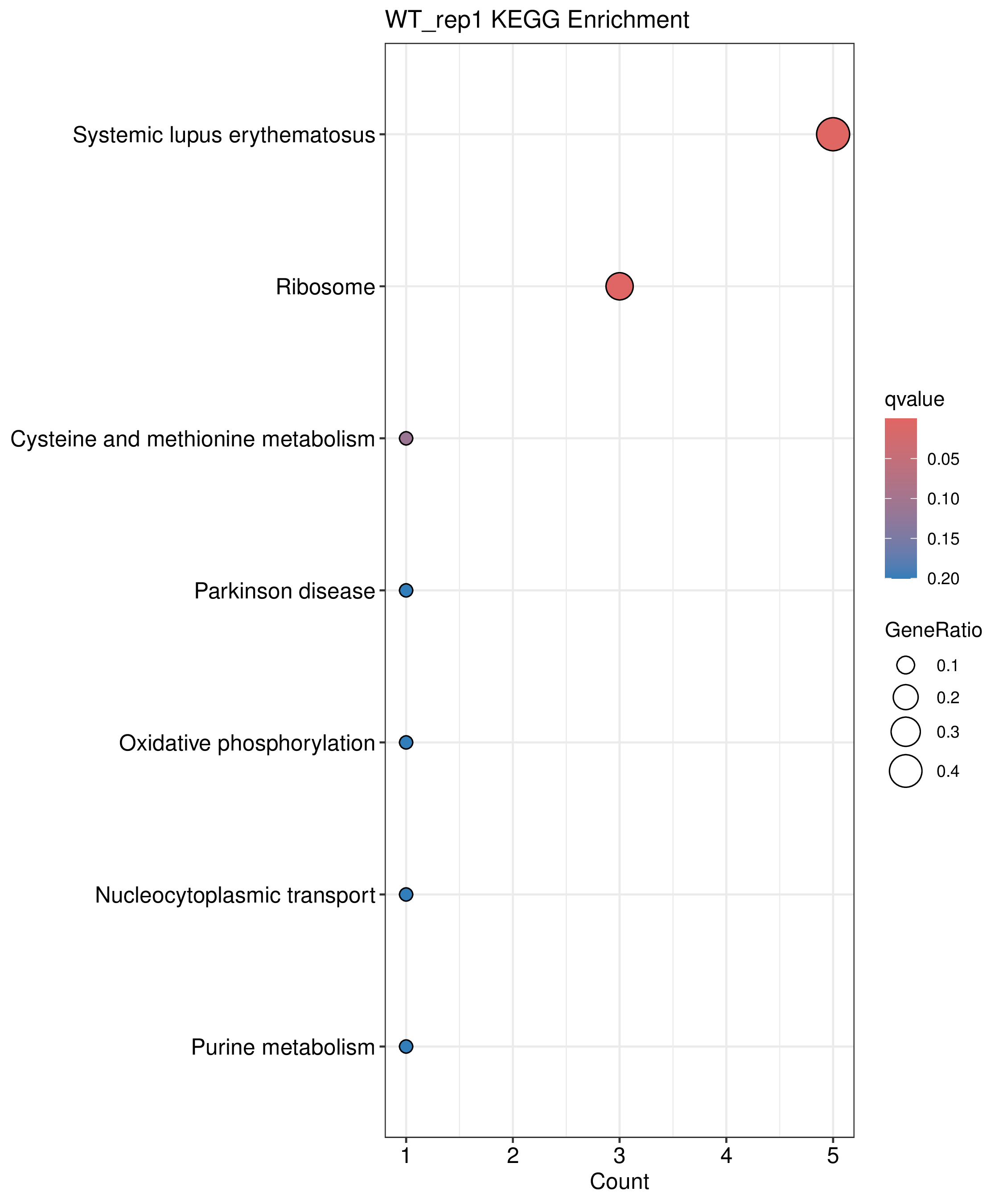
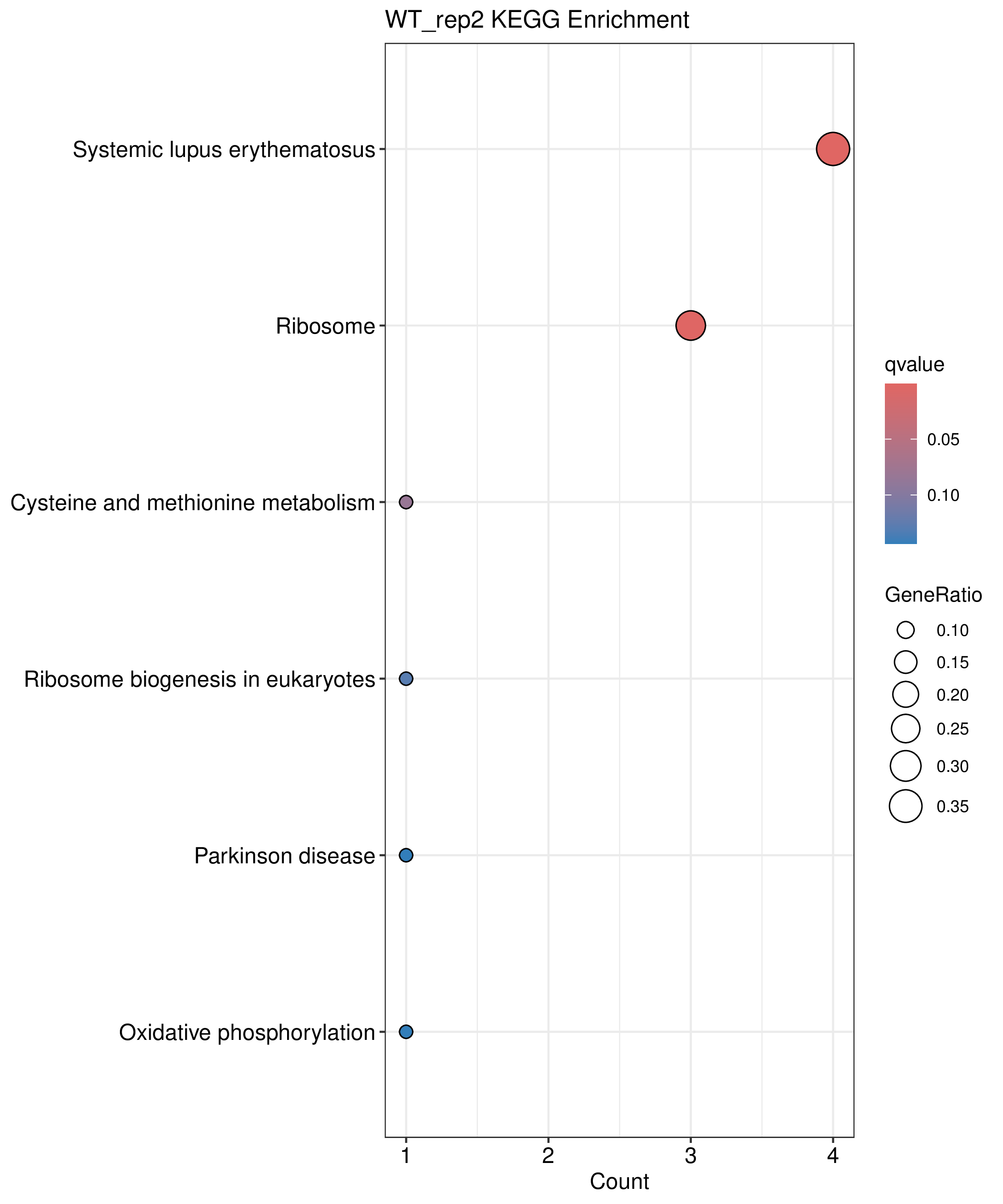
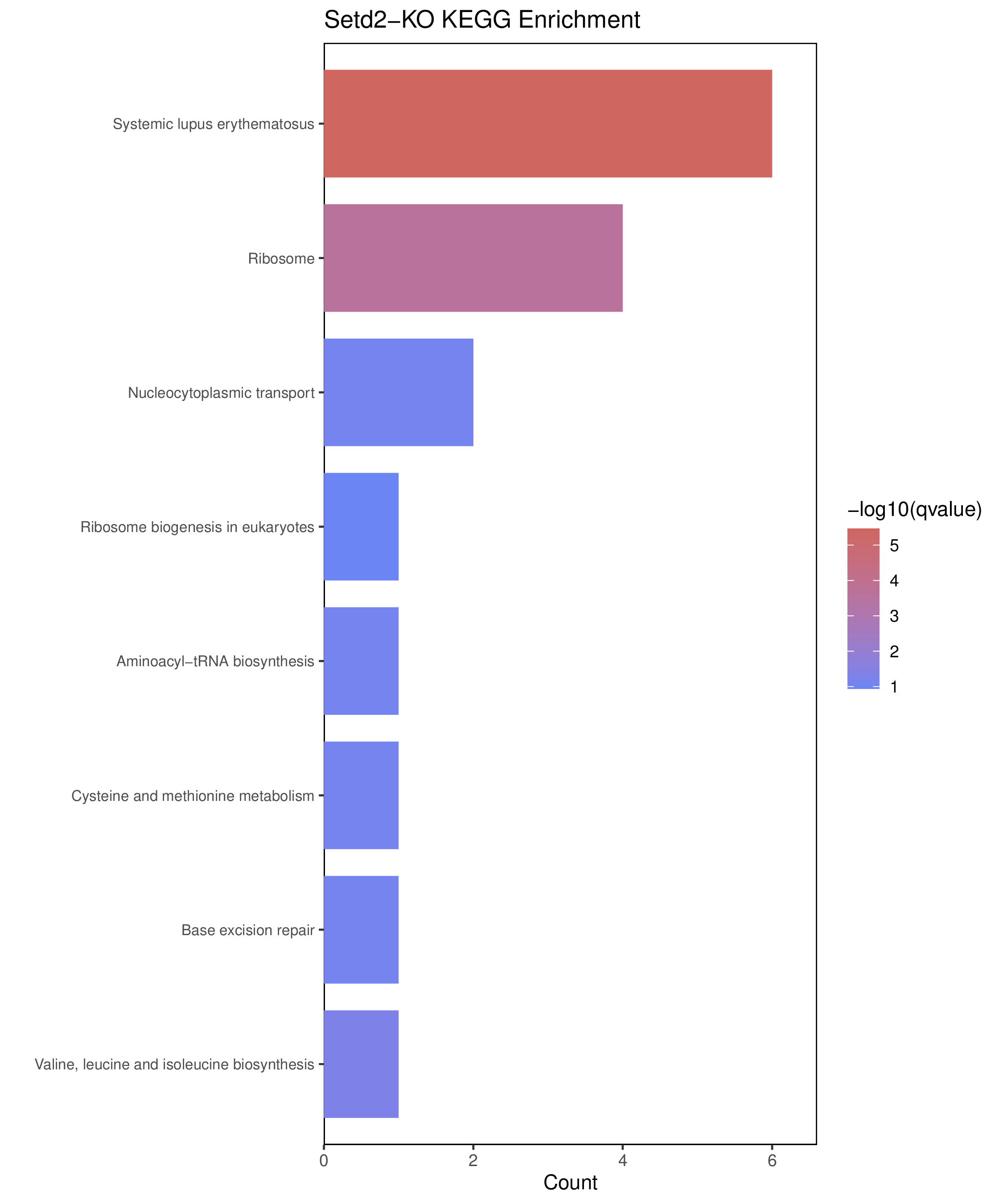
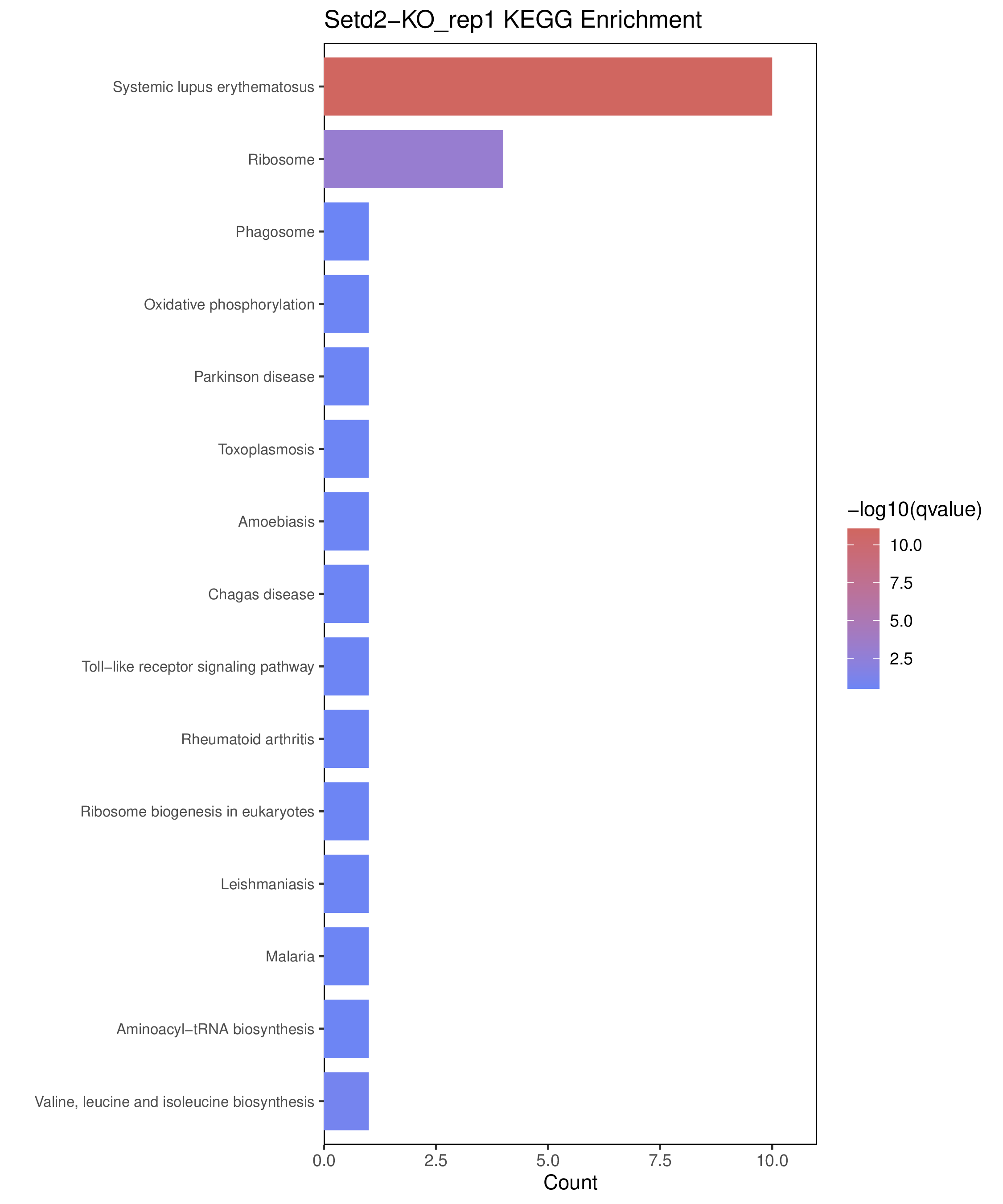
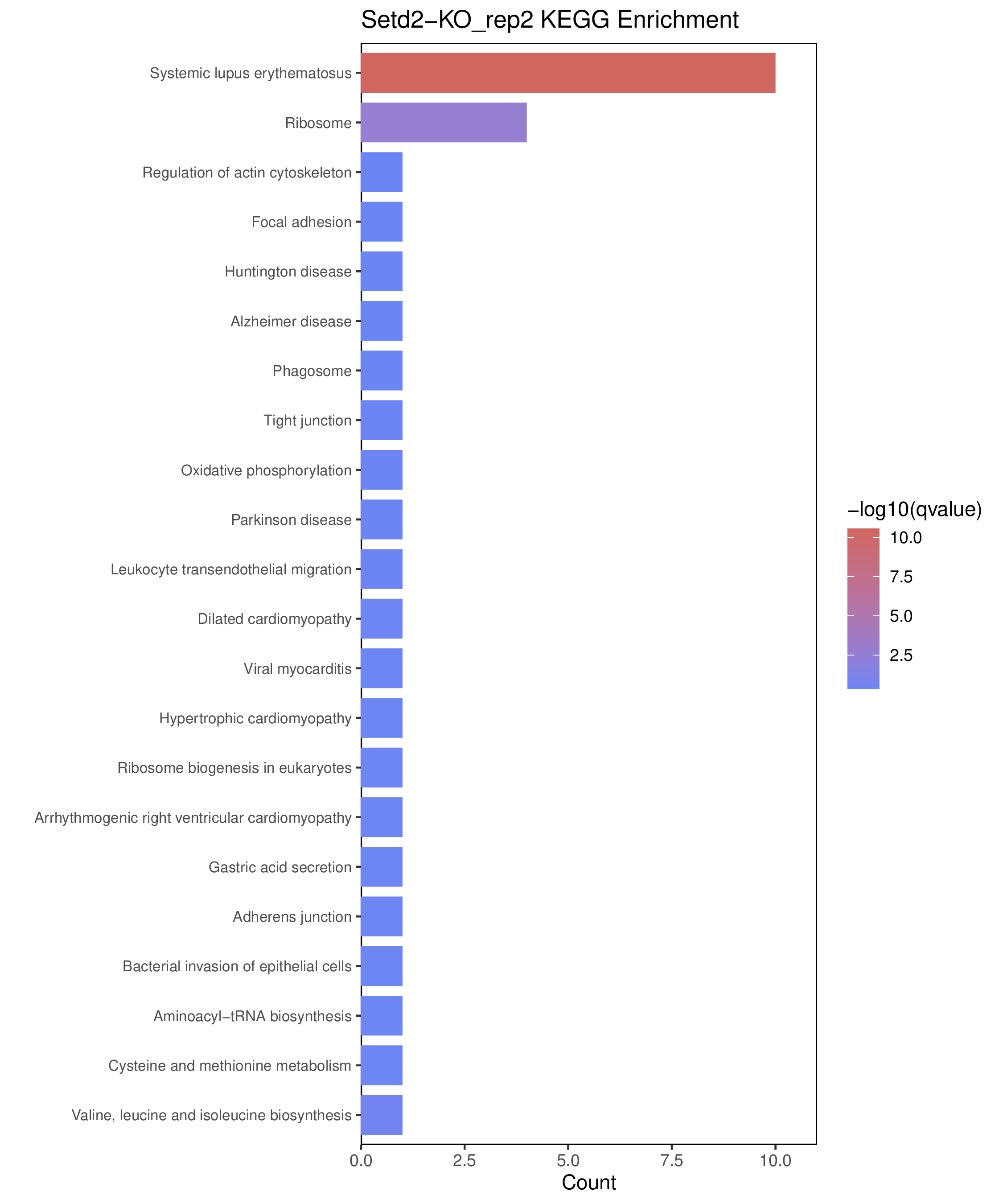
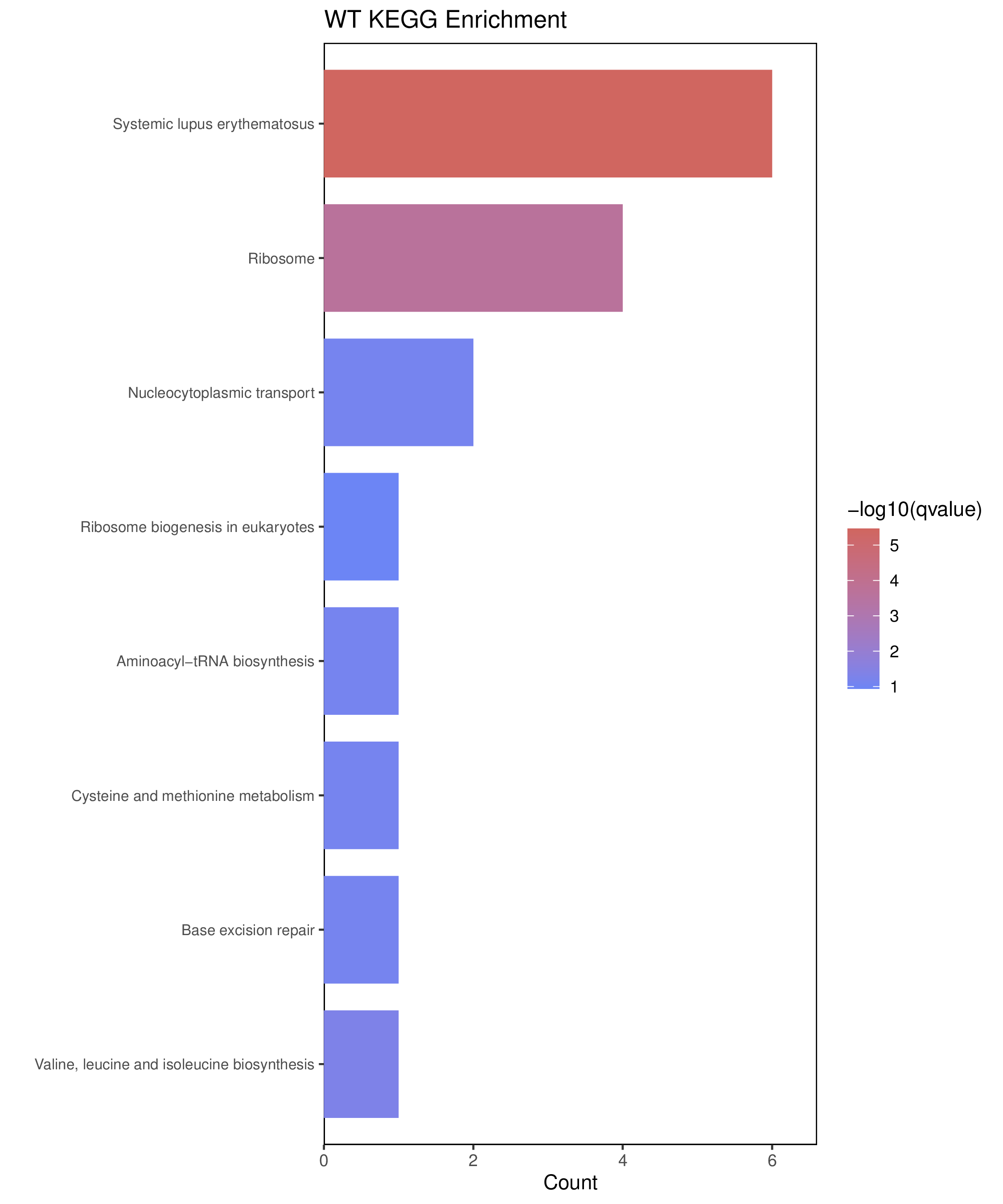
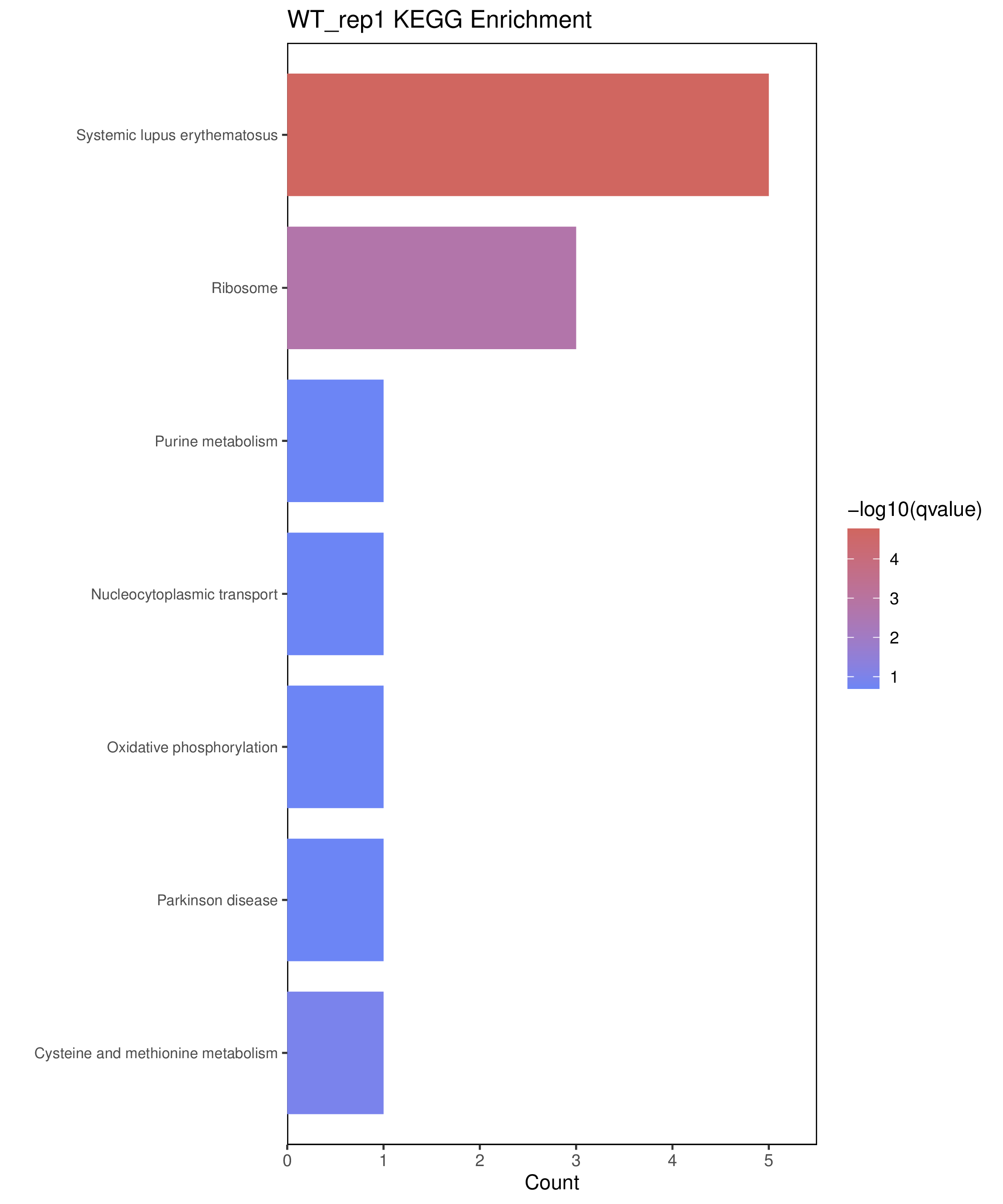
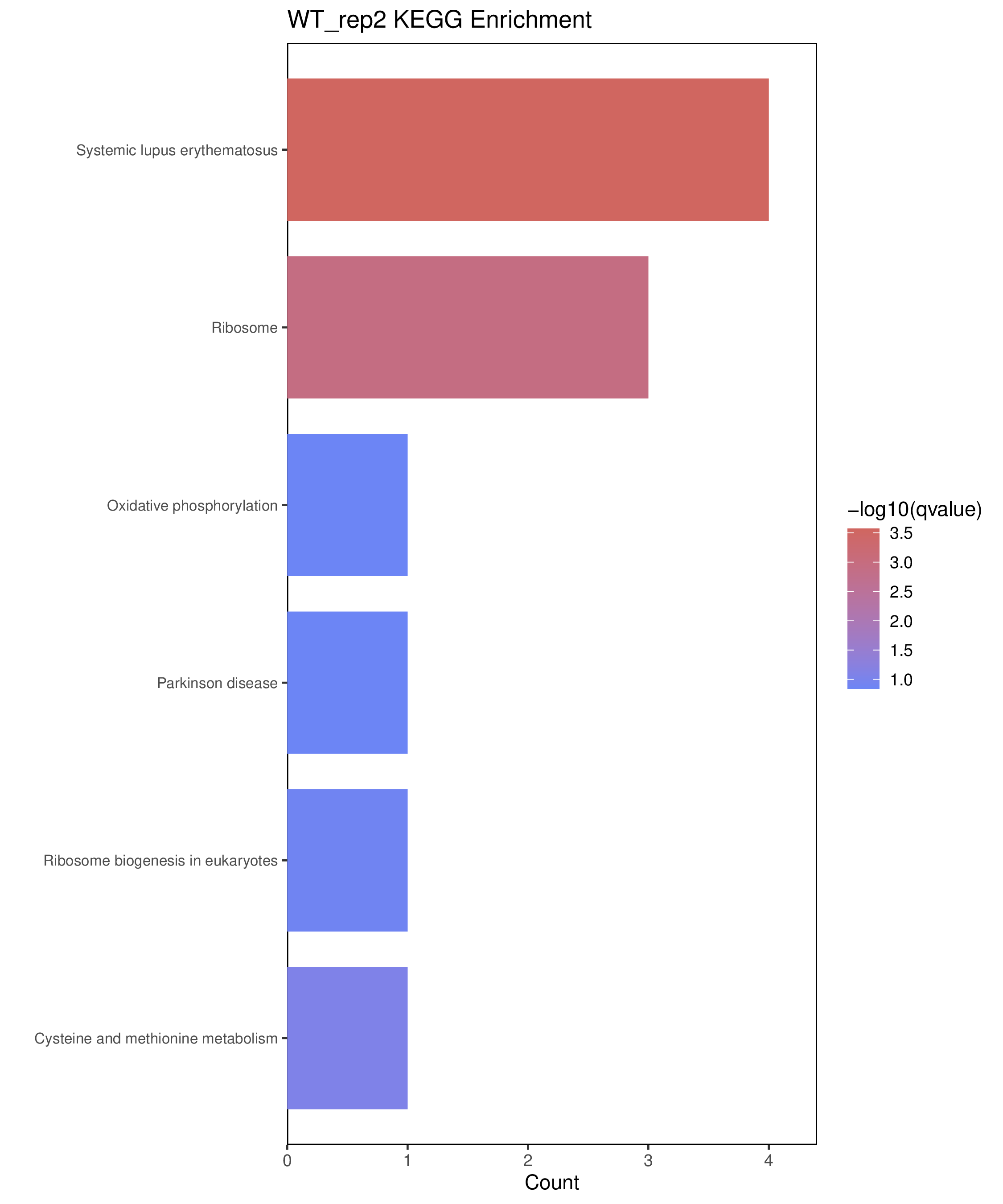

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}